Clear Sky Science · it
Allenamento a basso consumo di memoria per reti di registrazione di immagini cerebrali 3D usando PatchMorph
Capire molti esami cerebrali
La ricerca cerebrale moderna si basa sul confronto di scansioni 3D provenienti da molte persone e animali, ma ogni immagine cerebrale differisce lievemente in dimensioni, forma e risoluzione. Allinearle con precisione, senza ricorrere a computer enormi, è una sfida importante. Questo articolo presenta PatchMorph, un nuovo metodo per allineare grandi immagini cerebrali 3D che riduce drasticamente l’uso della memoria mantenendo o addirittura migliorando la precisione, aprendo la strada allo studio di dataset cerebrali più ampi e ricchi.
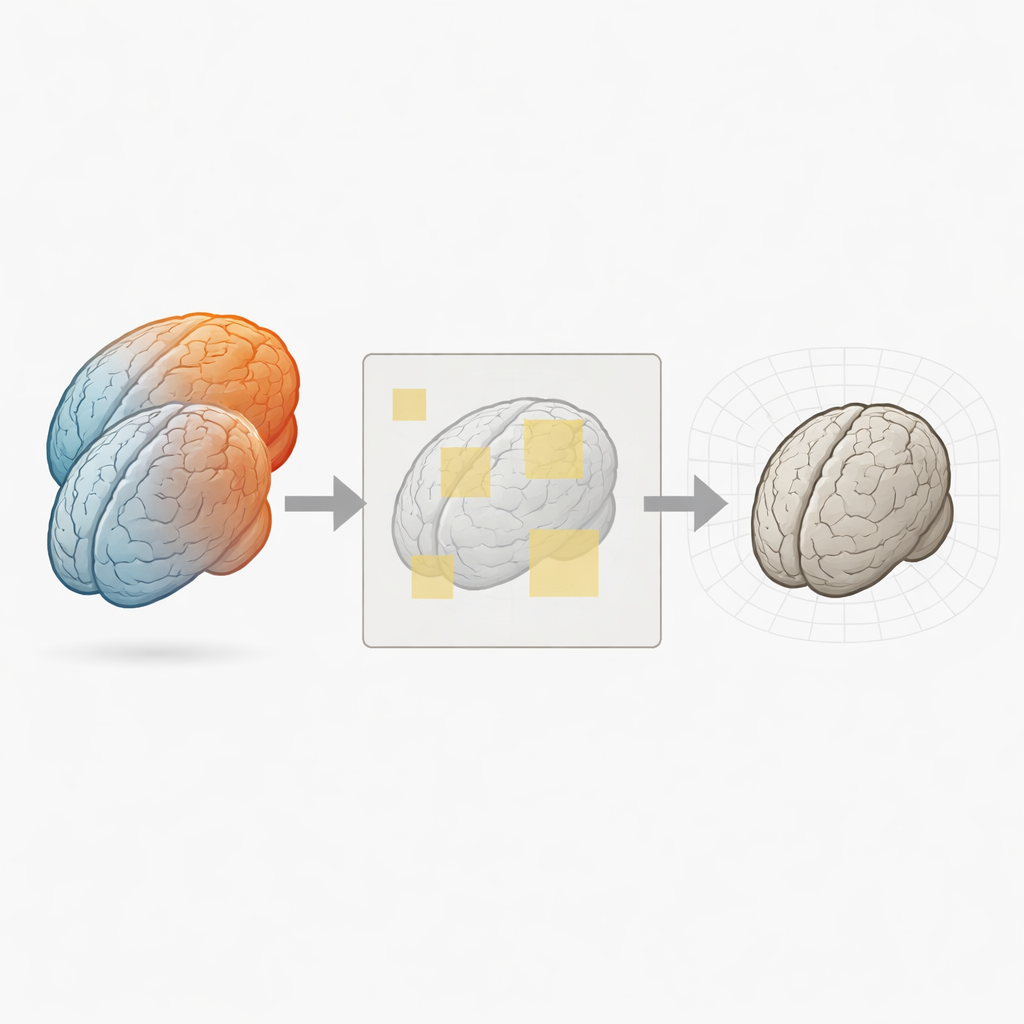
Perché allineare i cervelli è così difficile
Per confrontare i cervelli, gli scienziati prima «registrano» un’immagine 3D su un’altra, deformando un volume in modo che le strutture corrispondenti si sovrappongano. Gli strumenti classici lo fanno regolando lentamente un campo di deformazione finché non viene massimizzata una misura di similarità tra le immagini. Metodi più recenti basati sul deep learning, come VoxelMorph, imparano a prevedere questa deformazione in un unico passaggio, rendendo la registrazione molto più rapida. Tuttavia, la maggior parte di queste reti si aspetta che entrambe le immagini di input condividano la stessa griglia e risoluzione e spesso deve elaborare interi volumi 3D in una sola volta. Con l’aumento delle dimensioni delle immagini e della complessità dei modelli, la memoria grafica richiesta esplode rapidamente, costringendo i ricercatori a ridurre, ritagliare o pre-elaborare pesantemente i dati.
Esaminare i cervelli a pezzi
PatchMorph affronta questo collo di bottiglia evitando di caricare mai i volumi 3D completi nella rete in una sola volta. Invece, opera su piccoli «pezzi» 3D (patch) campionati in uno spazio di riferimento condiviso che copre l’immagine fissa. A un livello grossolano, il metodo posiziona patch relativamente grandi sull’intero cervello, estrae patch corrispondenti dall’immagine mobile usando trasformazioni di coordinate precise e le inoltra a una rete di registrazione compatta. La rete predice quanto ogni patch debba spostarsi e deformarsi affinché il suo contenuto locale combaci. Le molte predizioni locali vengono quindi ricombinate in un campo di deformazione globale, usando interpolazione liscia in modo che la deformazione dell’intero cervello rimanga continua.
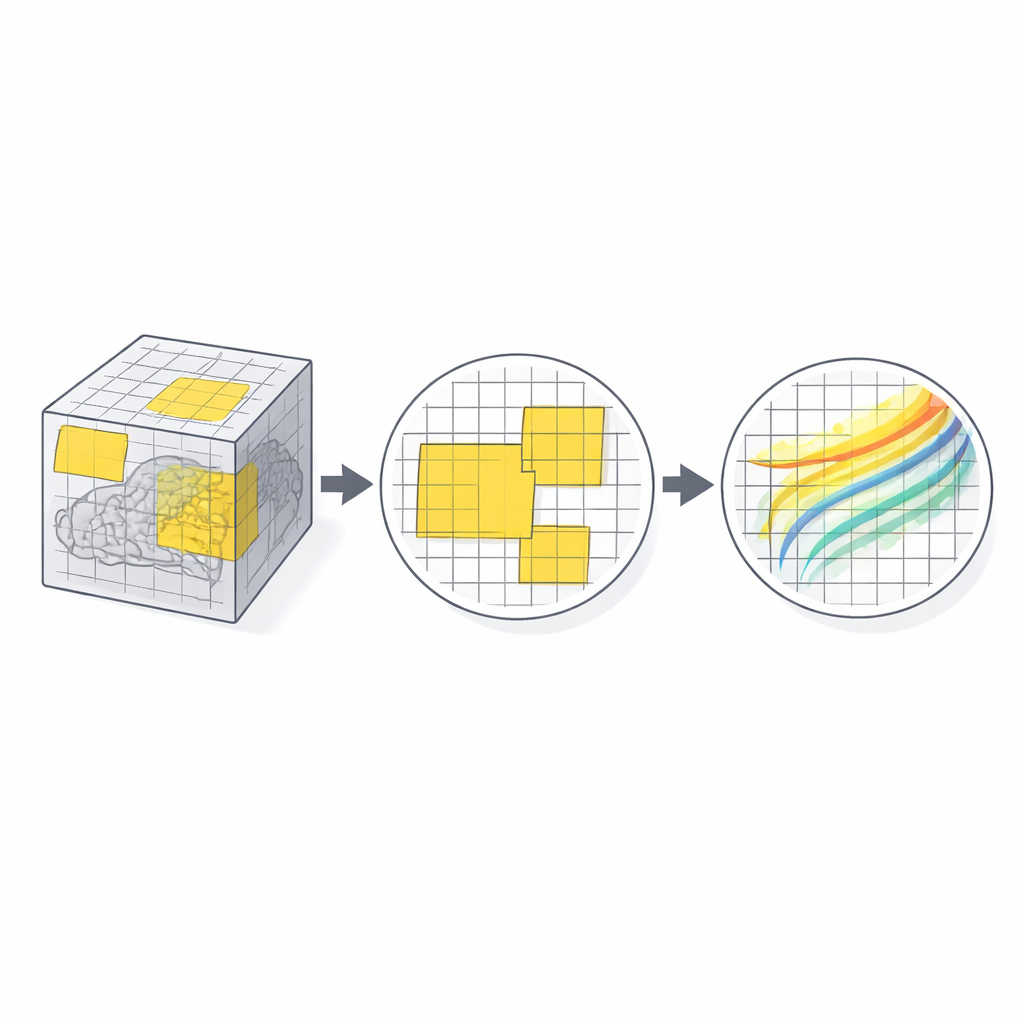
Dalle patch grandi ai dettagli fini
PatchMorph procede su più scale, dal grossolano al fine. Alla prima scala, una patch copre una vasta regione cerebrale a bassa risoluzione, catturando disallineamenti ampi come dimensione o posizione complessive. Alle scale successive, nuove patch «ingrandiscono» sottoregioni delle patch campionate in precedenza, ma mantengono sempre lo stesso numero di voxel per patch in memoria. Ciò significa che le scale più fini aumentano il dettaglio fisico senza incrementare la richiesta di memoria. Le posizioni delle patch ai livelli più fini sono scelte in modo stocastico all’interno delle loro patch genitrici, quindi il metodo non si concentra solo sui centri delle patch ma impara gradualmente ad allineare anche le strutture periferiche. Attraverso le scale, le deformazioni stimate vengono accumulate in un unico campo globale, perfezionato passo dopo passo ma sempre coerente spazialmente.
Lavorare con dati cerebrali reali
Gli autori hanno testato PatchMorph su due dataset impegnativi: scansioni T1 umane dal progetto MindBoggle e immagini cerebrali di marmoset ad alta risoluzione acquisite con microscopia a due fotoni seriale. Queste immagini differiscono per dimensione degli array, orientamento e talvolta spaziatura dei voxel—condizioni che mettono in difficoltà le reti convenzionali. PatchMorph ha eguagliato o superato i metodi di registrazione deep learning all’avanguardia in termini di sovrapposizione tra regioni cerebrali etichettate, mantenendo al contempo tassi molto bassi di errori topologici (pieghe irrealistiche nel campo di deformazione). Crucialmente, durante l’addestramento con backbone basati su transformer, PatchMorph ha ridotto la memoria necessaria per immagini da 256³ voxel da circa 40 GB a meno di 10 GB, senza perdere accuratezza.
Velocità, compromessi e usi futuri
Poiché PatchMorph deve estrarre e ricombinare molte patch, è un po’ più lento all’inferenza rispetto a reti single-shot che elaborano l’intero volume, pur restando molto più veloce degli strumenti iterativi tradizionali. In cambio, è in grado di gestire immagini grandi, ad alta risoluzione e campionate in modo non uniforme direttamente nel loro spazio nativo, e può riutilizzare una varietà di architetture backbone, dalle semplici reti convoluzionali ai transformer avanzati. Questo rende più semplice portare potenti modelli di deep learning in studi di imaging cerebrale reali che prima non entravano in memoria. In termini pratici, PatchMorph dimostra che pensando a patch anziché a volumi interi, i ricercatori possono allineare dati cerebrali 3D complessi in modo accurato, efficiente e su scale precedentemente irraggiungibili.
Citazione: Skibbe, H., Byra, M., Watakabe, A. et al. Memory efficient training for 3D brain image registration networks using PatchMorph. Sci Rep 16, 14386 (2026). https://doi.org/10.1038/s41598-026-44858-x
Parole chiave: registrazione di immagini cerebrali, deep learning, imaging medico, MRI 3D, PatchMorph