Clear Sky Science · de
Speichereffizientes Training für 3D-Gehirnbild-Registrationsnetzwerke mit PatchMorph
Viele Gehirnscans verständlich machen
Moderne Gehirnforschung baut darauf auf, 3D-Scans vieler Menschen und Tiere zu vergleichen, doch jedes Gehirnbild unterscheidet sich leicht in Größe, Form und Auflösung. Sie präzise aufeinander abzustimmen, ohne riesige Rechner zu benötigen, ist eine große Herausforderung. Diese Arbeit stellt PatchMorph vor, eine neue Methode zur Ausrichtung großer 3D-Gehirnbilder, die den Speicherbedarf drastisch reduziert und dabei die Genauigkeit erhält oder sogar verbessert — und somit die Untersuchung größerer und reichhaltigerer Gehirndatensätze ermöglicht.
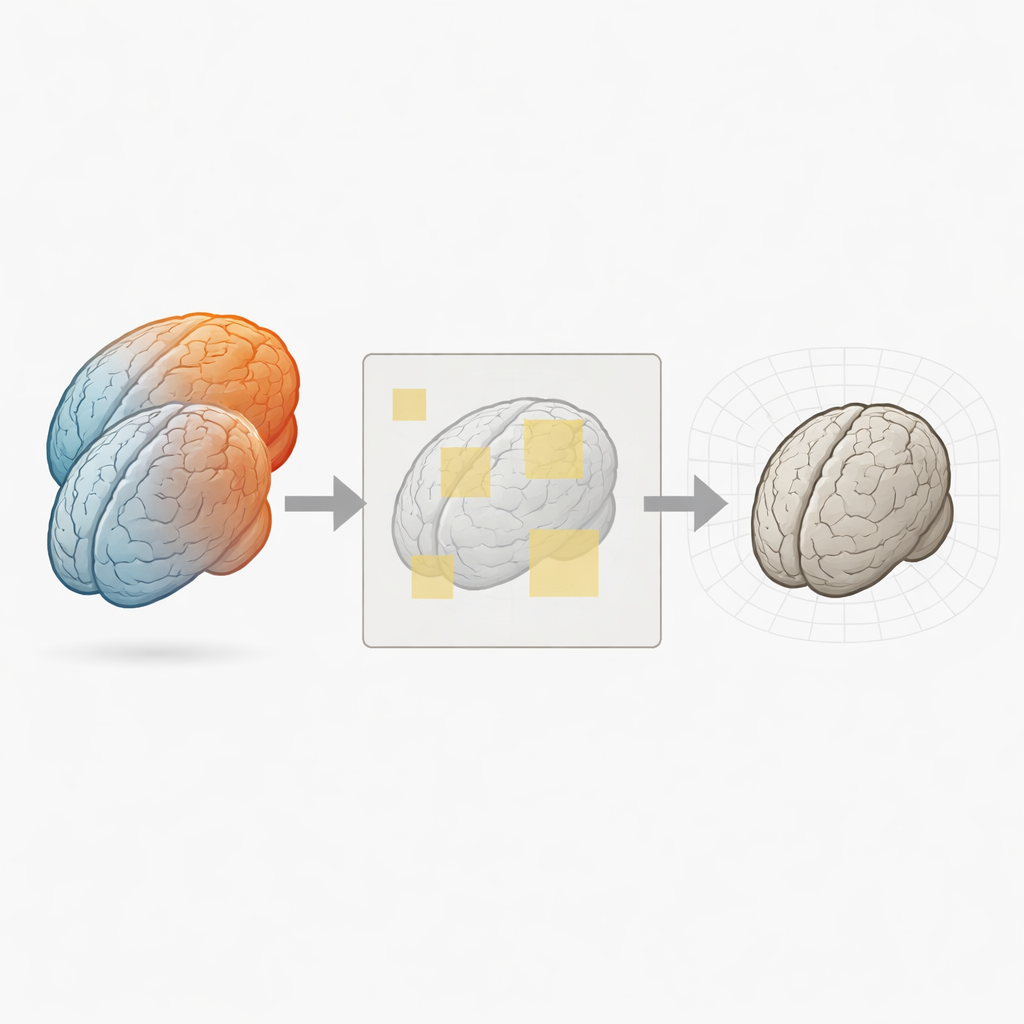
Warum das Ausrichten von Gehirnen so schwierig ist
Um Gehirne zu vergleichen, registrieren Forscher zunächst ein 3D-Bild auf ein anderes, indem sie ein Volumen so verformen, dass passende Strukturen übereinander liegen. Klassische Werkzeuge tun dies, indem sie ein Deformationsfeld schrittweise anpassen, bis ein Ähnlichkeitsmaß zwischen den Bildern maximiert ist. Neuere Deep-Learning-Methoden wie VoxelMorph lernen, diese Verformung in einem Schritt vorherzusagen, wodurch die Registrierung deutlich schneller wird. Die meisten dieser Netze erwarten jedoch, dass beide Eingabebilder dieselbe Gittergröße und Auflösung haben, und sie müssen oft komplette 3D-Volumina gleichzeitig verarbeiten. Mit wachsender Bildgröße und Modellkomplexität explodiert der benötigte Grafikspeicher schnell, sodass Forschende gezwungen sind, Daten zu verkleinern, zuzuschneiden oder stark vorzverarbeiten.
Gehirne Stück für Stück betrachten
PatchMorph löst dieses Nadelöhr, indem es niemals die vollständigen 3D-Volumina gleichzeitig ins Netzwerk lädt. Stattdessen arbeitet es mit kleinen 3D-"Patches", die im gemeinsamen Referenzraum verteilt über das feste Bild sampeln. Auf grober Ebene legt die Methode relativ große Patches über das ganze Gehirn, extrahiert passende Patches aus dem bewegten Bild mittels präziser Koordinatentransformationen und führt diese einem kompakten Registrationsnetz zu. Das Netzwerk sagt voraus, wie jeder Patch verschoben und verformt werden muss, damit sein lokaler Inhalt übereinstimmt. Die vielen lokalen Vorhersagen werden dann zurück in ein globales Deformationsfeld eingespeist und mittels glatter Interpolation so kombiniert, dass die Gesamtverformung kontinuierlich bleibt.
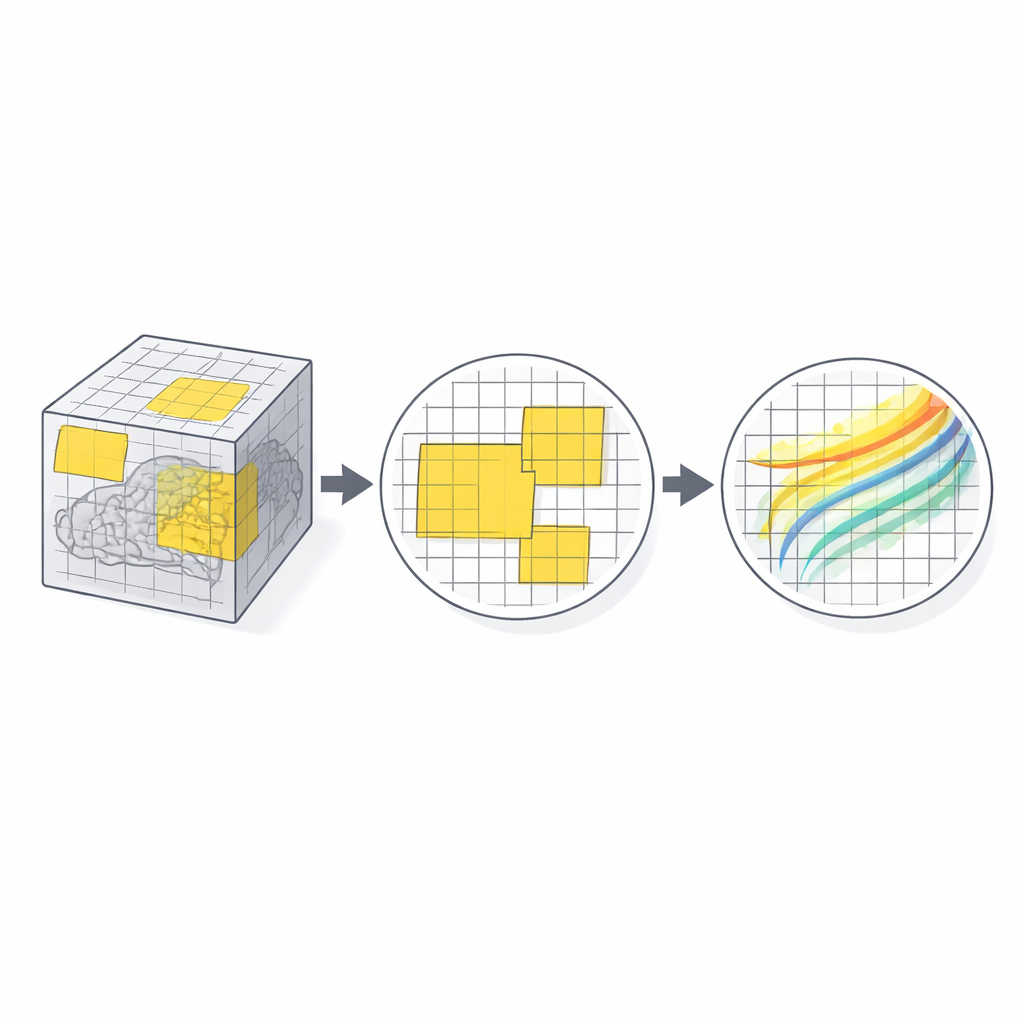
Von großen Patches zu feinen Details
PatchMorph arbeitet mehrskalig, von grob zu fein. Auf der ersten Skala deckt ein Patch eine große Gehirnregion in niedriger Auflösung ab und fängt grobe Fehlausrichtungen wie allgemeine Größen- oder Positionsunterschiede ein. In den folgenden Skalen "zoomen" neue Patches in Teilregionen zuvor sampelter Patches, behalten dabei aber stets dieselbe Anzahl an Voxel pro Patch im Speicher. Das bedeutet: feinere Skalen erhöhen die physische Detailauflösung, ohne den Speicherbedarf zu vergrößern. Die Patch-Positionen auf feineren Ebenen werden innerhalb ihrer übergeordneten Patches stochastisch gewählt, so dass die Methode sich nicht nur auf Patch-Zentren konzentriert, sondern nach und nach auch periphere Strukturen ausrichtet. Über die Skalen hinweg werden die geschätzten Deformationen zu einem einzigen globalen Feld akkumuliert, schrittweise verfeinert und stets räumlich konsistent gehalten.
Arbeiten mit realen Gehirndaten
Die Autorinnen und Autoren testeten PatchMorph an zwei anspruchsvollen Datensätzen: menschlichen T1-MRT-Scans aus dem MindBoggle-Projekt und hochauflösenden Marmoset-Gehirnbildern aus serieller Zwei-Photonen-Mikroskopie. Diese Bilder unterscheiden sich in Array-Größe, Orientierung und teils Voxel-Abständen — Bedingungen, die konventionelle Netze belasten. PatchMorph erreichte bei der Überlappung gelabelter Gehirnregionen vergleichbare oder bessere Ergebnisse als moderne Deep-Learning-Registrationsmethoden und wies zugleich sehr niedrige Raten topologischer Fehler (unrealistische Faltungen im Deformationsfeld) auf. Entscheidend ist, dass PatchMorph beim Training mit transformer-basierten Backbones den Speicherbedarf für 256³-Voxel-Bilder von etwa 40 GB auf unter 10 GB reduzierte, ohne Genauigkeit einzubüßen.
Geschwindigkeit, Kompromisse und künftige Anwendungen
Da PatchMorph viele Patches extrahieren und wieder zusammensetzen muss, ist es bei der Inferenz etwas langsamer als Single-Shot-Volumen-Netze, bleibt aber weiterhin deutlich schneller als traditionelle iterative Werkzeuge. Im Gegenzug kann es große, hochauflösende und ungleichmäßig sampelte Bilder direkt in ihrem nativen Raum verarbeiten und verschiedene Backbone-Architekturen wiederverwenden — von einfachen Faltungsnetzen bis zu fortgeschrittenen Transformern. Das erleichtert den Einsatz leistungsfähiger Deep-Learning-Modelle in realen Gehirnbildstudien, die zuvor nicht in den Speicher passten. Praktisch zeigt PatchMorph, dass man durch das Denken in Patches statt in ganzen Volumina komplexe 3D-Gehirndaten genau, effizient und in bislang unerreichten Größenordnungen ausrichten kann.
Zitation: Skibbe, H., Byra, M., Watakabe, A. et al. Memory efficient training for 3D brain image registration networks using PatchMorph. Sci Rep 16, 14386 (2026). https://doi.org/10.1038/s41598-026-44858-x
Schlüsselwörter: Gehirnbildregistrierung, Tiefenlernen, medizinische Bildgebung, 3D-MRT, PatchMorph