Clear Sky Science · pl
Wykorzystanie sieci twórców treści i percepcji użytkowników do wykrywania internetowych społeczności dyskursywnych
Dlaczego rozmowy online grupują się w obozy
Każdy, kto przewijał media społecznościowe w czasie wyborów, odczuł, jak szybko rozmowy dzielą się na przeciwne obozy. Tymczasem tylko niewielka część kont faktycznie rozpoczyna te dyskusje; większość z nas głównie polubi, udostępni lub udostępni dalej. Artykuł pyta, jak te nieliczne widoczne głosy kształtują ogólną debatę, i pokazuje sposób mapowania politycznych „komór echo” poprzez najpierw spojrzenie na liderów, a dopiero potem na ich audytoria.
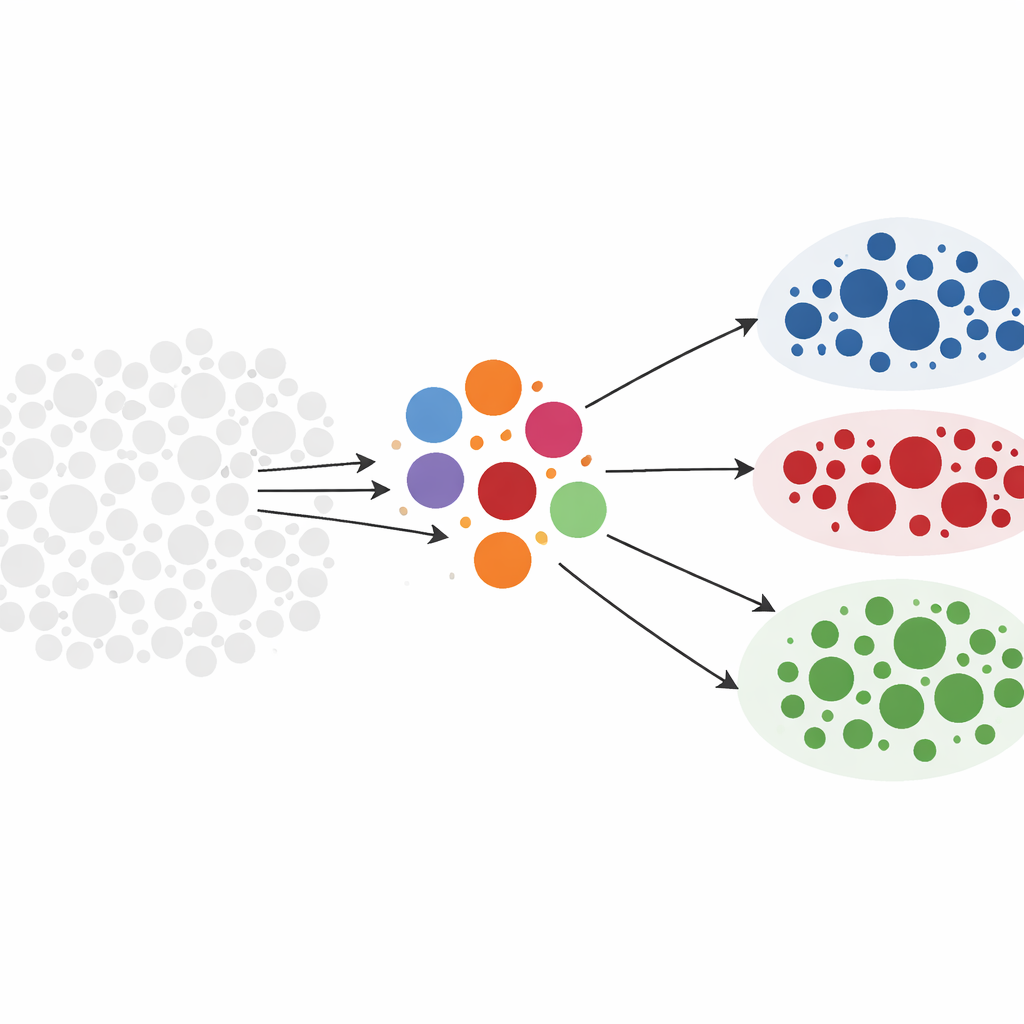
Niewielu mówiących, wielu słuchających
Na platformach takich jak Twitter/X uczestnictwo jest wysoce nierównomierne. Relatywnie mała grupa użytkowników — politycy, partie, marki medialne i inne postacie publiczne — produkuje większość postów napędzających polityczne rozmowy. Większość kont głównie konsumuje i redystrybuuje te treści, na przykład przez retweety. Autorzy twierdzą, że ci liderzy, ponieważ często zabierają głos i niosą ze sobą swoją publiczną reputację, zazwyczaj zajmują jaśniejsze, bardziej stabilne pozycje niż zwykli użytkownicy. Jeśli potrafimy wiarygodnie pogrupować liderów, możemy potem wnioskować, gdzie stoi szerszy tłum, obserwując, kogo on wzmacnia.
Dwa sposoby widzenia, kto stoi razem
Studium wprowadza ramy, które dzielą wszystkich użytkowników na dwa zestawy: producentów treści (liderów) i wszystkich pozostałych (audytorium). Następnie buduje sieć relacji między liderami i stosuje standardowe algorytmy wykrywania społeczności na tej mniejszej, czyściejszej sieci. Kluczowym wyborem jest sposób definiowania łączy między liderami. W jednej wersji, zwanej MonoDC, liderzy są połączeni, gdy często retweetują się nawzajem, co uchwyca bezpośrednie poparcie i sygnalizację wewnątrz politycznych kręgów. W drugiej wersji, zwanej BiDC, liderzy są połączeni, gdy są retweetowani przez podobne audytoria, tak że dwóch polityków z nakładającymi się obserwującymi trafia do tego samego obozu, nawet jeśli nigdy nie wchodzili w bezpośrednią interakcję.
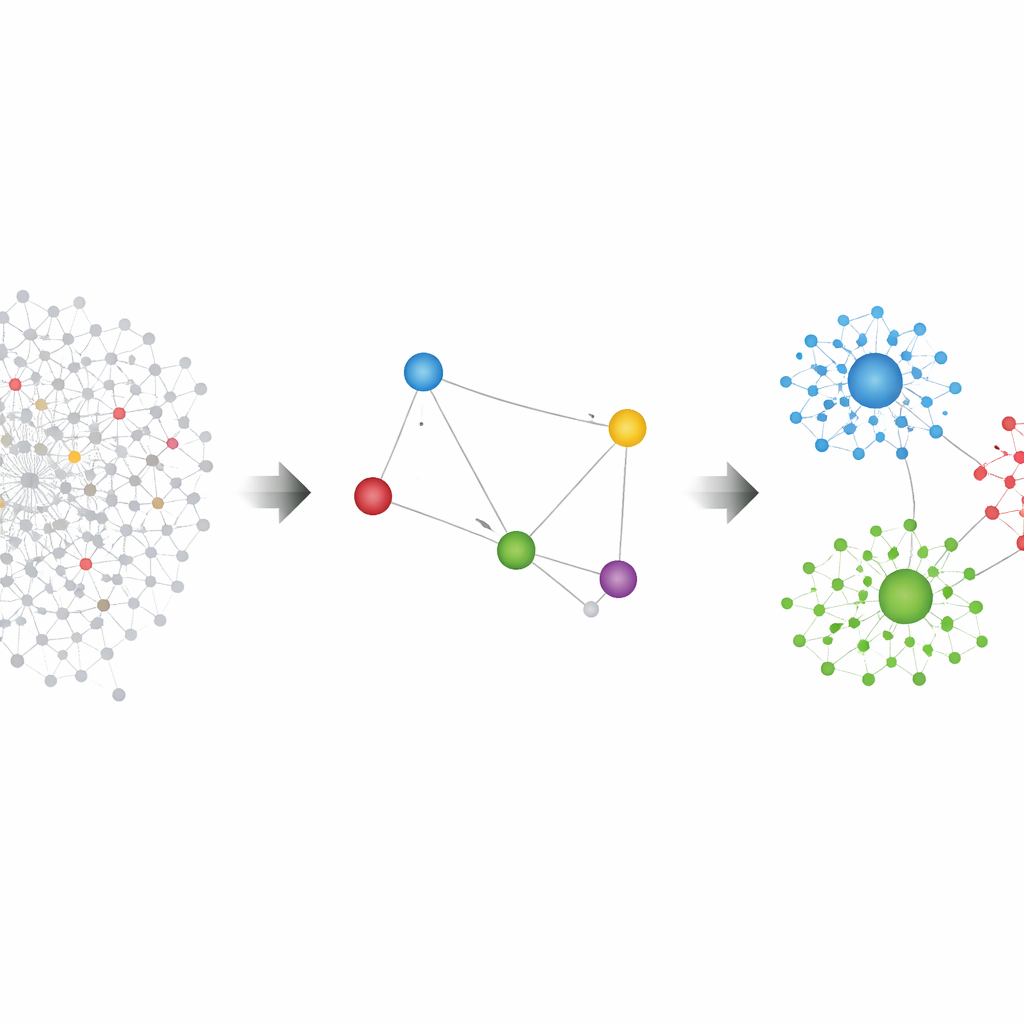
Filtrowanie szumu z danych społecznościowych
Surowe dane z mediów społecznościowych są niezwykle zaszumione: niektórzy ludzie tweetują cały czas, inni rzadko; niektóre posty stają się viralowe przypadkiem. Aby nie mylić losowej aktywności z rzeczywistą strukturą, autorzy używają narzędzi z teorii informacji do filtrowania swoich sieci. Porównują zaobserwowane interakcje z tym, czego należałoby oczekiwać w zrandomizowanym świecie, gdzie każdy użytkownik zachowuje ten sam ogólny poziom aktywności, ale połączenia są inaczej przetasowane. Zachowywane są tylko więzi znacznie silniejsze niż przewiduje taki „świat losowy”. To filtrowanie jest łagodne dla wersji z bezpośrednimi retweetami (MonoDC), ale kluczowe dla wersji o współdzielonym audytorium (BiDC), gdzie zwykła popularność mogłaby inaczej tworzyć mylące podobieństwa.
Postacie publiczne jako kotwice obozów online
Badacze testują swoje podejście na trzech głównych włoskich debatach politycznych na Twitterze/X w 2022 roku: wyborach prezydenckich, kryzysie rządowym i wyborach parlamentarnych. Co ważne, wszystkie dane pochodzą sprzed wprowadzenia płatnej weryfikacji na platformie, kiedy niebieski znaczek w większości sygnalizował rozpoznawalność publiczną, a nie subskrypcję. Autorzy traktują zweryfikowane konta jako liderów i ręcznie klasyfikują kilkaset z nich według partii i koalicji wyborczych. Stwierdzają, że nawet przed jakimkolwiek filtrowaniem, linki retweetów między tymi zweryfikowanymi politykami już układają się w odrębne bloki polityczne. Po zastosowaniu metod opartych na liderach i statystycznie filtrowanych, zgodność z rzeczywistymi partiami i koalicjami staje się znacznie silniejsza niż przy standardowych algorytmach stosowanych na pełnej, niefiltrowanej sieci retweetów.
Co działa — i co działa słabiej
MonoDC, opierający się na bezpośrednich retweetach między liderami, jest szczególnie dobry w wyłapywaniu pojedynczych partii: politycy głównie wspierają swoją własną stronę. BiDC, grupujący liderów przez wspólne audytoria, lepiej odzwierciedla szersze koalicje wyborcze, które łączą kilka partii pod tym samym parasolem. Autorzy próbują też alternatywnych sposobów wyboru liderów, takich jak konta z dużą liczbą obserwujących lub wysoki „wskaźnik retweetów”. Te oparte na aktywności wybory wypadają gorzej. Mają tendencję do włączania dziennikarzy i komentatorów, których audytoria rozciągają się na różne linie ideologiczne, rozmazując granice między obozami. Dla kontrastu, polityczne postacie zweryfikowane przed 2022 rokiem, których role poza siecią wiążą je z konkretnymi partiami, dostarczają stabilniejszego szkieletu do mapowania dyskursu online.
Dlaczego to ma znaczenie dla zrozumienia debaty cyfrowej
Dla czytelnika niebędącego specjalistą główne przesłanie jest takie, że polityczna rozmowa online nie jest płaskim rynkiem idei. Zamiast tego jest zorganizowana wokół relatywnie niewielkiego zestawu rozpoznawalnych aktorów, a reszta z nas ujawnia swoje skłonności przez to, których wiadomości decyduje się przekazać dalej. Poprzez najpierw identyfikację tych liderów, staranne filtrowanie ich powiązań, a dopiero potem przypisywanie zwykłych użytkowników do społeczności, autorzy potrafią odtworzyć dużą część leżącej u podstaw mapy politycznej z ograniczonych danych. Ich podejście, choć opracowane na włoskim Twitterze/X, w zasadzie można zastosować do wielu platform, gdzie kilka widocznych kont kształtuje to, co widzi większość, oferując praktyczny sposób badania komór echo nawet wtedy, gdy platformy ograniczają dostęp do danych lub zmieniają zasady weryfikacji.
Cytowanie: Guarino, S., Mounim, A., Caldarelli, G. et al. Leveraging content producer networks and user perception to detect online discursive communities. Sci Rep 16, 11911 (2026). https://doi.org/10.1038/s41598-026-39477-5
Słowa kluczowe: polaryzacja w mediach społecznościowych, społeczności polityczne, dyskurs na Twitterze, analiza sieci, internetowe komory informacyjne