Clear Sky Science · fr
Exploiter les réseaux de producteurs de contenu et la perception des utilisateurs pour détecter les communautés discursives en ligne
Pourquoi les discussions en ligne se regroupent en camps
Quiconque a fait défiler les réseaux sociaux pendant une élection a ressenti à quelle vitesse les conversations se scindent en camps opposés. Pourtant, une part infime des comptes initie réellement ces débats ; la plupart d'entre nous aimons, partageons ou retweetons surtout. Cet article s'interroge sur la manière dont ces quelques voix visibles façonnent le débat global, et montre une méthode pour cartographier les « chambres d'écho » politiques en regardant d'abord les leaders puis leur audience.
Peu de locuteurs, beaucoup d'auditeurs
Sur des plateformes comme Twitter/X, la participation est très inégale. Un groupe relativement restreint d'utilisateurs — politiciens, partis, médias et autres personnalités publiques — produit la majorité des messages qui alimentent la discussion politique. La majorité des comptes se contentent principalement de consommer et de redistribuer ce contenu, par exemple en retweetant. Les auteurs soutiennent que ces leaders, parce qu'ils s'expriment fréquemment et emportent avec eux leur réputation publique, prennent en général des positions plus nettes et plus stables que les utilisateurs ordinaires. Si l'on peut grouper ces leaders de façon fiable, on peut ensuite déduire où se situe la foule en observant qui elle amplifie.
Deux manières de voir qui se tient avec qui
L'étude présente un cadre qui sépare tous les utilisateurs en deux ensembles : les producteurs de contenu (leaders) et tous les autres (l'audience). Elle construit ensuite un réseau de relations entre les leaders et applique des algorithmes classiques de détection de communautés sur ce réseau plus petit et plus propre. Le choix clé est la définition des liens entre leaders. Dans une version, appelée MonoDC, les leaders sont reliés lorsqu'ils se retweetent fréquemment, capturant l'endossement direct et le signal au sein des cercles politiques. Dans l'autre version, appelée BiDC, les leaders sont liés lorsqu'ils sont retweetés par des audiences similaires, de sorte que deux politiciens aux abonnés chevauchants se retrouvent dans le même camp même s'ils n'interagissent jamais directement.
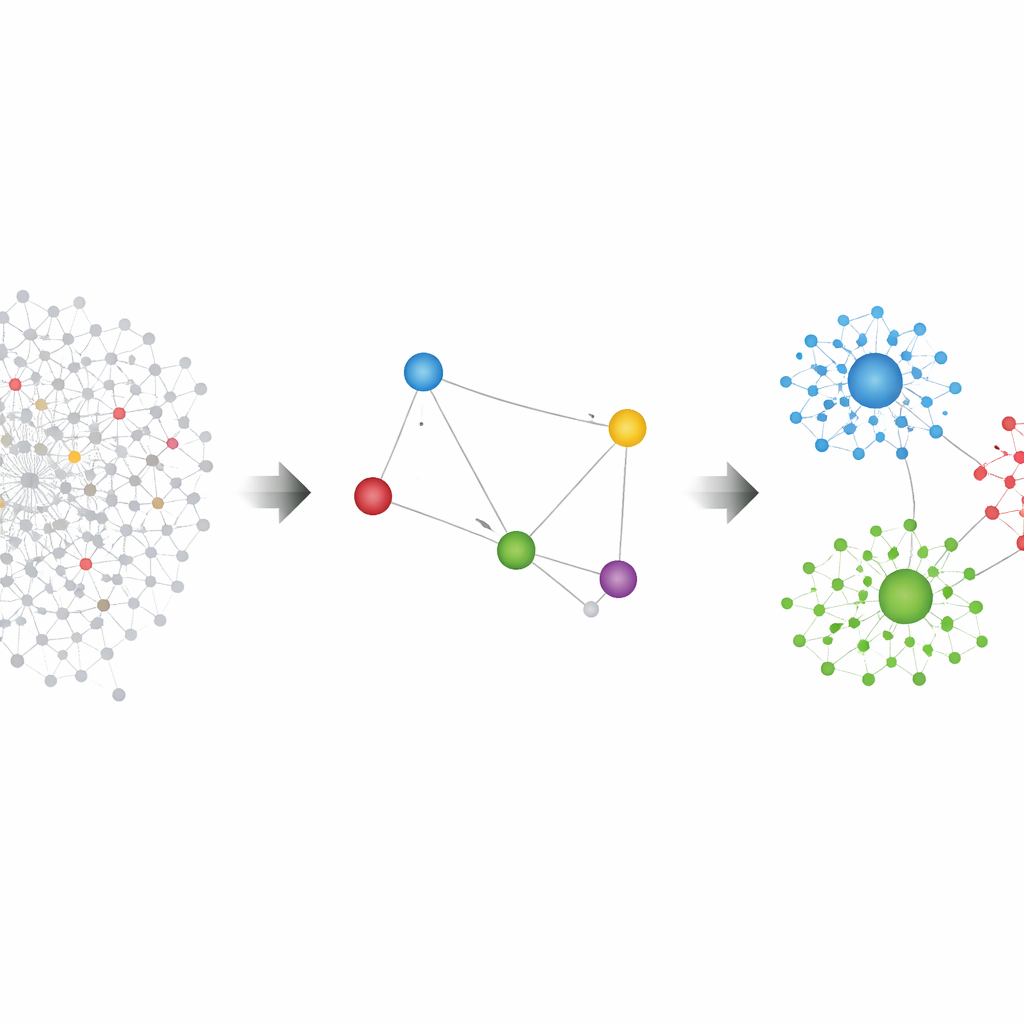
Filtrer le bruit des données sociales
Les données brutes des réseaux sociaux sont extrêmement bruyantes : certaines personnes tweetent en continu, d'autres rarement ; certains messages deviennent viraux par chance. Pour éviter de confondre activité aléatoire et structure réelle, les auteurs utilisent des outils de la théorie de l'information pour filtrer leurs réseaux. Ils comparent les interactions observées avec ce qu'on attendrait dans un monde aléatoire où chaque utilisateur conserverait le même niveau global d'activité mais où les connexions seraient sinon remaniées. Seules sont conservées les liaisons beaucoup plus fortes que ce que prédit ce « monde aléatoire ». Ce filtrage est léger pour la version par retweet direct (MonoDC) mais crucial pour la version par audience partagée (BiDC), où la simple popularité pourrait autrement créer des similitudes trompeuses.
Les figures publiques comme ancres des camps en ligne
Les chercheurs testent leur approche sur trois grands débats politiques italiens sur Twitter/X en 2022 : l'élection présidentielle, une crise gouvernementale et les élections générales. Il est important de noter que toutes les données proviennent d'avant l'introduction de la vérification payante sur la plateforme, lorsque la coche bleue signalait principalement une reconnaissance publique, et non un abonnement. Les auteurs traitent les comptes vérifiés comme des leaders et en classent manuellement quelques centaines selon le parti et la coalition électorale. Ils constatent que, même avant tout filtrage, les liens de retweet entre ces politiciens vérifiés forment déjà des blocs politiques distincts. Lorsqu'ils appliquent leurs méthodes basées sur les leaders et filtrées statistiquement, la correspondance avec les partis et coalitions réels devient beaucoup plus forte que celle obtenue par des algorithmes standard appliqués au réseau de retweets complet et non filtré.
Ce qui fonctionne — et ce qui fonctionne moins bien
MonoDC, qui s'appuie sur les retweets directs entre leaders, est particulièrement performant pour repérer les partis individuels : les politiciens soutiennent principalement leur propre camp. BiDC, qui groupe les leaders par audiences partagées, reflète mieux les coalitions électorales plus larges qui rassemblent plusieurs partis sous une même bannière. Les auteurs testent aussi d'autres façons de sélectionner les leaders, comme les comptes avec beaucoup d'abonnés ou un « indice de retweet » élevé. Ces sélections fondées sur l'activité donnent de moins bons résultats. Elles tendent à inclure des journalistes et des commentateurs dont l'audience traverse les lignes idéologiques, estompant les frontières entre camps. En revanche, les personnalités politiques vérifiées pré-2022, dont les rôles hors ligne les lient à des partis spécifiques, fournissent une ossature plus stable pour cartographier le discours en ligne.
Pourquoi c'est important pour comprendre le débat numérique
Pour un lecteur non spécialiste, le message principal est que la conversation politique en ligne n'est pas un marché d'idées plat. Elle s'organise plutôt autour d'un ensemble relativement restreint d'acteurs reconnaissables, et le reste d'entre nous révèle ses inclinations par les messages que nous choisissons de relayer. En identifiant d'abord ces leaders, en filtrant soigneusement leurs connexions, puis en assignant seulement ensuite les utilisateurs ordinaires aux communautés, les auteurs peuvent reconstituer une grande partie de la carte politique sous-jacente à partir de données limitées. Leur approche, bien que développée sur Twitter/X italien, peut en principe s'appliquer à de nombreuses plateformes où quelques comptes visibles façonnent ce que beaucoup voient, offrant une méthode pratique pour étudier les chambres d'écho même lorsque les plateformes restreignent l'accès aux données ou modifient leurs règles de vérification.
Citation: Guarino, S., Mounim, A., Caldarelli, G. et al. Leveraging content producer networks and user perception to detect online discursive communities. Sci Rep 16, 11911 (2026). https://doi.org/10.1038/s41598-026-39477-5
Mots-clés: polarisation sur les réseaux sociaux, communautés politiques, discours sur Twitter, analyse de réseau, chambres d'écho en ligne