Clear Sky Science · pl
Poprawa bezpieczeństwa drogowego w inteligentnych miastach za pomocą technik uczenia maszynowego
Dlaczego bezpieczniejsze ulice dotyczą nas wszystkich
Za każdym razem, gdy schodzimy z krawężnika, jedziemy na rowerze lub przejeżdżamy przez skrzyżowanie, wchodzimy w system, w którym drobne błędy mogą mieć skutki zmieniające życie. W tym badaniu stawiane jest proste, lecz istotne pytanie: czy możemy wykorzystać nowoczesne narzędzia danych, by przewidzieć, które sytuacje drogowe najczęściej prowadzą do poważnych obrażeń, i naprawić je zanim dojdzie do wypadków? Porównując rzeczywiste rejestry wypadków z Toronto w Kanadzie i Rawalpindi w Pakistanie, autorzy pokazują, jak idee inteligentnego miasta i uczenie maszynowe mogą przekształcić surowe liczby w praktyczne zmiany ratujące życie.
Baczne przyjrzenie się rzeczywistym wypadkom
Badacze zgromadzili dwie duże kolekcje zapisów policyjnych i ratowniczych. Jedna, z Toronto, obejmuje tysiące kolizji, w których ludzie zginęli lub odnieśli ciężkie obrażenia przez ponad dekadę. Druga, z Rawalpindi, obejmuje dziesiątki tysięcy wypadków zgłaszanych służbom ratowniczym miasta w okresie COVID‑19. Każdy rekord zawiera szczegóły takie jak pora dnia, dzień tygodnia, rodzaj drogi, oświetlenie i warunki pogodowe, wiek i role osób (kierowca, rowerzysta, pieszy) oraz co działo się tuż przed zderzeniem, np. przekroczenie prędkości czy agresywna jazda. Przed modelowaniem zespół oczyścił dane, poradził sobie z brakującymi wartościami i przekształcił wiele pól tekstowych na formę numeryczną zrozumiałą dla komputerów.
Nauka komputerów oceny ciężkości wypadków
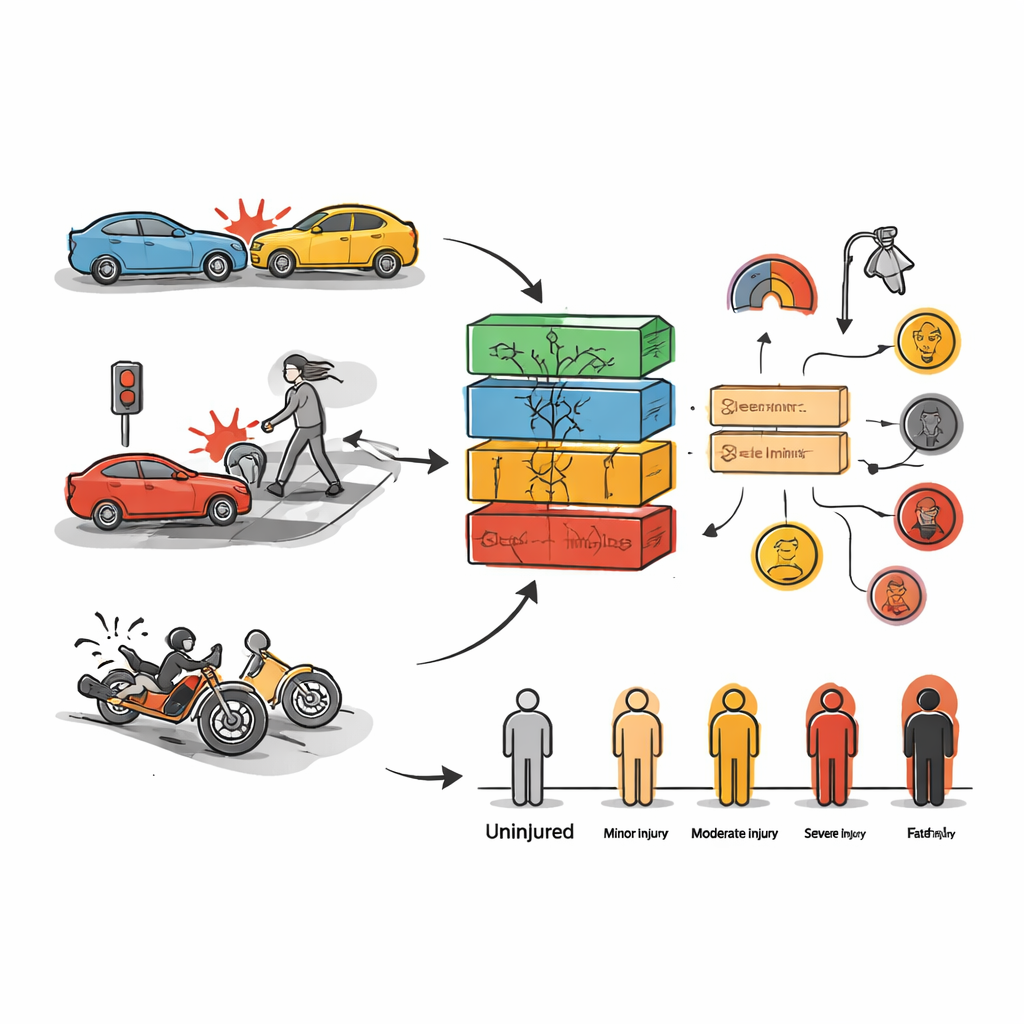
Pierwszym celem było przewidzenie, jak poważnych obrażeń doznały osoby w danej kolizji. W tym celu autorzy przetestowali szeroki zakres metod uczenia maszynowego — od klasycznych narzędzi, takich jak lasy drzew decyzyjnych, po bardziej złożone sieci głębokiego uczenia, często używane w rozpoznawaniu mowy czy obrazu. Modele trenowano na części danych i weryfikowano na pozostałych, prosząc każdy model o przyporządkowanie wypadków do kategorii takich jak brak obrażeń, obrażenia lekkie, ciężkie obrażenia lub śmiertelne. Spośród wszystkich podejść wyróżniły się dwa: XGBoost i Random Forest, oba łączące wiele prostych drzew decyzyjnych w silniejszy „komitet”. Nawet bez intensywnego strojenia modele te poprawnie klasyfikowały poziomy obrażeń w około trzech czwartych przypadków w Toronto; po starannym dopasowaniu Random Forest stał się szczególnie dokładny na danych treningowych.
Odkrywanie ukrytych wzorców stojących za poważnymi obrażeniami
Sama predykcja nie mówi urzędnikom, co zmienić w terenie, więc drugim celem było wydobycie kombinacji warunków, które wielokrotnie pojawiały się w przypadkach poważnych wypadków. W tym celu zespół zastosował wydobywanie reguł asocjacyjnych, technikę przeczesywania danych w poszukiwaniu wzorców „jeżeli‑to”. W obu miastach powtarzały się pewne składniki związane z ciężkimi obrażeniami: przekroczenie prędkości, agresywna lub nieostrożna jazda, utrata kontroli przez kierowcę, nieuwaga oraz zderzenia z udziałem pieszych lub motocyklistów. Brak kontroli ruchu na głównych drogach i przy ruchliwych skrzyżowaniach również okazał się kluczowym czynnikiem ryzyka. W danych z Rawalpindi jazda nocą, deszczowa pogoda i duże użytkowanie motocykli podczas weekendów szczególnie wiązały się z urazami takimi jak pojedyncze złamania; w Toronto niebezpieczne sytuacje często skupiały się wokół określonych dzielnic i pór tygodnia.
Różne miasta, wspólne lekcje
Porównując miasto północnoamerykańskie o wysokich dochodach z szybko rozwijającym się miastem w Azji Południowej, badanie pokazuje zarówno lokalne różnice, jak i uniwersalne problemy. Rejestry pakistańskie ujawniają wiele poważnych wypadków wśród bardzo młodych użytkowników motocykli traktujących je jako codzienny środek transportu, często bez kasków i po słabo oświetlonych drogach. Dane kanadyjskie silniej sygnalizują zagrożenia dla osób pieszych i rowerzystów w dzielnicach miejskich, gdzie częste są skręcające pojazdy i agresywna jazda na skrzyżowaniach. Pomimo tych różnic oba kraje wykazują wyraźne korzyści z koncentracji na zachowaniach kierowców, bezpieczniejszych prędkościach oraz lepiej zaprojektowanych przejściach dla pieszych i rowerzystów.
Przekuwanie wniosków w bezpieczniejsze podróże
Mówiąc prosto, praca pokazuje, że komputery mogą uczyć się na podstawie przeszłych wypadków, by wskazywać kiedy i gdzie najprawdopodobniej nastąpi kolejne poważne obrażenie oraz które złe nawyki lub słabe punkty w sieci drogowej są tego przyczyną. Modele uczenia maszynowego, takie jak XGBoost i Random Forest, można włączyć do systemów inteligentnego miasta monitorujących ruch w czasie rzeczywistym, pomagających służbom ratunkowym priorytetyzować najbardziej niebezpieczne zdarzenia oraz prowadzących planistów do ukierunkowanych napraw, takich jak sygnalizacja świetlna, egzekwowanie prędkości, oświetlenie czy edukacja młodych kierowców. Chociaż badanie ogranicza się do dwóch miast i napotyka wyzwania, takie jak niezrównoważone dane, oferuje praktyczny plan działania: połącz duże, rzeczywiste zbiory danych o wypadkach z nowoczesną analizą i wykorzystaj wyniki do projektowania dróg i przepisów, które cicho chronią nas wszystkich przy każdej podróży.
Cytowanie: Abid, M.S., Hussain, M., Nabi, S. et al. Improving road safety in smart cities using machine learning techniques. Sci Rep 16, 10793 (2026). https://doi.org/10.1038/s41598-026-36795-6
Słowa kluczowe: bezpieczeństwo drogowe, wypadki drogowe, inteligentne miasta, uczenie maszynowe, predykcja obrażeń