Clear Sky Science · de
Verbesserung der Verkehrssicherheit in Smart Cities mit Methoden des maschinellen Lernens
Warum sicherere Straßen uns alle betreffen
Jedes Mal, wenn wir von einem Bordstein treten, Fahrrad fahren oder eine Kreuzung passieren, betreten wir ein System, in dem kleine Fehler lebensverändernde Folgen haben können. Diese Studie stellt eine einfache, aber essentielle Frage: Können moderne Datentools vorhersagen, welche Straßensituationen am ehesten schwere Schäden verursachen, und diese dann beheben, bevor Unfälle passieren? Beim Vergleich realer Unfallaufzeichnungen aus Toronto in Kanada und Rawalpindi in Pakistan zeigen die Autoren, wie Smart‑City‑Ideen und maschinelles Lernen Rohdaten in praktische Maßnahmen verwandeln können, die Leben retten.
Blick auf tatsächliche Unfälle
Die Forschenden stellten zwei große Sammlungen von Polizei‑ und Rettungsaufzeichnungen zusammen. Die eine, aus Toronto, erfasst über mehr als ein Jahrzehnt hinweg Tausende von Kollisionen, bei denen Menschen getötet oder schwer verletzt wurden. Die andere, aus Rawalpindi, umfasst Zehntausende Unfälle, die während der COVID‑19‑Periode dem Rettungsdienst der Stadt gemeldet wurden. Jeder Datensatz enthält Details wie Tageszeit, Wochentag, Straßentyp, Licht- und Wetterverhältnisse, Alter und Rolle der Beteiligten (Fahrer, Radfahrende, Fußgänger) sowie das Geschehen unmittelbar vor dem Aufprall, etwa Geschwindigkeitsüberschreitung oder aggressives Fahren. Vor jeglicher Modellierung bereinigte das Team die Daten, ging mit fehlenden Werten um und wandelte viele Textfelder in numerische Formate um, die Computer verarbeiten können.
Computern beibringen, das Verletzungsausmaß zu beurteilen
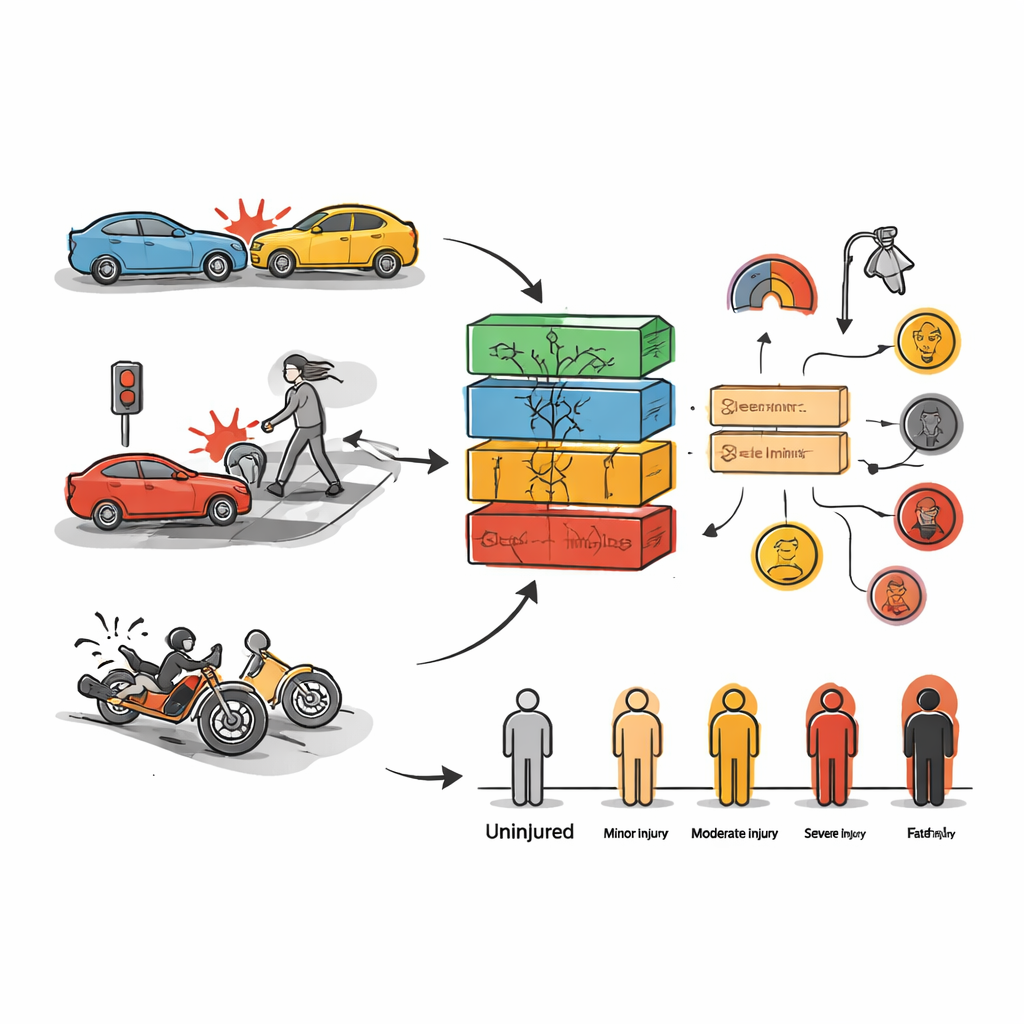
Das erste Ziel war, vorherzusagen, wie schwer Menschen bei einer bestimmten Kollision verletzt würden. Dazu testeten die Autoren eine breite Palette von Methoden des maschinellen Lernens, von klassischen Werkzeugen wie Entscheidungsbaum‑"Wäldern" bis zu komplexeren Deep‑Learning‑Netzen, wie sie häufig in Sprach‑ oder Bilderkennung eingesetzt werden. Sie trainierten diese Modelle mit einem Teil der Daten und prüften ihre Leistungsfähigkeit an den übrigen Daten, wobei jedes Modell Unfälle in Kategorien wie keine Verletzung, leichte Verletzung, schwere Verletzung oder tödlich einordnen sollte. Unter allen Ansätzen stachen zwei heraus: XGBoost und Random Forest, die beide viele einfache Entscheidungsbäume zu einem stärkeren "Gremium" kombinieren. Selbst ohne aufwändige Feinabstimmung klassifizierten diese Modelle die Verletzungslevel in etwa drei Vierteln der Fälle in Toronto korrekt; nach sorgfältiger Anpassung wurde insbesondere Random Forest auf den Trainingsdaten sehr genau.
Verborgene Muster hinter schweren Verletzungen entdecken
Alleinige Vorhersage sagt den Verantwortlichen nicht, was vor Ort zu ändern ist, deshalb war das zweite Ziel, Kombinationen von Bedingungen aufzudecken, die wiederholt bei schweren Unfällen auftreten. Dafür nutzte das Team Association‑Rule‑Mining, eine Technik, die nach "Wenn‑dies‑dann‑das"‑Muster im Datenbestand sucht. In beiden Städten traten bestimmte Zutaten immer wieder dort auf, wo Menschen schwer verletzt wurden: Geschwindigkeitsüberschreitung, aggressives oder unachtsames Fahren, Fahrer, die die Kontrolle verlieren, Unaufmerksamkeit sowie Unfälle mit Fußgängern oder Motorradfahrern. Das Fehlen von Verkehrskontrollen auf Hauptstraßen und an stark frequentierten Kreuzungen erwies sich ebenfalls als wesentlicher Risikofaktor. In Rawalpindis Daten waren Nachtfahrten, Regenwetter und ein hoher Motorradanteil am Wochenende besonders mit Einzelbruchverletzungen und anderen Verletzungen verbunden; in Toronto konzentrierten sich gefährliche Situationen häufig in bestimmten Bezirken und zu bestimmten Wochentagen.
Unterschiedliche Städte, gemeinsame Lehren
Der Vergleich einer wohlhabenden nordamerikanischen Stadt mit einer sich schnell entwickelnden südasischen Stadt zeigt sowohl lokale Besonderheiten als auch universelle Probleme. Die pakistanischen Aufzeichnungen zeigen viele schwere Unfälle unter sehr jungen Fahrenden, die Motorräder als Alltagsverkehrsmittel nutzen, oft ohne Helm und auf schlecht beleuchteten Straßen. Die kanadischen Daten weisen dagegen stärker auf Gefährdungen von Fußgehenden und Radfahrenden in städtischen Bezirken hin, wo abbiegende Fahrzeuge und aggressives Fahrverhalten an Kreuzungen häufig sind. Trotz dieser Unterschiede ergeben sich in beiden Ländern deutliche Vorteile durch Maßnahmen, die Fahrverhalten, sichere Geschwindigkeiten und besser gestaltete Querungen für Fußgänger und Radfahrende in den Mittelpunkt stellen.
Erkenntnisse in sicherere Wege überführen
Einfach ausgedrückt zeigt die Arbeit, dass Computer aus vergangenen Unfällen lernen können, wann und wo die nächste schwere Verletzung am wahrscheinlichsten ist und welche schlechten Gewohnheiten oder Schwachstellen im Straßennetz dafür verantwortlich sind. Modelle des maschinellen Lernens wie XGBoost und Random Forest lassen sich in Smart‑City‑Systeme integrieren, die den Verkehr in Echtzeit überwachen, Rettungsdienste dabei unterstützen, gefährlichste Vorfälle zu priorisieren, und Planer zu gezielten Maßnahmen wie Ampeln, Geschwindigkeitskontrollen, Beleuchtung und Aufklärung junger Fahrender leiten. Obwohl die Studie auf zwei Städte beschränkt ist und Herausforderungen wie unausgewogene Daten bestehen, bietet sie einen praxisnahen Plan: Große, reale Unfallbestände mit moderner Datenanalyse kombinieren und die Ergebnisse nutzen, um Straßen und Regeln so zu gestalten, dass sie uns bei jeder Fahrt stillschweigend schützen.
Zitation: Abid, M.S., Hussain, M., Nabi, S. et al. Improving road safety in smart cities using machine learning techniques. Sci Rep 16, 10793 (2026). https://doi.org/10.1038/s41598-026-36795-6
Schlüsselwörter: Verkehrssicherheit, Verkehrsunfälle, Smart Cities, maschinelles Lernen, Verletzungsvorhersage