Clear Sky Science · fr
Améliorer la sécurité routière dans les villes intelligentes grâce aux techniques d’apprentissage automatique
Pourquoi des rues plus sûres comptent pour tous
Chaque fois que nous descendons d’un trottoir, faisons du vélo ou traversons un carrefour en voiture, nous entrons dans un système où de petites erreurs peuvent avoir des conséquences qui changent une vie. Cette étude pose une question simple mais essentielle : peut‑on utiliser les outils de données modernes pour prédire quelles situations routières sont les plus susceptibles d’entraîner des blessures graves, puis les corriger avant qu’un accident ne survienne ? En comparant des dossiers d’accidents réels de Toronto au Canada et de Rawalpindi au Pakistan, les auteurs montrent comment les idées de ville intelligente et l’apprentissage automatique peuvent transformer des chiffres bruts en changements pratiques qui sauvent des vies.
Examiner de près les accidents réels
Les chercheurs ont rassemblé deux grandes collections de rapports de police et d’urgence. L’un, provenant de Toronto, recense des milliers de collisions ayant entraîné des décès ou des blessures graves sur plus d’une décennie. L’autre, de Rawalpindi, couvre des dizaines de milliers d’accidents signalés au service de secours de la ville pendant la période de la COVID‑19. Chaque dossier comprend des détails tels que l’heure de la journée, le jour de la semaine, le type de route, l’éclairage et la météo, l’âge des personnes et leur rôle (conducteur, cycliste, piéton), et ce qui se passait juste avant l’impact, comme un excès de vitesse ou une conduite agressive. Avant toute modélisation, l’équipe a nettoyé les données, traité les valeurs manquantes et converti de nombreux champs textuels en formes numériques compréhensibles par les ordinateurs.
Apprendre aux ordinateurs à évaluer la gravité des accidents
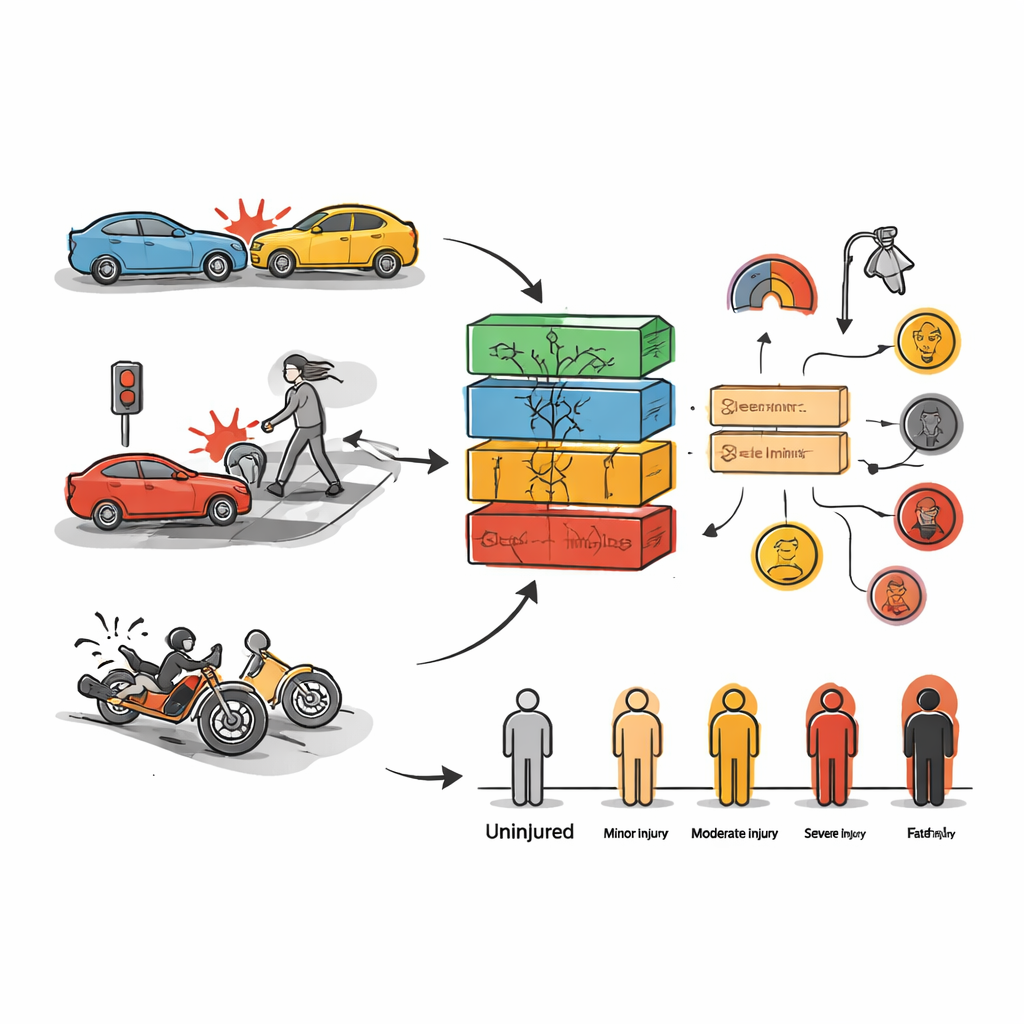
Le premier objectif était de prédire l’importance des blessures subies lors d’une collision donnée. Pour cela, les auteurs ont testé un large éventail de méthodes d’apprentissage automatique, depuis des outils classiques comme les « forêts » d’arbres de décision jusqu’à des réseaux profonds plus complexes souvent utilisés en reconnaissance vocale ou d’images. Ils ont entraîné ces modèles sur une partie des données et vérifié leurs performances sur le reste, demandant à chaque modèle de classer les collisions en catégories telles que sans blessure, blessure légère, blessure grave ou mortelle. Parmi toutes les approches, deux se sont démarquées : XGBoost et Random Forest, qui combinent de nombreux arbres de décision simples en un « comité » plus puissant. Même sans réglages poussés, ces modèles ont correctement classé le niveau de blessure pour environ les trois quarts des cas de Toronto ; après ajustements minutieux, Random Forest est notamment devenu extrêmement précis sur les données d’apprentissage.
Découvrir les schémas cachés derrière les blessures graves
La simple prédiction n’indique pas aux responsables ce qu’il faut changer sur le terrain, le deuxième objectif était donc de mettre au jour des combinaisons de conditions qui apparaissent régulièrement dans les accidents graves. Pour cela, l’équipe a utilisé l’extraction de règles d’association, une technique qui parcourt les données à la recherche de motifs du type « si‑ça‑alors‑cela ». Dans les deux villes, certains éléments revenaient sans cesse là où des personnes étaient grièvement blessées : excès de vitesse, conduite agressive ou négligente, perte de contrôle du véhicule, inattention, et collisions impliquant des piétons ou des motocyclistes. L’absence de dispositifs de régulation de la circulation sur des routes principales et à des intersections fréquentées est également apparue comme un facteur de risque clé. Dans les données de Rawalpindi, la conduite de nuit, la pluie et l’usage élevé de motos durant les week‑ends étaient particulièrement liés aux fractures isolées et autres blessures ; à Toronto, les situations dangereuses se concentraient souvent autour de certains quartiers et moments de la semaine.
Des villes différentes, des leçons communes
En comparant une ville nord‑américaine à haut revenu avec une ville sud‑asiatique en forte croissance, l’étude met en évidence à la fois des particularités locales et des problèmes universels. Les dossiers pakistanais révèlent de nombreux accidents graves impliquant de très jeunes conducteurs de motos qui utilisent ces véhicules pour leurs déplacements quotidiens, souvent sans casque et sur des routes mal éclairées. Les données canadiennes, en revanche, mettent davantage l’accent sur les menaces auxquelles sont confrontées les personnes qui marchent ou circulent à vélo dans les quartiers urbains, où les véhicules qui tournent et la conduite agressive aux intersections sont fréquents. Malgré ces différences, les deux pays montrent des bénéfices clairs à se concentrer sur le comportement des conducteurs, des vitesses plus sûres et des traversées mieux conçues pour les piétons et les cyclistes.
Transformer les connaissances en trajets plus sûrs
Concrètement, le travail démontre que les ordinateurs peuvent apprendre des accidents passés pour signaler quand et où la prochaine blessure grave est la plus susceptible de se produire, et quelles mauvaises habitudes ou faiblesses du réseau routier en sont responsables. Des modèles d’apprentissage automatique comme XGBoost et Random Forest peuvent être intégrés dans des systèmes de villes intelligentes qui surveillent le trafic en temps réel, aident les services d’urgence à prioriser les incidents les plus dangereux et guident les planificateurs vers des corrections ciblées telles que feux de circulation, contrôle de la vitesse, éclairage et éducation des jeunes conducteurs. Bien que l’étude soit limitée à deux villes et fasse face à des défis comme des données déséquilibrées, elle propose un plan d’action pratique : combiner de larges archives d’accidents réels avec des analyses de données modernes, et utiliser les résultats pour concevoir des routes et des règles qui nous protègent discrètement à chaque déplacement.
Citation: Abid, M.S., Hussain, M., Nabi, S. et al. Improving road safety in smart cities using machine learning techniques. Sci Rep 16, 10793 (2026). https://doi.org/10.1038/s41598-026-36795-6
Mots-clés: sécurité routière, accidents de la route, villes intelligentes, apprentissage automatique, prévision des blessures