Clear Sky Science · en
Improving road safety in smart cities using machine learning techniques
Why safer streets matter to everyone
Every time we step off a curb, ride a bike, or drive through an intersection, we enter a system where small mistakes can have life‑changing consequences. This study asks a simple but vital question: can we use modern data tools to predict which road situations are most likely to cause serious harm, and then fix them before crashes happen? By comparing real accident records from Toronto in Canada and Rawalpindi in Pakistan, the authors show how smart‑city ideas and machine learning can turn raw numbers into practical changes that save lives.
Looking closely at real crashes
The researchers assembled two large collections of police and emergency records. One, from Toronto, tracks thousands of collisions where people were killed or seriously injured over more than a decade. The other, from Rawalpindi, covers tens of thousands of accidents reported to the city’s rescue service during the COVID‑19 period. Each record includes details such as time of day, day of the week, road type, lighting and weather, people’s ages and roles (driver, cyclist, pedestrian), and what was happening just before impact, such as speeding or aggressive driving. Before any modeling, the team cleaned the data, dealt with missing values, and converted many text fields into numeric form that computers can understand.
Teaching computers to judge crash severity
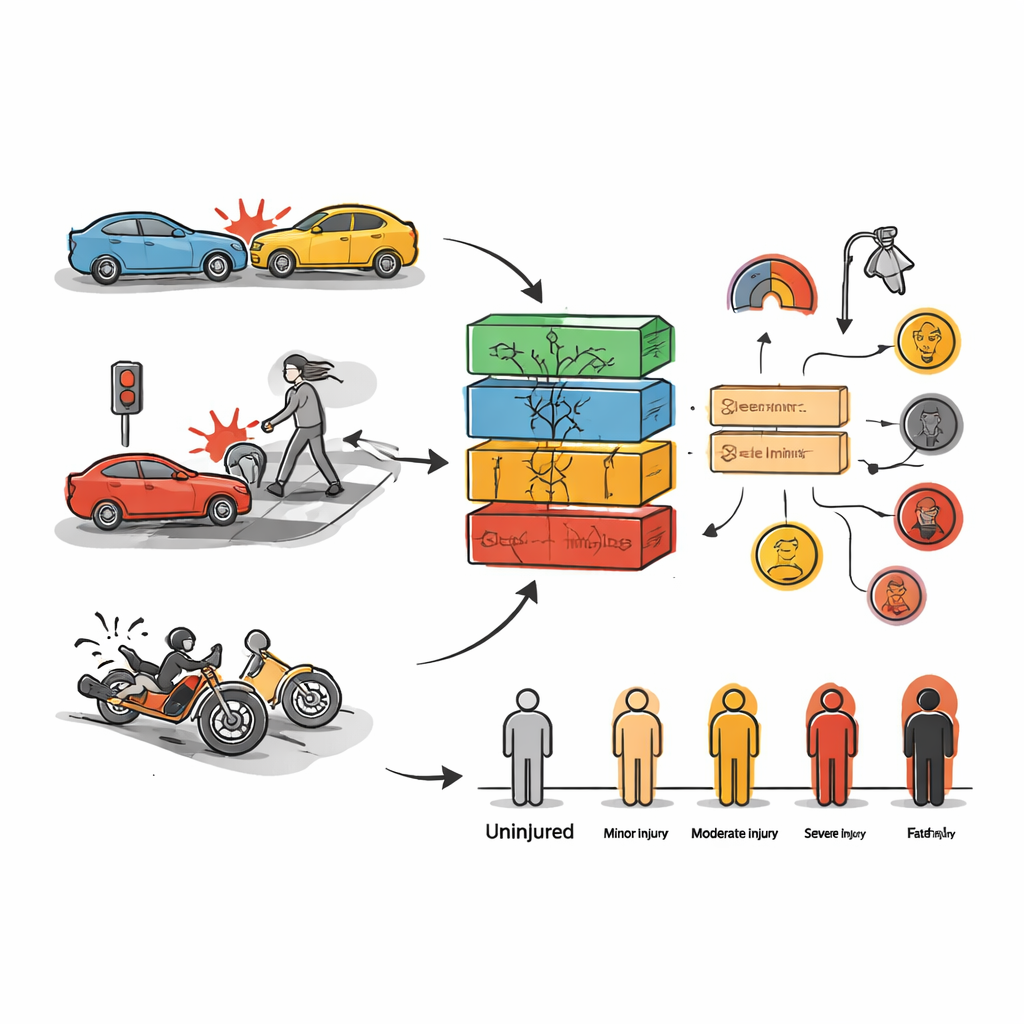
The first goal was to predict how badly people would be hurt in a given collision. To do this, the authors tested a wide range of machine‑learning methods, from classic tools like decision‑tree “forests” to more complex deep‑learning networks that are often used in speech or image recognition. They trained these models on part of the data and checked their skill on the rest, asking each model to sort crashes into categories such as no injury, minor injury, major injury, or fatal. Among all the approaches, two stood out: XGBoost and Random Forest, both of which combine many simple decision trees into a stronger “committee.” Even without heavy fine‑tuning, these models correctly classified injury levels for about three‑quarters of Toronto cases; after careful adjustment, Random Forest in particular became extremely accurate on the training data.
Discovering hidden patterns behind serious harm
Prediction alone does not tell officials what to change on the ground, so the second goal was to uncover combinations of conditions that repeatedly show up in serious crashes. For this, the team used association‑rule mining, a technique that sifts through data for “if‑this‑then‑that” patterns. In both cities, certain ingredients appeared again and again where people were badly hurt: speeding, aggressive or careless driving, drivers losing control, inattention, and collisions involving pedestrians or motorcyclists. The absence of traffic controls on major roads and at busy intersections also emerged as a key risk factor. In Rawalpindi’s data, nighttime driving, rainy weather, and high motorcycle use during weekends were especially linked to single‑fracture and other injuries; in Toronto, dangerous situations often clustered around particular districts and times of week.
Different cities, shared lessons
By comparing a high‑income North American city with a fast‑growing South Asian one, the study shows both local quirks and universal problems. Pakistan’s records reveal many severe crashes among very young riders using motorcycles as everyday transport, often without helmets and on poorly lit roads. Canada’s data, in contrast, points more strongly to threats faced by people walking and cycling in urban districts, where turning vehicles and aggressive driving at intersections are common. Despite these differences, both countries show clear benefits from focusing on driver behavior, safer speeds, and better‑designed crossings for people on foot or on bikes.
Turning insights into safer journeys
In plain terms, the work demonstrates that computers can learn from past crashes to flag when and where the next serious injury is most likely to occur, and which bad habits or weak spots in the road network are to blame. Machine‑learning models like XGBoost and Random Forest can be built into smart‑city systems that watch traffic in real time, help emergency services prioritize the most dangerous incidents, and guide planners toward targeted fixes such as traffic lights, speed enforcement, lighting, and education for young drivers. While the study is limited to two cities and faces challenges such as unbalanced data, it offers a practical blueprint: combine large, real‑world accident records with modern data analysis, and use the results to design roads and rules that quietly protect all of us every time we travel.
Citation: Abid, M.S., Hussain, M., Nabi, S. et al. Improving road safety in smart cities using machine learning techniques. Sci Rep 16, 10793 (2026). https://doi.org/10.1038/s41598-026-36795-6
Keywords: road safety, traffic accidents, smart cities, machine learning, injury prediction