Clear Sky Science · nl
Het zwarte vakje van reservoir computing verhelderen
Een kijkje in een slimme vorm van neurale netwerken
Veel moderne AI-systemen zijn indrukwekkend maar geheimzinnig, zeker wanneer ze informatie verwerken die zich in de tijd ontvouwt, zoals spraak, gebaren of veranderend weer. Deze studie kijkt naar binnen bij één zo’n aanpak, reservoir computing, om te achterhalen hoe eenvoudig zulke systemen kunnen zijn terwijl ze toch goed functioneren, en welke ontwerpkeuzes echt belangrijk zijn voor verschillende typen taken.
Hoe een reservoircomputer informatie verwerkt
In een reservoircomputer passeren binnenkomende signalen eerst een vaste web van onderling verbonden eenheden, het reservoir, en gaan vervolgens naar een trainbare outputlaag die het eindantwoord produceert. De twist is dat alleen de laatste laag wordt getraind, terwijl de interne verbindingen grotendeels willekeurig zijn en ongemoeid blijven. De auteurs beschouwen deze opzet als een machine die een invoersequentie omzet in een uitvoersequentie, en ze variëren systematisch hoeveel eenheden het reservoir bevat, hoe sterk ze elkaar beïnvloeden, en hoe scherp elke eenheid op zijn input reageert. Ze experimenteren ook met verschillende vormen van de responscurve, waaronder vloeiende krommen, eenvoudige rechte lijnen en schakelachtige aan‑uitgedrag, evenals met verschillende manieren om de inputs in het reservoir te bedrade n.
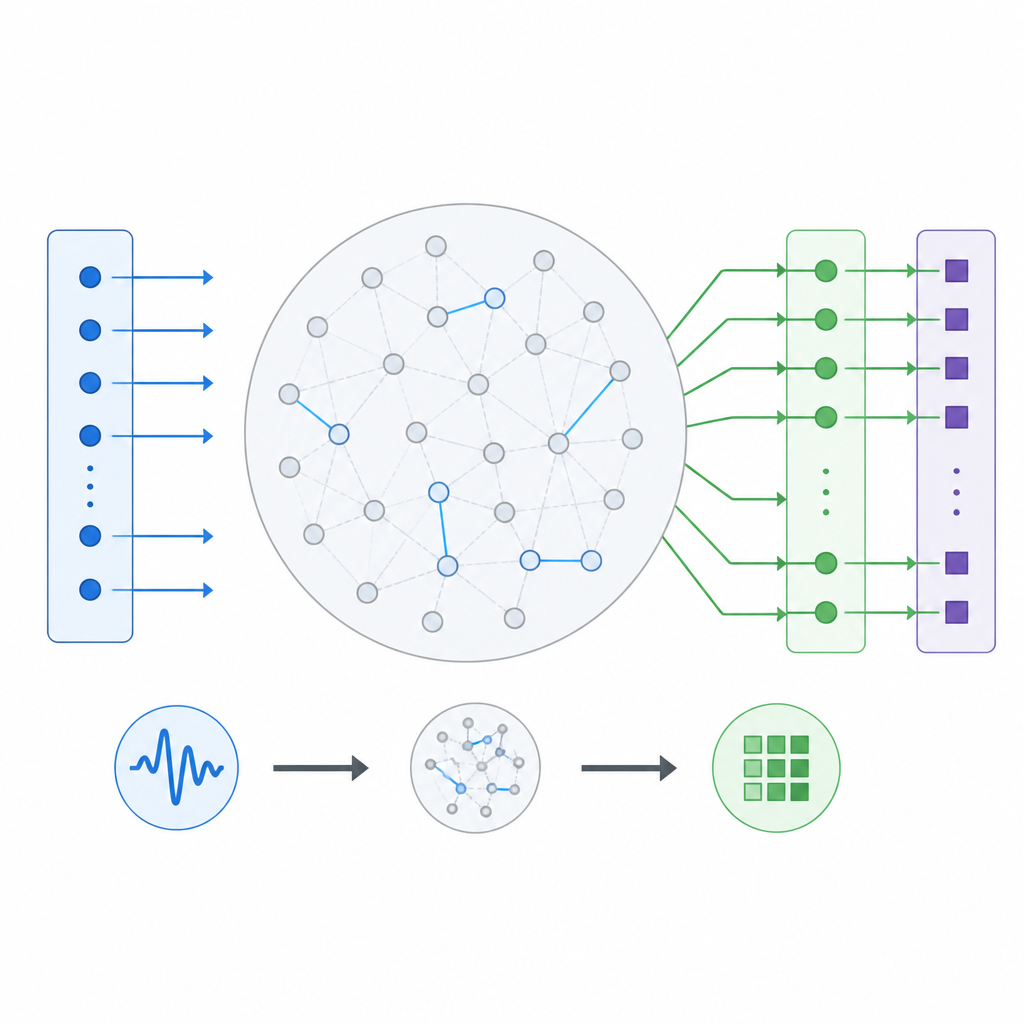
Eenvoudige dynamica kan toch het verleden onthouden
Een reeks tests vraagt het systeem om korte willekeurige reeksen getallen te onthouden en later te reproduceren. Voor deze "sequentiememorisatie"-taak moet het reservoir vervagende sporen van eerdere inputs bewaren zonder dat ze volledig worden overschreven door nieuw ingebrachte signalen. De onderzoekers vinden een gulden middenweg: als de interne verbindingen te zwak zijn, verspreiden signalen zich niet voorbij een paar eenheden en faalt het geheugen; als ze te sterk zijn, wordt de activiteit onregelmatig en chaotisch en raken nuttige sporen verloren in de ruis. Goede prestaties treden op in een kalm regime waar de activiteit snel tot rust komt na elke input en waar de eenheden zich bijna lineair gedragen. Verrassend genoeg werkt voor deze geheugenfocuste taak puur lineaire eenheden, zonder ingebouwde niet-lineariteit, soms zelfs beter dan de gebruikelijke verzachtende kromme.
Wanneer gebogen beslissingsgrenzen nodig zijn
Een andere taak richt zich op classificatie in plaats van geheugen. Hier ziet het systeem puntjes in een tweedimensionaal vlak en moet elk punt toewijzen aan een van twee klassen die zijn gerangschikt in een dambordpatroon van kleine vierkante vakjes. Dit vereist gebogen beslissingsgrenzen, want rechte lijnen kunnen het vlak niet in zo’n mozaïek verdelen. In deze niet-temporale situatie doet de recurrente bedrading van het reservoir er nauwelijks toe en gedraagt het systeem zich als een feedforward-netwerk met een vaste verborgen laag. Wat cruciaal blijkt te zijn, is de vorm en steilheid van de responscurven van de eenheden. Vloeiende niet-lineaire responsen, op een tussenliggende steilheid geschaald, stellen de outputlaag in staat grenzen te trekken die nauw het dambordpatroon volgen, terwijl eenvoudige lineaire of harde schakelachtige responsen slecht presteren.
De regels van een digitale wereld leren
Vervolgens dagen de auteurs het systeem uit met een zwaardere niet-temporale opdracht: het voorspellen van de volgende toestand van een kleine cellulaire automaat, een eenvoudige digitale wereld waarin elke cel aan of uit gaat volgens het patroon van zijn buren. Om te slagen moet de reservoircomputer de verborgen update‑regel afleiden uit voorbeelden en die toepassen op nieuwe patronen die hij nog nooit heeft gezien. Hierbij zijn zowel de recurrente structuur als vloeiende niet-lineariteit belangrijk, en grotere reservoirs helpen aanzienlijk. Met genoeg eenheden en goed gekozen responssteilheid kan het systeem perfecte nauwkeurigheid bereiken voor complexe regels en zo het gedrag van de automaat stap voor stap reproduceren.
Sequenties op aanvraag genereren
In een laatste reeks experimenten wordt het systeem niet alleen gevraagd te herkennen of voorspellen, maar hele sequenties te genereren. Een korte input die een van meerdere klassen aanduidt, moet het reservoir triggeren om een klassen‑specifiek pad door zijn interne toestanden te volgen, dat de outputlaag omzet in een doelsequentie van getallen. Ook hier is er een optimaal midden: enige interne koppeling en niet-lineariteit zijn nodig om rijke trajecten te creëren die vele stappen aanhouden, maar te sterke koppeling duwt het systeem in chaotisch gedrag dat de verschillen tussen klassen vervaagt en de outputlaag verstoort.
Wat dit betekent voor het ontwerpen van slimere systemen
Al met al laat de studie zien dat er geen enkel recept bestaat voor het bouwen van een goede reservoircomputer. Afhankelijk van de taak kan het zware werk worden gedaan door de inputbedrading, door de dynamica van het reservoir, of door de eenvoudige lineaire outputlaag. Veel taken werken goed met zwak verbonden, nauwelijks niet-lineaire reservoirs, mits hun toestanden rijk genoeg zijn zodat de outputlaag ze kan decoderen. Andere taken vereisen sterkere niet-lineariteit om beslissingsgrenzen te buigen of om complexe digitale regels na te bootsen. Voor de niet‑specialistische lezer is de kernboodschap dat nuttig “geheugen” en flexibel gedrag geen wild chaotische interne activiteit vereisen. In plaats daarvan kan zorgvuldig afgestemde eenvoud, gecombineerd met een slimme outputlaag, volstaan om de interne werking van deze eens zo ondoorgrondelijke systemen te verhelderen.
Bronvermelding: Metzner, C., Kinfe, T., Maier, A. et al. Illuminating the black box of reservoir computing. Sci Rep 16, 15500 (2026). https://doi.org/10.1038/s41598-026-53098-y
Trefwoorden: reservoir computing, recurrente neurale netwerken, sequentieel geheugen, niet-lineaire dynamica, voorspelling van cellulaire automaat