Clear Sky Science · es
Iluminando la caja negra del reservoir computing
Un vistazo a un tipo ingenioso de red neuronal
Muchos sistemas de IA modernos son impresionantes pero enigmáticos, sobre todo cuando procesan información que se desarrolla en el tiempo, como el habla, los gestos o el clima cambiante. Este estudio investiga uno de esos enfoques, llamado reservoir computing, para averiguar cuán simples pueden ser estos sistemas sin perder eficacia y qué decisiones de diseño importan realmente según el tipo de tarea.
Cómo un reservoir computer procesa la información
En un reservoir computer, las señales entrantes primero atraviesan una red fija de unidades interconectadas, el reservorio, y luego pasan a una capa de salida entrenable que produce la respuesta final. La peculiaridad es que solo se entrena la última capa, mientras que las conexiones internas son en su mayoría aleatorias y permanecen sin modificar. Los autores tratan este montaje como una máquina que transforma una secuencia de entrada en una secuencia de salida, y varían de forma sistemática cuántas unidades tiene el reservorio, cuán fuertemente se influyen entre sí y cuán brusca es la respuesta de cada unidad a su entrada. También experimentan con distintas formas de la curva de respuesta, incluidas curvas suaves, líneas rectas simples y un comportamiento conmutador de encendido/apagado, así como con diferentes maneras de cablear las entradas hacia el reservorio.
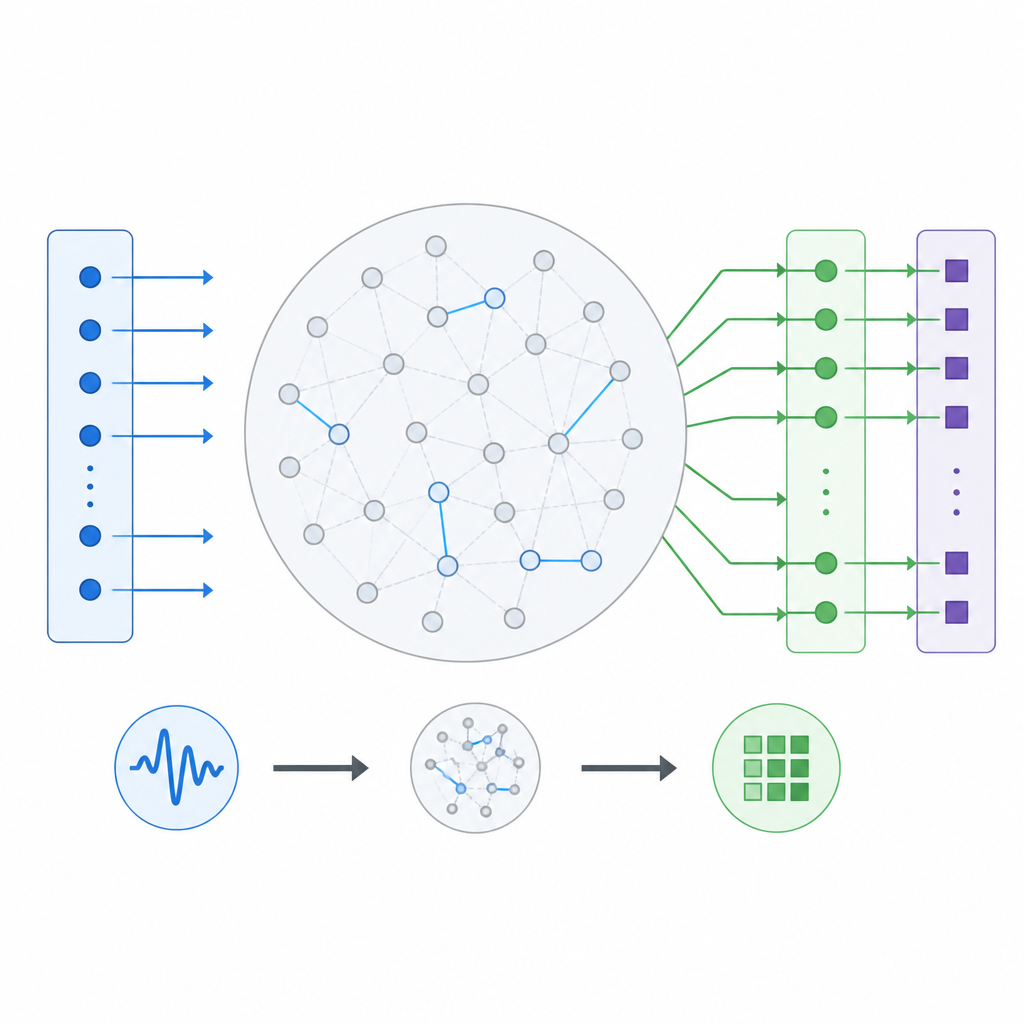
Dinámicas simples que aún pueden recordar el pasado
Un conjunto de pruebas solicita al sistema recordar y luego reproducir secuencias cortas aleatorias de números. Para esta tarea de “memorización de secuencias”, el reservorio debe conservar trazas desvanecientes de entradas anteriores sin que queden completamente sobrescritas por las nuevas. Los investigadores encuentran que existe un punto óptimo: si las conexiones internas son demasiado débiles, las señales no se extienden más allá de unas pocas unidades y la memoria falla; si son demasiado fuertes, la actividad se vuelve irregular y caótica, y las trazas útiles se pierden en el ruido. El buen rendimiento se da en un régimen tranquilo donde la actividad se asienta rápidamente tras cada entrada y donde las unidades se comportan casi linealmente. Sorprendentemente, en esta tarea centrada en la memoria, usar unidades puramente lineales, sin no linealidad incorporada, puede funcionar incluso mejor que la curva de compresión habitual.
Cuando se necesitan fronteras de decisión curvadas
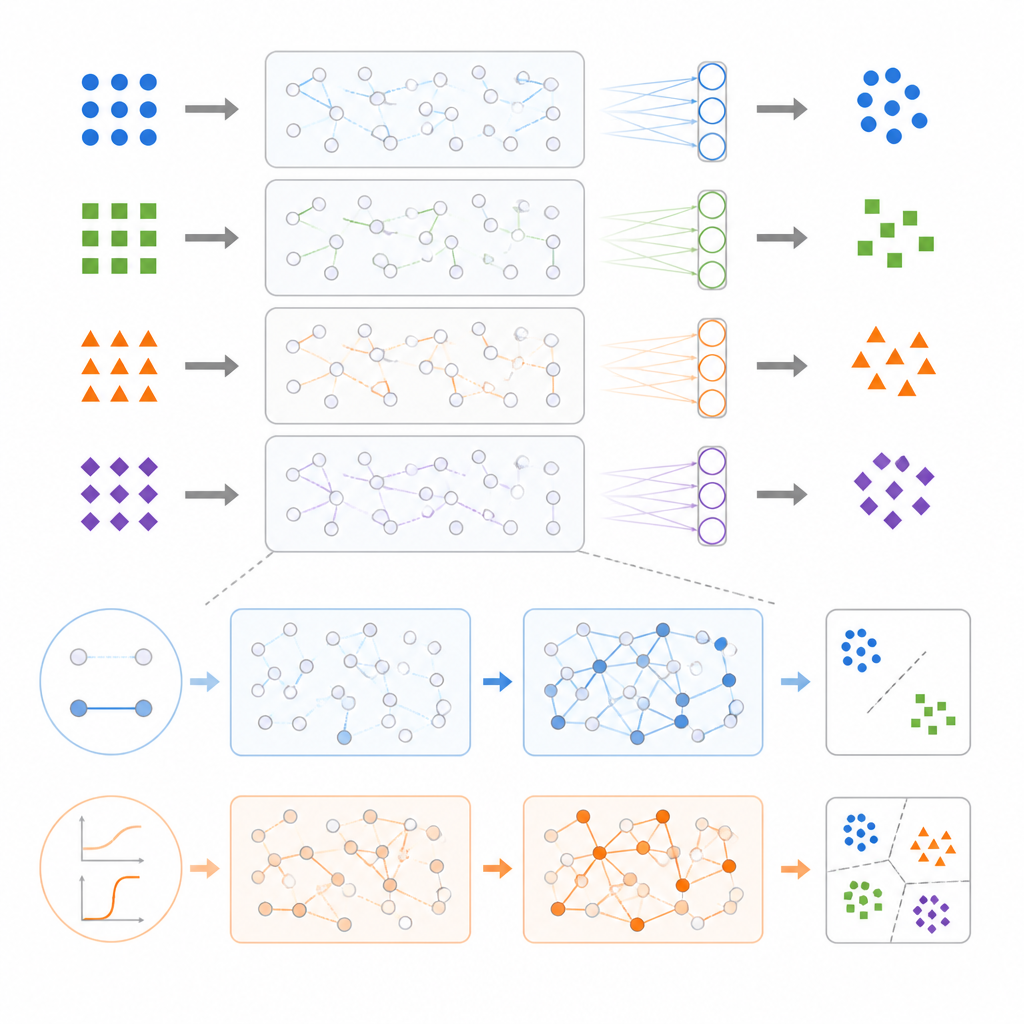
Otra tarea se centra en la clasificación en lugar de la memoria. Aquí el sistema observa puntos individuales en un plano bidimensional y debe asignarlos a una de dos clases dispuestas en un tablero de ajedrez de pequeñas regiones cuadradas. Esto exige fronteras de decisión curvadas, porque líneas rectas no pueden dividir el plano en ese patrón de parches. En este contexto no temporal, el entramado recurrente del reservorio apenas influye, y el sistema se comporta como una red feedforward con una capa oculta fija. Lo que resulta crucial es la forma y pendiente de las curvas de respuesta de las unidades. Respuestas no lineales suaves, escaladas a una pendiente intermedia, permiten que la capa de salida trace fronteras que siguen de cerca el patrón del tablero, mientras que respuestas lineales simples o conmutadores abruptos rinden mal.
Aprender las reglas de un mundo digital
Los autores plantean luego un problema no temporal más exigente: predecir el siguiente estado de un pequeño autómata celular, un universo digital sencillo donde cada célula se enciende o apaga según el patrón de sus vecinas. Para tener éxito, el reservoir computer debe inferir la regla de actualización oculta a partir de ejemplos y aplicarla a patrones nuevos que nunca ha visto. Aquí, tanto la estructura recurrente como la no linealidad suave son importantes, y los reservorios más grandes ayudan considerablemente. Con suficientes unidades y una pendiente de respuesta bien elegida, el sistema puede alcanzar precisión perfecta para reglas complejas, reproduciendo efectivamente el comportamiento del autómata paso a paso.
Generar secuencias a demanda
En un último grupo de experimentos, al sistema se le pide no solo reconocer o predecir, sino generar secuencias completas. Una breve entrada que indica una de varias clases debería disparar al reservorio para que siga una trayectoria específica de clase a través de sus estados internos, que la capa de salida convierte en una secuencia objetivo de números. De nuevo, existe un punto medio óptimo: se necesita cierto acoplamiento interno y no linealidad para crear trayectorias ricas que duren muchos pasos, pero un acoplamiento excesivamente fuerte empuja al sistema hacia un comportamiento caótico que difumina las diferencias entre clases y confunde la capa de salida.
Qué implica esto para diseñar sistemas más inteligentes
En conjunto, el estudio muestra que no existe una única receta para construir un buen reservoir computer. Dependiendo de la tarea, el trabajo pesado puede recaer en el cableado de entradas, en la dinámica del reservorio o en la simple capa de salida lineal. Muchas tareas funcionan bien con reservorios débilmente conectados y apenas no lineales, siempre que sus estados sean lo bastante ricos para que la capa de salida los decodifique. Otras tareas exigen mayor no linealidad para curvar fronteras de decisión o emular reglas digitales complejas. Para el lector general, el mensaje clave es que la “memoria” útil y el comportamiento flexible no requieren una actividad interna salvajemente caótica. En su lugar, una simplicidad cuidadosamente afinada, junto con una capa de salida inteligente, puede ser suficiente para iluminar el funcionamiento interno de estos sistemas que antes eran cajas negras.
Cita: Metzner, C., Kinfe, T., Maier, A. et al. Illuminating the black box of reservoir computing. Sci Rep 16, 15500 (2026). https://doi.org/10.1038/s41598-026-53098-y
Palabras clave: reservoir computing, redes neuronales recurrentes, memoria de secuencias, dinámica no lineal, predicción de autómata celular