Clear Sky Science · fr
Éclairer la boîte noire de l’informatique en réservoir
Un coup d’œil à l’intérieur d’un type ingénieux de réseau neuronal
Beaucoup de systèmes d’IA modernes sont impressionnants mais mystérieux, en particulier quand ils traitent de l’information qui se déploie dans le temps, comme la parole, les gestes ou l’évolution du temps. Cette étude examine de près l’une de ces approches, appelée informatique en réservoir, pour déterminer à quel point ces systèmes peuvent être simples tout en restant performants, et quelles décisions de conception comptent vraiment selon le type de tâche.
Comment un ordinateur en réservoir traite l’information
Dans un ordinateur en réservoir, les signaux entrants traversent d’abord un réseau fixe d’unités interconnectées, le réservoir, puis atteignent une couche de sortie entraînable qui produit la réponse finale. La particularité est que seule la dernière couche est entraînée, tandis que les connexions internes sont pour l’essentiel aléatoires et laissées intactes. Les auteurs considèrent cette configuration comme une machine qui transforme une séquence d’entrée en une séquence de sortie, et ils varient systématiquement le nombre d’unités du réservoir, la force avec laquelle elles s’influencent mutuellement et la raideur de la réponse de chaque unité à son entrée. Ils testent aussi différentes formes de courbes de réponse, y compris des courbes lisses, des lignes droites simples et des comportements commutateurs tout‑ou‑rien, ainsi que différentes manières de connecter les entrées au réservoir.
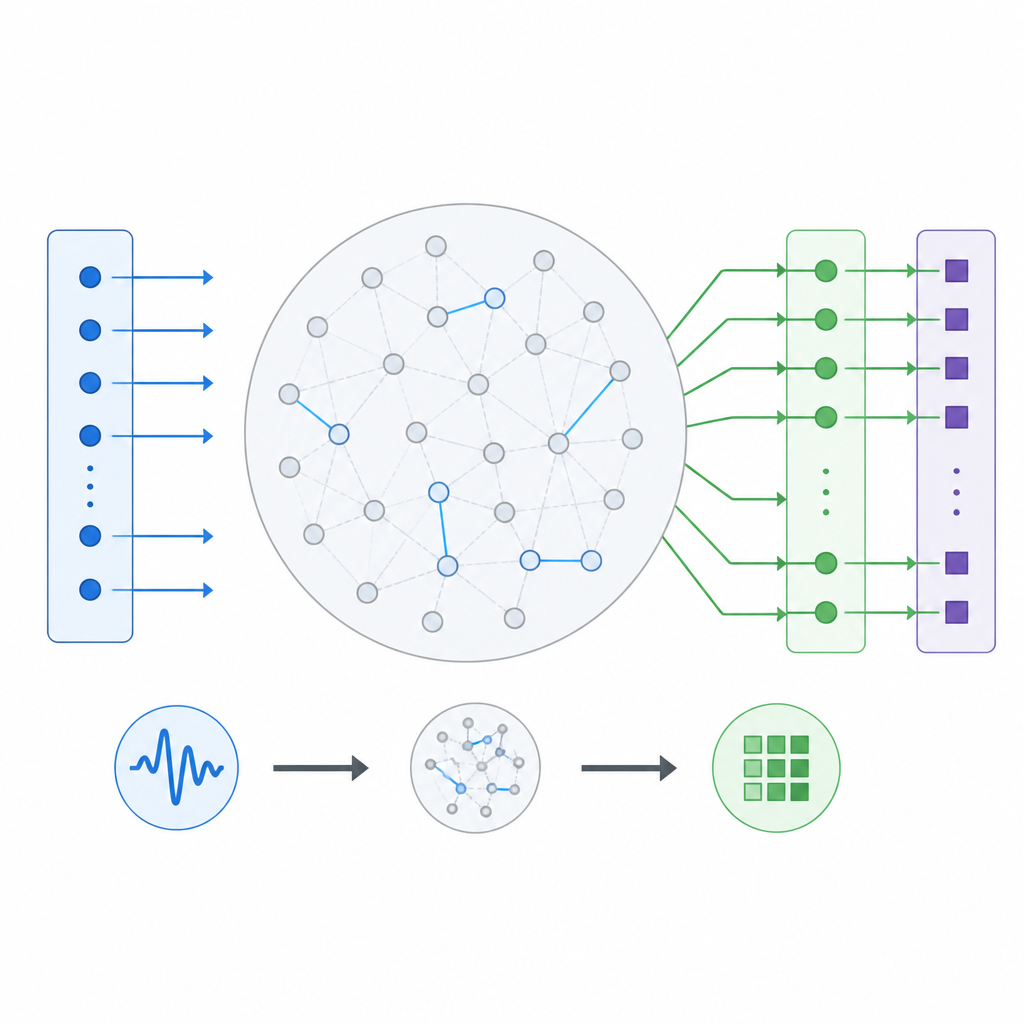
Des dynamiques simples peuvent quand même se souvenir du passé
Un jeu de tests demande au système de mémoriser puis de reproduire de courtes séquences aléatoires de nombres. Pour cette tâche de « mémorisation de séquence », le réservoir doit conserver des traces effaçables des entrées précédentes sans qu’elles soient complètement écrasées par les nouvelles. Les chercheurs constatent qu’il existe un point optimal : si les connexions internes sont trop faibles, les signaux ne se propagent qu’à quelques unités et la mémoire échoue ; si elles sont trop fortes, l’activité devient irrégulière et chaotique, et les traces utiles se perdent dans le bruit. De bonnes performances apparaissent dans un régime calme où l’activité se stabilise rapidement après chaque entrée et où les unités se comportent presque linéairement. De manière surprenante, pour cette tâche centrée sur la mémoire, utiliser des unités purement linéaires, sans non‑linéarité intégrée, peut même fonctionner mieux que la classique courbe d’écrasement.
Quand des frontières de décision courbes sont nécessaires
Une autre tâche porte sur la classification plutôt que sur la mémoire. Ici, le système voit des points isolés dans un plan bidimensionnel et doit les assigner à l’une de deux classes disposées en damier de petites régions carrées. Cela exige des frontières de décision courbes, car des lignes droites ne peuvent pas découper le plan en un tel patchwork. Dans ce cadre non temporel, le câblage récurrent du réservoir compte à peine, et le système se comporte comme un réseau feedforward avec une couche cachée fixe. Ce qui s’avère crucial, c’est la forme et la raideur des courbes de réponse des unités. Des réponses non linéaires et lisses, réglées sur une raideur intermédiaire, permettent à la couche de sortie de tracer des frontières qui suivent fidèlement le motif en damier, tandis que des réponses linéaires simples ou des commutateurs durs performent mal.
Apprendre les règles d’un monde numérique
Les auteurs mettent ensuite le système au défi avec un problème non temporel plus difficile : prédire l’état suivant d’un petit automate cellulaire, un univers numérique simple où chaque cellule s’allume ou s’éteint selon le motif de ses voisines. Pour réussir, l’ordinateur en réservoir doit inférer la règle de mise à jour cachée à partir d’exemples et l’appliquer à de nouveaux motifs jamais vus. Ici, la structure récurrente et une non‑linéarité lisse sont importantes, et des réservoirs plus grands aident considérablement. Avec suffisamment d’unités et une raideur de réponse bien choisie, le système peut atteindre une précision parfaite pour des règles complexes, reproduisant effectivement le comportement de l’automate pas à pas.
Générer des séquences à la demande
Dans un dernier ensemble d’expériences, on demande au système non seulement de reconnaître ou prédire, mais de générer des séquences entières. Une brève entrée indiquant l’une des classes doit déclencher le réservoir pour qu’il suive une trajectoire interne spécifique à la classe, que la couche de sortie transforme en une séquence cible de nombres. Là encore, il existe un compromis optimal : un certain couplage interne et une non‑linéarité sont nécessaires pour créer des trajectoires riches qui durent de nombreuses étapes, mais un couplage trop fort pousse le système vers un comportement chaotique qui efface les différences entre classes et embrouille la couche de sortie.
Ce que cela implique pour la conception de systèmes plus intelligents
Globalement, l’étude montre qu’il n’existe pas de recette universelle pour construire un bon ordinateur en réservoir. Selon la tâche, le travail lourd peut être assuré par le câblage d’entrée, par la dynamique du réservoir ou par la simple couche de sortie linéaire. De nombreuses tâches fonctionnent bien avec des réservoirs faiblement connectés et à peine non‑linéaires, tant que leurs états sont suffisamment riches pour être décodés par la couche de sortie. D’autres tâches exigent une non‑linéarité plus marquée pour courber des frontières de décision ou émuler des règles numériques complexes. Pour le lecteur non spécialiste, le message clé est que la « mémoire » utile et le comportement flexible ne nécessitent pas une activité interne follement chaotique. Au contraire, une simplicité soigneusement réglée, associée à une couche de sortie bien conçue, peut suffire à éclairer les mécanismes internes de ces systèmes autrefois boîte noire.
Citation: Metzner, C., Kinfe, T., Maier, A. et al. Illuminating the black box of reservoir computing. Sci Rep 16, 15500 (2026). https://doi.org/10.1038/s41598-026-53098-y
Mots-clés: informatique en réservoir, réseaux neuronaux récurrents, mémoire de séquence, dynamique non linéaire, prédiction d’automate cellulaire