Clear Sky Science · nl
Hiërarchische boomgestructureerde belief rule base voor foutdiagnose van complexe elektromechanische systemen
Slimmere veiligheidschecks voor machines
Moderne treinen, fabrieken en vliegtuigen vertrouwen op complexe elektromechanische systemen vol sensoren en besturingscircuits. Wanneer een verborgen fout ongemerkt blijft, kunnen de gevolgen kostbaar of zelfs gevaarlijk zijn. Dit artikel presenteert een nieuwe manier om zulke problemen vroegtijdig te signaleren, met een gelaagd redeneersysteem dat menselijke engineeringinzichten combineert met machinegegevens, terwijl de logica transparant genoeg blijft voor deskundigen om te begrijpen en te vertrouwen.
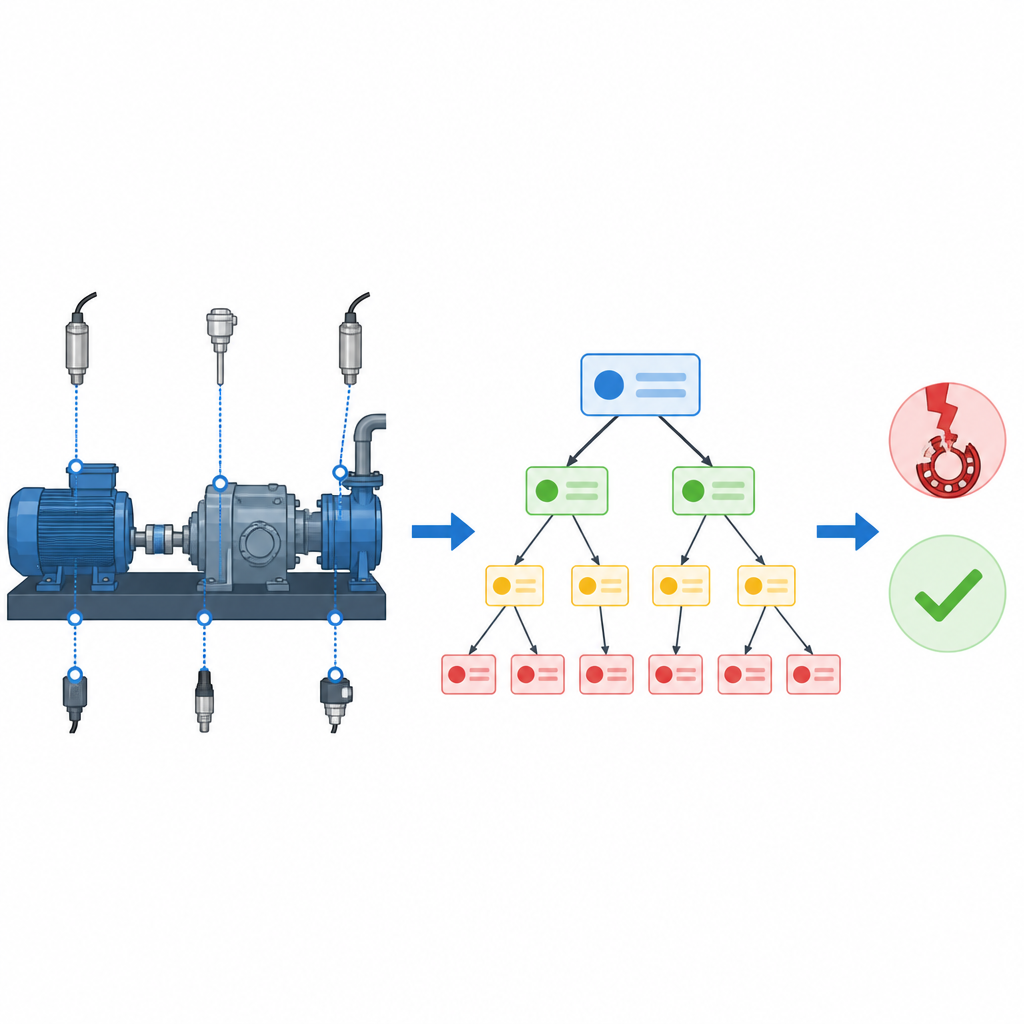
Waarom verborgen fouten moeilijk te ontdekken zijn
Grote machines, zoals permanente magneetmotoren in hogesnelheidstreinen, zijn gebouwd om zeer betrouwbaar te zijn. Werkelijke fouten zijn zeldzaam, dus er zijn weinig foutgevallen om standaard machine learning-modellen mee te trainen. Tegelijkertijd zijn de signalen van deze systemen rijk en verward: veel sensoren, veel bedrijfsomstandigheden en fouten die stabiel, langzaam groeiend of plots en willekeurig kunnen zijn. Traditionele op natuurkunde gebaseerde modellen zijn vaak te moeilijk in detail te maken, en puur datagedreven modellen kunnen als black boxes functioneren: ze geven nauwkeurige antwoorden zonder hun redenering uit te leggen. Bestaande regelsystemen die proberen expertsregels met data te mengen lopen vaak tegen een ander probleem aan: naarmate het aantal sensorfeatures groeit, explodeert het aantal mogelijke regels, waardoor de aanpak te omvangrijk wordt voor praktisch gebruik.
Een gelaagde boom van mensvriendelijke regels
De auteurs pakken deze regel-explosie rechtstreeks aan door de organisatie van de regels te herontwerpen. In plaats van één enorme platte regeltabel die elke combinatie van features probeert, bouwen ze een boom van kleinere regelblokken. Elk klein blok kijkt naar slechts een paar zorgvuldig gekozen features en geeft een belief over in welke fouttoestand de machine zich bevindt. Deze blokken zijn hiërarchisch gerangschikt, zodat blokken op hoog niveau de informatiefste features behandelen, terwijl lagere niveaus de beslissing verfijnen met extra details. Een evolutionair zoekproces verkent automatisch veel mogelijke boomindelingen en behoudt de versies die nauwkeurigheid en eenvoud in balans houden, zodat ingenieurs niet zelf de hele structuur met de hand hoeven te ontwerpen.
De juiste signalen kiezen om te volgen
Al vóór het bouwen van de boom werkt de methode aan het kiezen van de meest bruikbare sensorfeatures. Ze meet hoe sterk elke feature samenhangt met de fouttypen met behulp van ideeën uit de informatietheorie, en past deze scores vervolgens aan met expertise over hoe fouten daadwerkelijk stromen, trillingen en andere signalen beïnvloeden. Bijvoorbeeld: een feature die vaak verandert met snelheid of belasting maar niet bij fouten, wordt afgewaardeerd, terwijl een feature die een specifiek foutpatroon volgt, wordt versterkt. De uiteindelijke score voor elke feature mengt databewijs, fysisch inzicht en eerdere ervaring over verschillende bedrijfsomstandigheden. Alleen de hoogst gerangschikte features worden behouden, waarmee de inputruimte wordt verkleind en onnodige regels in de eerste plaats worden voorkomen.
Overlappende aanwijzingen combineren zonder dubbel te tellen
Omdat de boom meerdere regelblokken bevat die op gerelateerde signalen kunnen vertrouwen, zijn hun uitkomsten niet onafhankelijk. Als deze overlap wordt genegeerd, kan een standaard fusie methode per ongeluk hetzelfde bewijs meerdere keren meetellen en de uiteindelijke diagnose vertekenen. Om dit te voorkomen passen de auteurs een raamwerk genaamd MAKER aan, dat meet hoe vergelijkbaar de uitkomsten van verschillende blokken zijn, inclusief subtiele niet-lineaire verbanden. Elk blok krijgt een betrouwbaarheid toegewezen op basis van zijn eerdere nauwkeurigheid, een gewicht dat het belang weerspiegelt, en een correlatiemaat die aangeeft hoeveel van zijn informatie al elders aanwezig is. Deze factoren worden samen gebruikt om aan te passen hoeveel elk blok de uiteindelijke beslissing beïnvloedt, zodat sterke maar redundante aanwijzingen worden afgezwakt terwijl unieke, betrouwbare aanwijzingen meer gewicht krijgen.
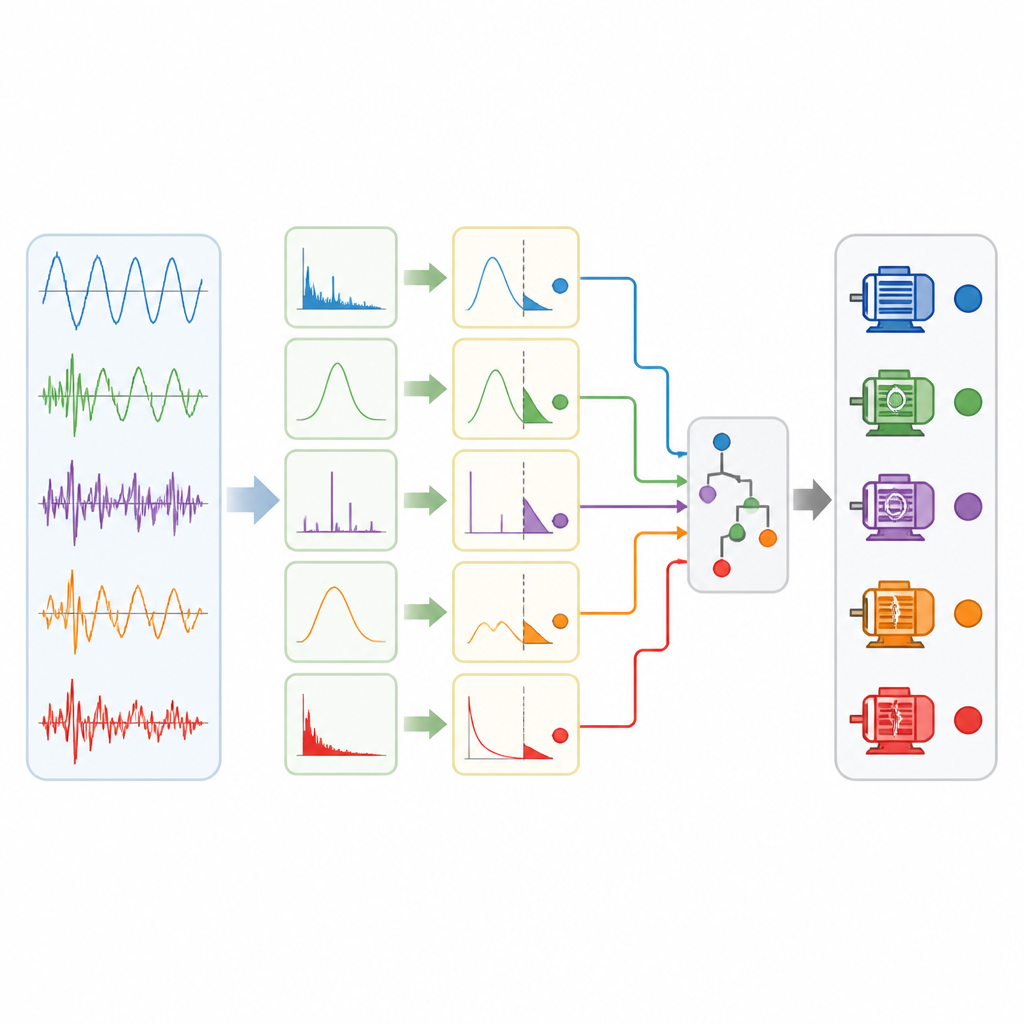
De methode testen op echte motoren
Om hun aanpak te testen gebruikten de onderzoekers een echt elektrisch aandrijfsysteem rond een permanente magneetsynchroonmotor, vergelijkbaar met die in hogesnelheidstreinen. Ze injecteerden vier typen sensorsfouten in de stroommetingen: constante offset, verkeerde versterking, langzame drift over tijd en willekeurige intermitterende pieken, naast een gezonde toestand. Uit eenvoudige tijdgebaseerde statistieken van de stroom, zoals energie- en piekgerelateerde maten, selecteerde de methode een compacte set van zes features en bouwde een hiërarchische regeltree. Met slechts 480 datapunten bereikte het dezelfde nauwkeurigheid of overtrof die van meerdere geavanceerde machine learning-modellen, terwijl het veel minder regels gebruikte dan een traditioneel belief rule-systeem en elk stap van het redeneren traceerbaar hield. De boomstructuur maakte ook trainen en realtime inferentie sneller, een belangrijk punt voor industriële monitoring.
Wat dit betekent voor veiligere machines
In eenvoudige bewoordingen toont de studie aan dat complexe machines bewaakt kunnen worden met een regelsysteem dat beheersbaar blijft, zijn keuzes uitlegt en goed werkt zelfs wanneer er weinig foutvoorbeelden zijn. Door eerst de meest informatieve signalen te kiezen, vervolgens kleine regelblokken in een boom te organiseren en hun uitkomsten op een correlatiebewuste manier te fusen, voorkomt de methode de gebruikelijke explosie in het aantal regels en de ondoorzichtigheid van veel leermodellen. Voor exploitanten van treinen, fabrieken en andere veiligheidkritieke systemen biedt dit een weg naar foutdiagnosetools die zowel nauwkeurig als begrijpelijk zijn, waardoor menselijke deskundigen geautomatiseerde waarschuwingen kunnen vertrouwen en verfijnen in plaats van ze blindelings te accepteren.
Bronvermelding: Chen, M., Su, T., Cheng, C. et al. Hierarchical tree-structured belief rule base for fault diagnosis of complex electromechanical systems. Sci Rep 16, 15267 (2026). https://doi.org/10.1038/s41598-026-45997-x
Trefwoorden: foutdiagnose, elektromechanische systemen, belief rule base, sensorsfouten, hiërarchische modellering