Clear Sky Science · fr
Base de règles de croyance arborescente hiérarchique pour le diagnostic des pannes des systèmes électromécaniques complexes
Contrôles de sécurité plus intelligents pour les machines
Les trains modernes, les usines et les avions reposent sur des systèmes électromécaniques complexes bourrés de capteurs et d’électronique de commande. Quand une panne cachée passe entre les mailles du filet, les conséquences peuvent être coûteuses voire dangereuses. Cet article présente une nouvelle manière de détecter ces problèmes tôt, en utilisant un système de raisonnement en couches qui mêle l’expertise humaine en ingénierie aux données machine, tout en gardant une logique suffisamment transparente pour que les spécialistes puissent la comprendre et lui faire confiance.
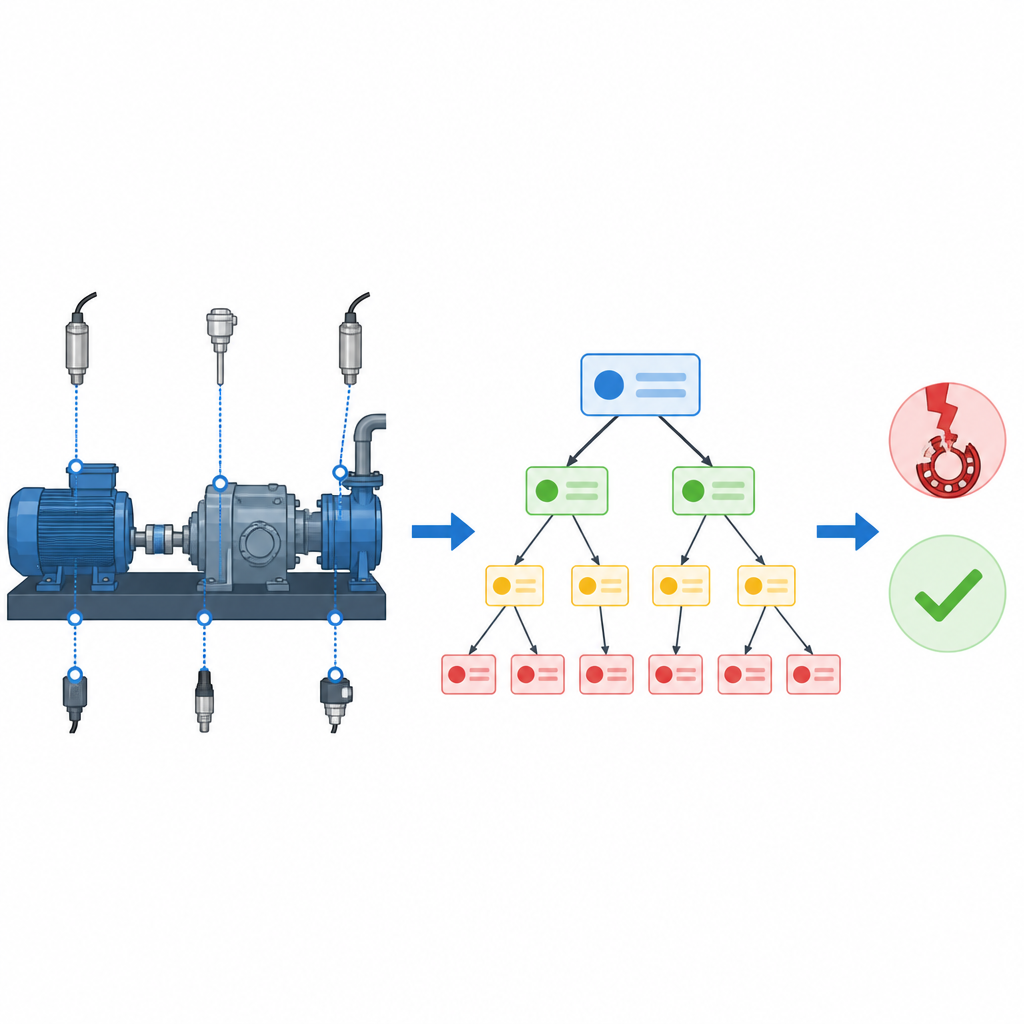
Pourquoi les pannes cachées sont difficiles à détecter
Les grandes machines, comme les moteurs à aimant permanent des trains à grande vitesse, sont conçues pour être très fiables. Les pannes réelles sont rares, de sorte qu’il existe peu d’exemples défaillants pour entraîner les modèles d’apprentissage automatique classiques. Parallèlement, les signaux issus de ces systèmes sont riches et emmêlés : de nombreux capteurs, de nombreuses conditions de fonctionnement, et des pannes qui peuvent être constantes, croissantes lentement ou soudaines et aléatoires. Les modèles physiques traditionnels peuvent être trop difficiles à construire en détail, et les modèles purement basés sur les données peuvent agir comme des boîtes noires, donnant des réponses précises sans expliquer leur raisonnement. Les systèmes à base de règles existants, qui cherchent à mélanger règles d’experts et données, rencontrent souvent un autre obstacle : quand le nombre de caractéristiques de capteurs augmente, le nombre de règles possibles explose, rendant l’approche trop encombrante pour l’usage pratique.
Un arbre hiérarchique de règles compréhensibles
Les auteurs s’attaquent directement à cette explosion de règles en remodelant l’organisation des règles. Plutôt que d’avoir une énorme table de règles plate qui essaye toutes les combinaisons de caractéristiques, ils construisent un arbre de petits blocs de règles. Chaque petit bloc n’examine que quelques caractéristiques soigneusement choisies et produit une croyance sur l’état de panne du système. Ces blocs sont organisés en hiérarchie, de sorte que les blocs de haut niveau traitent les caractéristiques les plus informatives, tandis que les blocs de niveau inférieur affinent la décision avec des détails supplémentaires. Un processus de recherche évolutionnaire explore automatiquement de nombreuses dispositions d’arbre possibles et conserve celles qui équilibrent précision et simplicité, si bien que les ingénieurs n’ont pas à concevoir manuellement toute la structure.
Choisir les bons signaux à surveiller
Même avant de construire l’arbre, la méthode s’attache à sélectionner les caractéristiques de capteurs les plus utiles. Elle mesure à quel point chaque caractéristique est liée aux types de pannes en s’inspirant de la théorie de l’information, puis ajuste ces scores avec la connaissance experte sur la façon dont les pannes affectent réellement les courants, les vibrations et autres signaux. Par exemple, une caractéristique qui change souvent avec la vitesse ou la charge mais pas avec les pannes est dévalorisée, tandis qu’une caractéristique connue pour suivre un motif de panne spécifique est valorisée. Le score final de chaque caractéristique combine preuves issues des données, intuition physique et expérience passée sur diverses conditions de fonctionnement. Seules les caractéristiques les mieux classées sont conservées, réduisant l’espace d’entrée et empêchant la création de règles inutiles dès le départ.
Combiner des indices redondants sans double comptage
Parce que l’arbre contient plusieurs blocs de règles qui peuvent s’appuyer sur des signaux liés, leurs sorties ne sont pas indépendantes. Si ce recoupement est ignoré, une méthode de fusion standard peut involontairement compter plusieurs fois la même preuve et fausser le diagnostic final. Pour éviter cela, les auteurs adaptent un cadre appelé MAKER, qui mesure la similarité entre les sorties des différents blocs, y compris les liens non linéaires subtils. Chaque bloc se voit attribuer une fiabilité basée sur sa précision passée, un poids reflétant son importance, et une mesure de corrélation traduisant la part d’information déjà présente ailleurs. Ces facteurs sont utilisés conjointement pour ajuster l’influence de chaque bloc sur la décision finale, de sorte que les indices forts mais redondants soient atténués tandis que les indices uniques et fiables aient plus de poids.
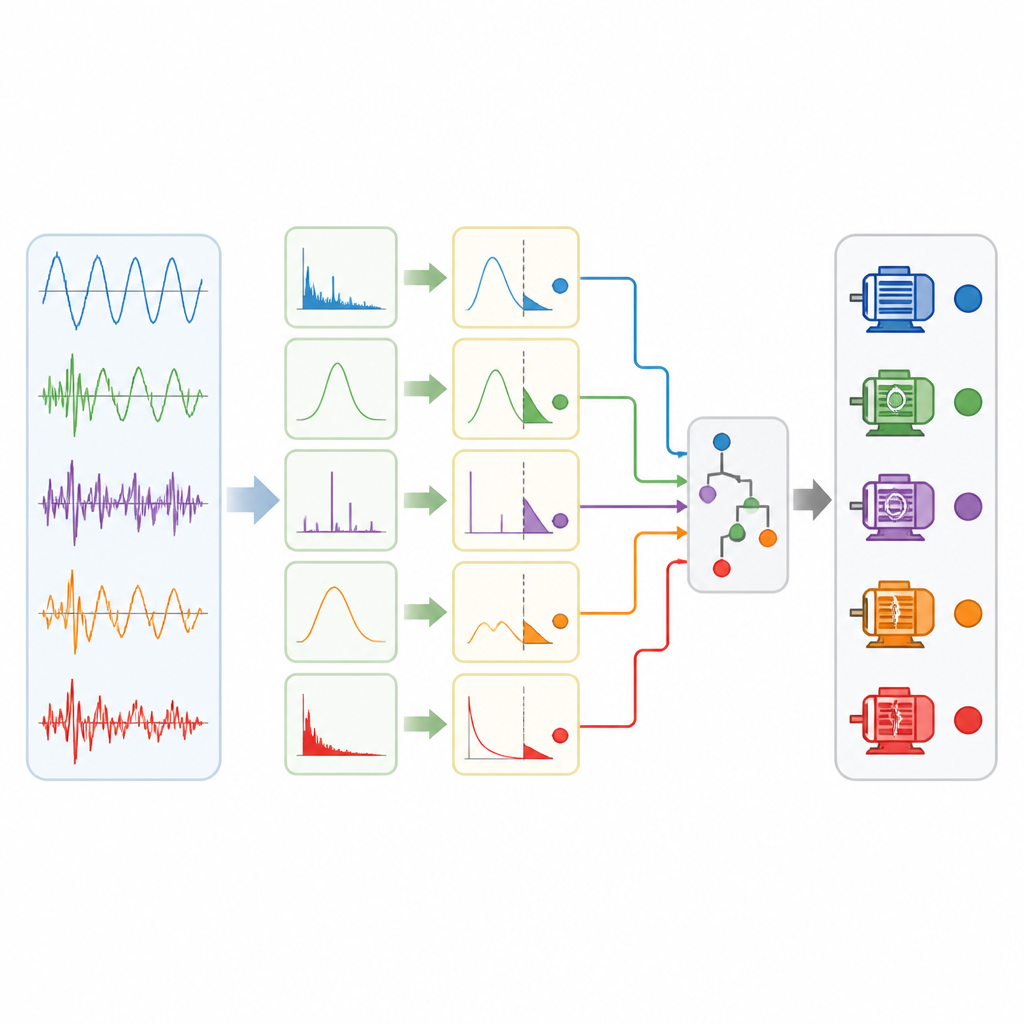
Validation de la méthode sur des moteurs réels
Pour tester leur approche, les chercheurs ont utilisé un système d’entraînement électrique réel basé sur un moteur synchrone à aimant permanent, semblable à ceux employés dans les trains à grande vitesse. Ils ont injecté quatre types de pannes de capteurs dans les mesures de courant : décalage constant, gain incorrect, dérive lente dans le temps et pointes intermittentes aléatoires, ainsi qu’un état sain. À partir de simples statistiques temporelles du courant, telles que l’énergie et des mesures liées aux crêtes, la méthode a sélectionné un ensemble compact de six caractéristiques et construit un arbre de règles hiérarchique. Sur seulement 480 échantillons de données, elle a égalé ou dépassé la précision de plusieurs modèles avancés d’apprentissage automatique, tout en utilisant beaucoup moins de règles qu’un système de règles de croyance traditionnel et en gardant chaque étape du raisonnement traçable. La structure en arbre a aussi rendu l’entraînement et l’inférence en temps réel plus rapides, un point important pour la surveillance industrielle.
Ce que cela signifie pour des machines plus sûres
En termes simples, l’étude montre que des machines complexes peuvent être surveillées avec un système de règles qui reste maîtrisable, explique ses choix et fonctionne bien même lorsqu’il y a peu d’exemples de pannes. En choisissant d’abord les signaux les plus informatifs, puis en organisant de petits blocs de règles en arbre et en fusionnant leurs sorties de manière consciente des corrélations, la méthode évite l’explosion habituelle du nombre de règles et l’opacité de nombreux modèles d’apprentissage. Pour les exploitants de trains, d’usines et d’autres systèmes critiques pour la sécurité, cela ouvre la voie à des outils de diagnostic de panne à la fois précis et compréhensibles, aidant les experts humains à faire confiance aux alertes automatisées et à les affiner plutôt que de les accepter aveuglément.
Citation: Chen, M., Su, T., Cheng, C. et al. Hierarchical tree-structured belief rule base for fault diagnosis of complex electromechanical systems. Sci Rep 16, 15267 (2026). https://doi.org/10.1038/s41598-026-45997-x
Mots-clés: diagnostic de panne, systèmes électromécaniques, base de règles de croyance, pannes de capteurs, modélisation hiérarchique