Clear Sky Science · nl
De invloed van gedaante op dynamische herkenning van eigen gezicht of dat van een vriend
Waarom het zien van ons eigen gezicht ertoe doet
We zien ons eigen gezicht een leven lang in spiegels en foto’s, maar zelden in beweging zoals anderen dat doen. Deze studie stelt een ogenschijnlijk eenvoudige vraag met grote implicaties: herkennen we ons eigen bewegende gezicht op dezelfde manier als dat van een goede vriend? Het antwoord werpt licht op hoe de hersenen een gevoel van zelf construeren, en gebruikt geavanceerde deepfake‑hulpmiddelen niet om te misleiden, maar als een nauwkeurig instrument om gedaante en beweging uit elkaar te halen.
Twee soorten informatie in een gezicht
Bij herkenning vertrouwen we op minstens twee soorten visuele informatie. De ene is gedaante: de kaaklijn, de afstand tussen de ogen, de vorm van de neus. De andere is beweging: de manier waarop de mond beweegt tijdens spreken, of de karakteristieke kanteling van het hoofd. Van vrienden en beroemdheden zien we zowel gedaante als beweging vaak — in het dagelijks leven en in de media. Van ons eigen gezicht zien we daarentegen meestal een stilstaand spiegelbeeld en slechts korte, in spiegelbeeld weergegeven bewegingen. Die asymmetrie roept een vraag op: is het neurale beeld van de beweging van het eigen gezicht net zo rijk als dat van andere bekende personen, of vertrouwen we bij het beslissen “dat ben ik” sterker op de statische gedaante?
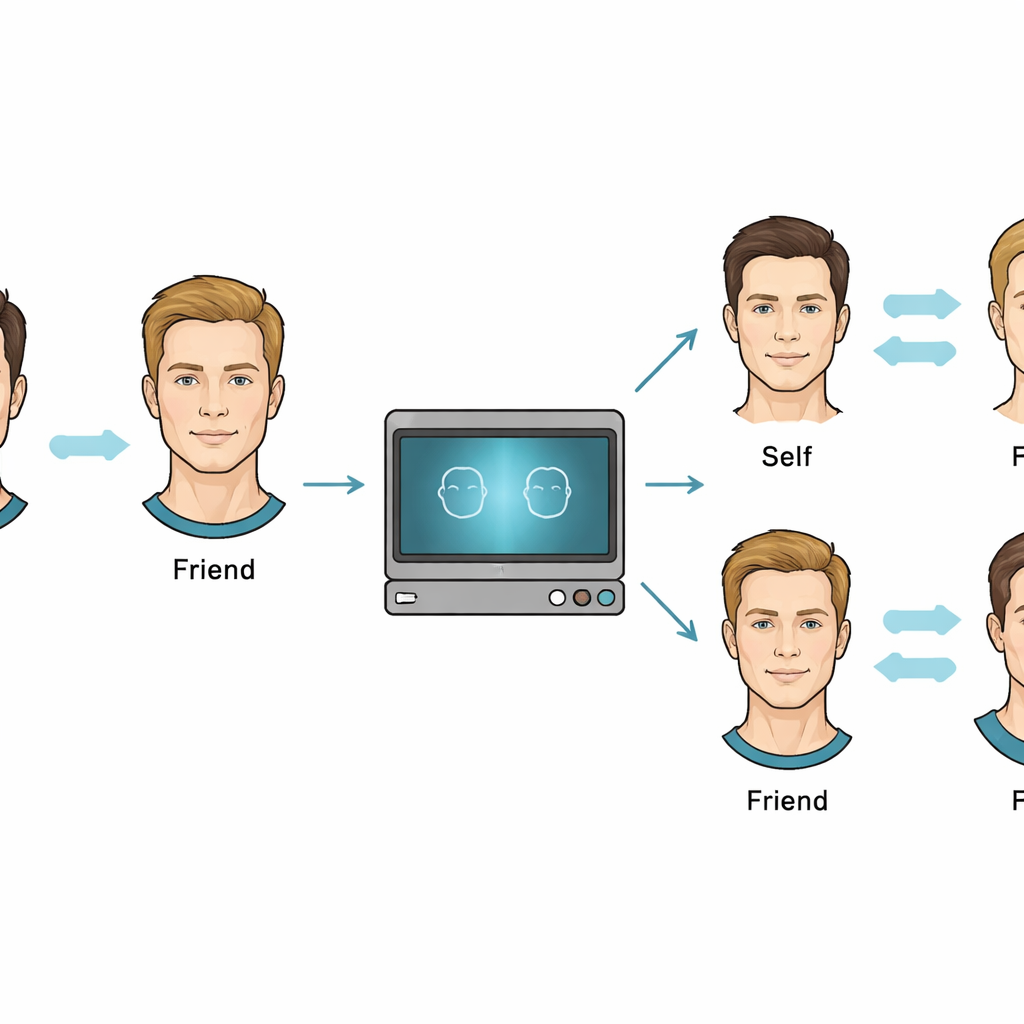
Deepfakes gebruiken als wetenschappelijk instrument
Om gedaante en beweging te scheiden, namen de onderzoekers korte video’s op van jonge mannen die zinnen voorlazen. Elke deelnemer werd gekoppeld aan een echte vriend, zodat iemands gezicht zowel als “eigen” als “vriend” kon dienen, afhankelijk van wie keek. Deepfake‑software werd vervolgens niet gebruikt om hoaxes te maken, maar om gezichtscontouren te verwisselen terwijl de oorspronkelijke beweging behouden bleef. Daardoor kon het team uiterst realistische clips genereren waarin bijvoorbeeld de gezichtsbewegingen van een vriend werden afgespeeld op de gedaante van de deelnemer, of andersom. Deelnemers keken naar deze clips in een verduisterde kamer en drukten na elke clip op een toets om aan te geven of de beweging tot henzelf of tot hun vriend behoorde, met de instructie zoveel mogelijk de statische verschijning te negeren.
Wanneer gedaante en beweging overeenkomen — of botsen
In het eerste experiment waren er vier duidelijke combinaties: eigen gedaante met eigen beweging, eigen gedaante met beweging van de vriend, vriend‑gedaante met eigen beweging en vriend‑gedaante met vriend‑beweging. De resultaten toonden dat mensen bewegingen van zichzelf en van vrienden betrouwbaar konden onderscheiden. Voor vriendbeweging veranderde de prestatie nauwelijks, ongeacht of het zichtbare gezicht eruitzag als de vriend of als de deelnemer; het bewegingspatroon zelf volstond. Voor eigen beweging was herkenning veel beter wanneer de zichtbare gedaante er ook uitzag als het eigen gezicht. Toen eigen beweging werd getoond op een vriend‑gedaante, daalde de nauwkeurigheid merkbaar, wat suggereert dat mensen moeite hebben hun kenmerkende bewegingen als hun eigen beweging te herkennen tenzij de omliggende gedaante ook aangeeft “dit ben ik.”
Gezichten mengen om afhankelijkheid van gedaante te meten
Het tweede experiment verdiepte dit idee door geleidelijk tussen de twee gedaantes te morphen. In plaats van alleen puur eigen of puur vriendengezichten maakten de onderzoekers elf tussenliggende niveaus, van 100% vriend‑gedaante tot 100% eigen‑gedaante, terwijl de bewegingsinformatie vast bleef als ofwel eigen ofwel vriend. Deelnemers beoordeelden opnieuw wiens beweging ze zagen, nu op deze ambigu gemengde gezichten. Voor vriendbeweging ontstond goede prestatie zelfs wanneer slechts ongeveer een derde van de zichtbare gedaante op de vriend leek, wat laat zien dat bewegingscues op zichzelf krachtig zijn. Voor eigen beweging hadden deelnemers gezichten nodig die minimaal circa 60% op henzelf leken voordat ze er zeker van waren dat de beweging van henzelf was. De relatie tussen herkenning en gedaanteverhouding was steiler voor het eigen gezicht dan voor de vriend, wat een sterkere afhankelijkheid van gedaante bij het herkennen van eigen beweging onthult.
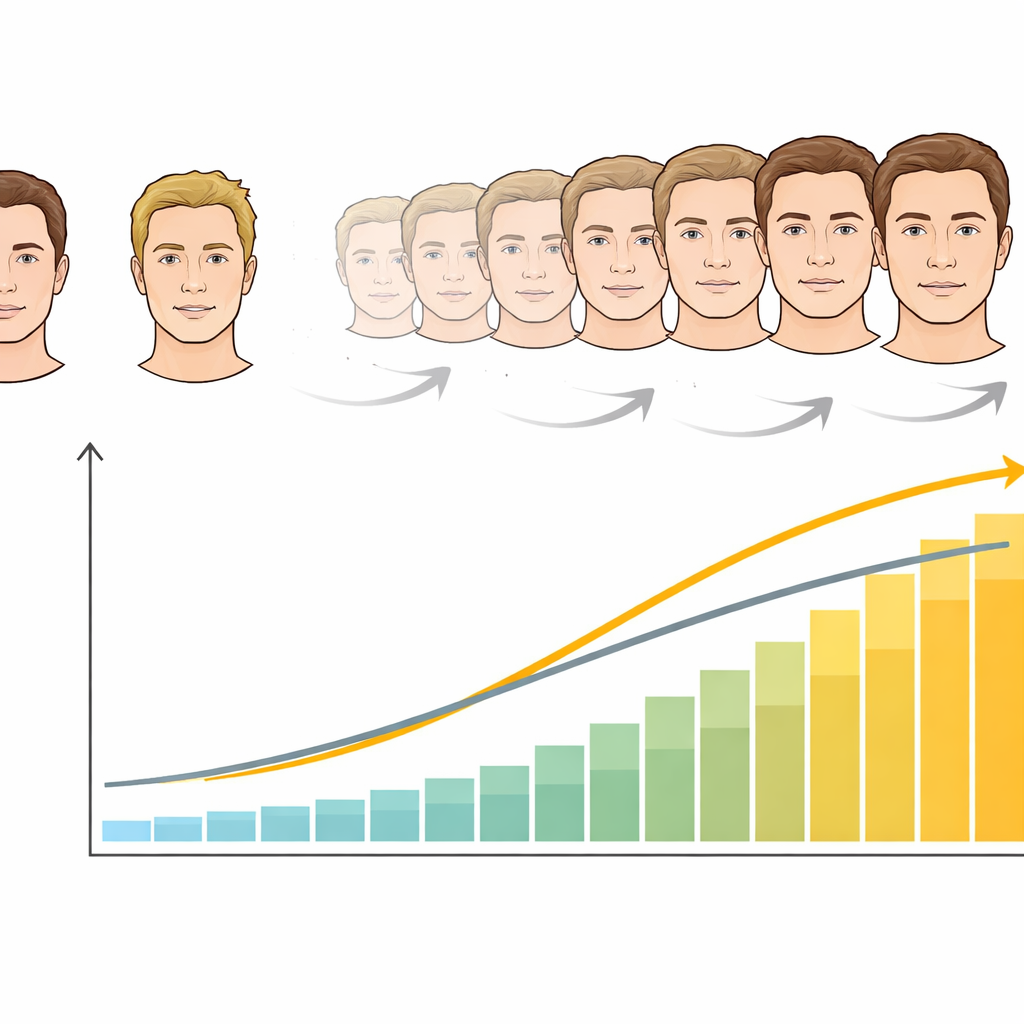
Wat dit betekent voor ons zelfgevoel
Gezamenlijk suggereren de bevindingen dat ons eigen bewegende gezicht, in belangrijk opzicht, minder vertrouwd is dan dat van een goede vriend. We lijken rijke informatie op te slaan over hoe vrienden bewegen en kunnen die beweging gebruiken zelfs wanneer de gezichtsgedaante is veranderd. Daarentegen lijkt ons interne beeld van eigen gedaantebeweging schaarser, waardoor we sterk op statische gedaante leunen om het gevoel “dat ben ik” te verankeren. De auteurs stellen dat zelfgezichten mogelijk een speciale categorie in de perceptie vormen: vertrouwd qua gedaante, maar dichter bij onbekende gezichten wat dynamische informatie betreft. Dit onderscheid helpt verklaren waarom gemanipuleerde zelfbeelden soms vreemd aanvoelen en toont hoe moderne deepfake‑tools opnieuw benut kunnen worden om de delicate balans tussen verschijning, beweging en identiteit te onderzoeken.
Bronvermelding: Yumura, S., Lander, K. & Kamachi, M.G. Exploring the importance of shape on dynamic recognition of self-face or friend-face. Sci Rep 16, 10802 (2026). https://doi.org/10.1038/s41598-026-45374-8
Trefwoorden: herkenning van eigen gezicht, gelaatsbeweging, deepfake-experimenten, gezichtsperceptie, vriend versus eigen identiteit