Clear Sky Science · it
Esplorare l’importanza della forma nel riconoscimento dinamico del volto proprio o di un amico
Perché conta il modo in cui vediamo il nostro volto
Passiamo una vita a vedere il nostro volto in specchi e fotografie, eppure raramente lo osserviamo muoversi come lo vedono gli altri. Questo studio pone una domanda apparentemente semplice ma di grande portata: riconosciamo il nostro volto in movimento allo stesso modo con cui riconosciamo il volto di un amico intimo? La risposta illumina il modo in cui il cervello costruisce il senso del sé e usa strumenti deepfake d’avanguardia non per ingannare, ma come metodo preciso per separare forma e movimento del volto.
Due tipi di informazione in un volto
Quando riconosciamo qualcuno ci affidiamo ad almeno due tipi di informazioni visive. Una è la forma del volto: il profilo della mandibola, la distanza tra gli occhi, la curva del naso. L’altra è il movimento: il modo in cui la bocca si muove parlando, o l’inclinazione caratteristica della testa. Per amici e celebrità vediamo ripetutamente sia forma che movimento nella vita quotidiana e nei media. Per il nostro volto, invece, osserviamo per lo più un riflesso statico e solo brevi movimenti speculari allo specchio. Questa asimmetria solleva un enigma: la rappresentazione cerebrale del movimento del volto proprio è ricca quanto quella dedicata ad altre persone familiari, oppure facciamo più affidamento sulla forma statica quando decidiamo “quello sono io”?
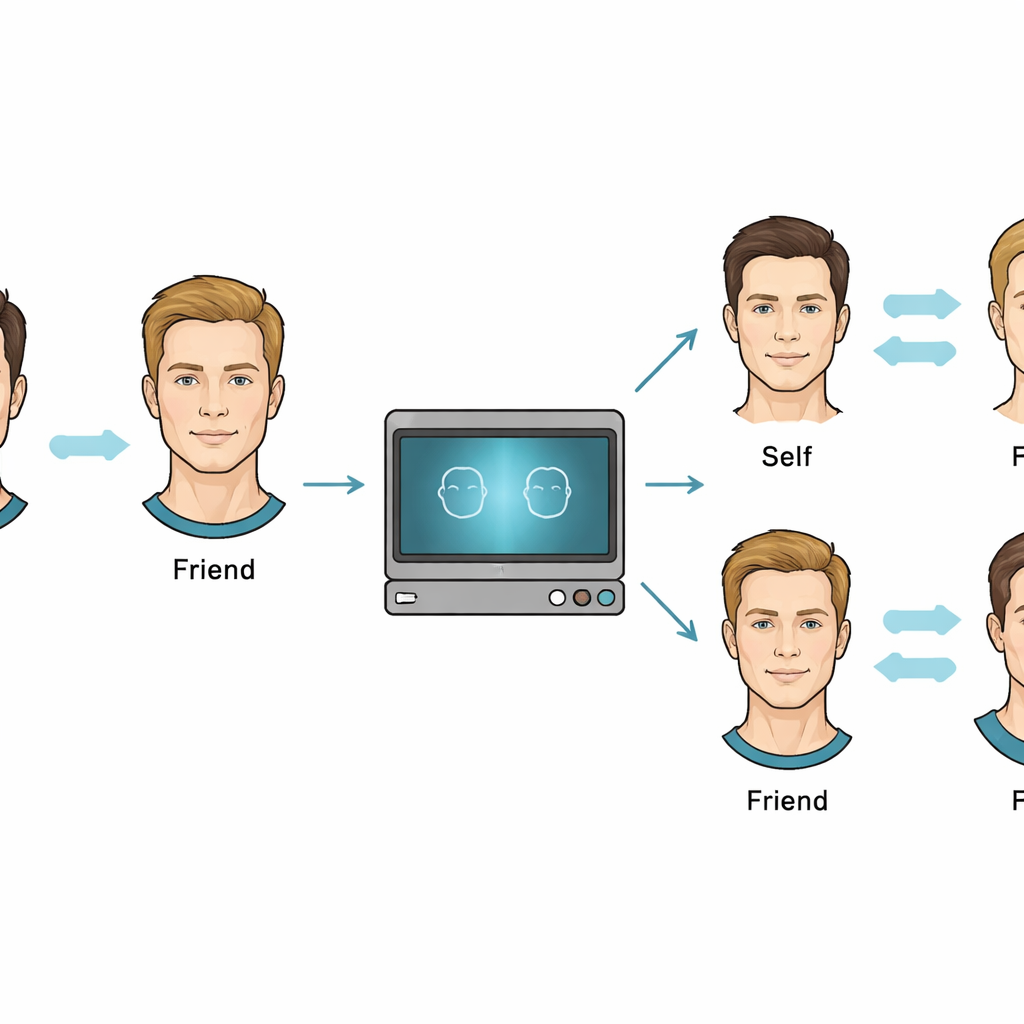
Usare i deepfake come strumento scientifico
Per dissociare forma e movimento, i ricercatori hanno registrato brevi video di giovani uomini che leggevano frasi ad alta voce. Ogni partecipante era abbinato a un amico reale, così il volto di ciascuno poteva assumere il ruolo di “sé” o di “amico” a seconda di chi guardava. Il software deepfake è stato usato non per creare inganni, ma per scambiare le forme facciali mantenendo intatto il movimento originale. Questo ha permesso di generare clip altamente realistiche in cui, per esempio, i movimenti facciali di un amico venivano riprodotti su una forma facciale del partecipante, o viceversa. I partecipanti hanno guardato questi video in una stanza oscurata e, dopo ciascuno, hanno premuto un tasto per indicare se il movimento del volto appartenesse a sé o all’amico, ricevendo l’istruzione di ignorare per quanto possibile l’aspetto statico.
Quando forma e movimento concordano o confliggono
Nel primo esperimento c’erano quattro combinazioni nette: forma del sé con movimento del sé, forma del sé con movimento dell’amico, forma dell’amico con movimento del sé e forma dell’amico con movimento dell’amico. I risultati hanno mostrato che le persone riuscivano a distinguere in modo affidabile i movimenti propri da quelli dell’amico. Per il movimento dell’amico, le prestazioni cambiavano di poco se il volto visibile sembrava quello dell’amico o quello del partecipante; il pattern di movimento di per sé era sufficiente. Per il movimento proprio, il riconoscimento era molto migliore quando anche la forma visibile somigliava al sé. Quando il movimento proprio veniva mostrato su una forma a somiglianza dell’amico, l’accuratezza calava sensibilmente, suggerendo che le persone faticano a riconoscere i loro movimenti caratteristici a meno che la forma circostante non segnali anch’essa “questo sono io”.
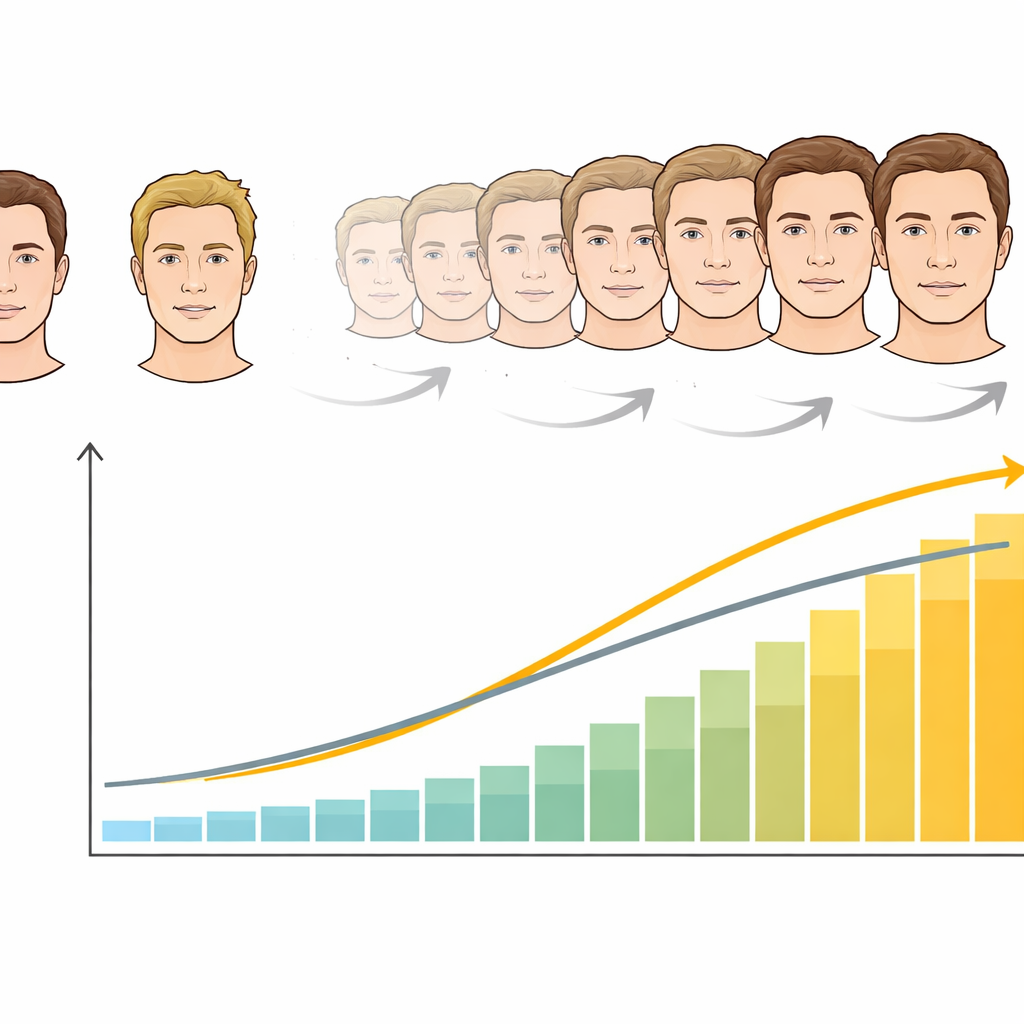
Fondere i volti per misurare la dipendenza dalla forma
Il secondo esperimento ha portato avanti questa idea sfumando gradualmente le due forme. Invece di usare solo volti puramente propri o puramente dell’amico, i ricercatori hanno creato undici livelli intermedi, dal 100% forma dell’amico al 100% forma del sé, mantenendo il segnale di movimento fisso come proprio o dell’amico. I partecipanti hanno nuovamente giudicato a chi appartenesse il movimento, stavolta su volti ambigui e sfumati. Per il movimento dell’amico, buone prestazioni emergevano anche quando solo circa un terzo della forma visibile corrispondeva all’amico, mostrando che le informazioni di movimento da sole erano potenti. Per il movimento proprio, i partecipanti avevano bisogno che il volto fosse almeno circa per il 60% simile al sé prima di poter dire con sicurezza che il movimento fosse il loro. La curva che collega riconoscimento e forma era più ripida per il sé che per l’amico, rivelando una maggiore dipendenza dalla forma nel riconoscere il proprio movimento.
Che cosa significa per il nostro senso del sé
Nel complesso, i risultati suggeriscono che il nostro volto in movimento è, in un senso importante, meno familiare rispetto a quello di un amico intimo. Sembra che memorizziamo informazioni ricche su come si muovono gli amici e possiamo usare quel movimento anche quando la forma del volto è alterata. Al contrario, la nostra rappresentazione interna del movimento del volto proprio appare più scarna, quindi facciamo forte affidamento sulla forma statica per ancorare la sensazione di “quello sono io”. Gli autori propongono che i volti propri possano costituire una categoria speciale nella percezione: familiari dal punto di vista della forma, ma più vicini ai volti non familiari per quanto riguarda le informazioni dinamiche. Questa distinzione aiuta a spiegare perché immagini manipolate del proprio volto possono apparire stranamente sbagliate e mostra come gli strumenti deepfake moderni possano essere riutilizzati per sondare il delicato equilibrio tra aspetto, movimento e identità.
Citazione: Yumura, S., Lander, K. & Kamachi, M.G. Exploring the importance of shape on dynamic recognition of self-face or friend-face. Sci Rep 16, 10802 (2026). https://doi.org/10.1038/s41598-026-45374-8
Parole chiave: riconoscimento del volto proprio, moto facciale, esperimenti deepfake, percezione del volto, identità amico vs sé