Clear Sky Science · nl
Classificatie van meldingen over gebrekkige gezondheidsproducten met deep learning
Waarom het belangrijk is om slechtere geneesmiddelen sneller te ontdekken
De meesten van ons gaan ervan uit dat de medicijnen en gezondheidsproducten die we gebruiken veilig zijn en volgens strikte kwaliteitsnormen worden vervaardigd. Toch worden wereldwijd jaarlijks honderden geneesmiddelen teruggeroepen vanwege verontreiniging, verkeerde ingrediënten of misleidende etikettering. Elk defect product vormt een potentieel gevaar voor patiënten. Toezichthouders moeten snel duizenden foutmeldingen lezen en interpreteren om te bepalen welke dringende actie vereisen. Dit artikel beschrijft hoe een deep-learningsysteem is ontwikkeld om gezondheidsautoriteiten te helpen deze meldingen sneller en consistenter te classificeren, zodat zij hun aandacht kunnen richten op problemen met het grootste risico voor de volksgezondheid.
Hoe productproblemen momenteel worden gemeld
Wanneer een mogelijk defect wordt gevonden in een geneesmiddel of ander gezondheidsproduct, wordt een korte schriftelijke melding naar toezichthouders gestuurd. Deze meldingen kunnen veel verschillende problemen beschrijven: glassplinters in een flacon, het verkeerde ingrediënt in een pil, verpakkingen die lekken of etiketten die tot doseringsfouten kunnen leiden. In Singapore gebruikt de Health Sciences Authority een standaard medische woordenschat, aangepast aan lokale behoeften, om elke melding in een van meerdere specifieke categorieën te groeperen, zoals microbiële verontreiniging of reclame die regels overtreedt. De aan een melding toegekende categorie helpt bepalen hoe ernstig het probleem is en hoe snel het moet worden aangepakt. Op dit moment lezen getrainde medewerkers elke melding en wijzen handmatig een label toe. Dit werk is traag, complex en kan inconsistent zijn, vooral naarmate het aantal meldingen toeneemt.
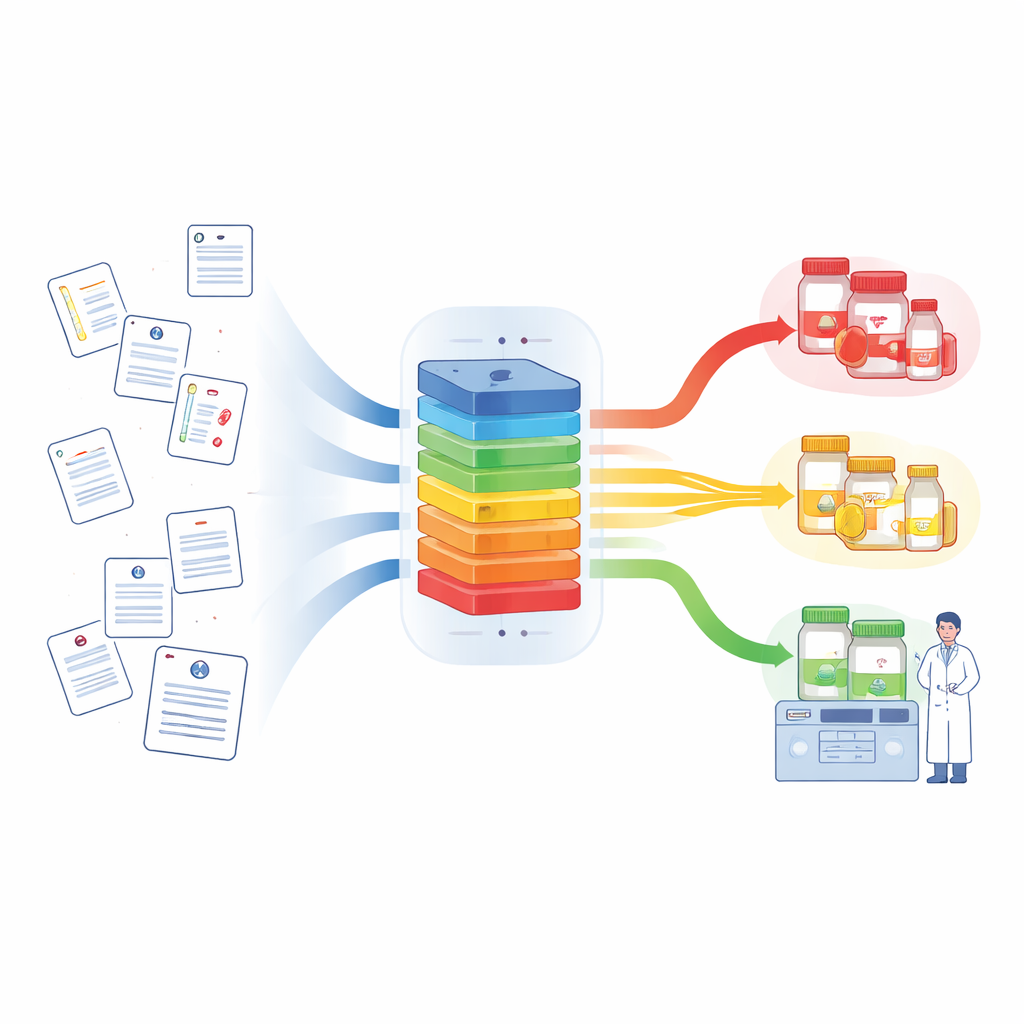
Een computer leren defectmeldingen te lezen
De onderzoekers wilden een kunstmatig-intelligentiesysteem bouwen dat deze medewerkers ondersteunt in plaats van vervangt. Ze verzamelden 13.830 meldingen over defecten die tussen 2010 en 2021 waren ontvangen, met betrekking tot medicijnen, vaccins, supplementen en cosmetica. Een team van ervaren apothekers beoordeelde en labelde zorgvuldig elke melding met 21 van de meest voorkomende defectcategorieën, die samen meer dan 99% van alle gevallen dekt. Het team gebruikte vervolgens een populair taalmodel genaamd BERT, dat is ontworpen om de betekenis van woorden in context te begrijpen, als de kern van hun systeem. Door BERT fijn af te stemmen op deze gelabelde verzameling, creëerden ze een hulpmiddel — MedDefects‑BERT — dat de titel en beschrijving van een melding kan lezen en de meest waarschijnlijke defectcategorie kan voorspellen.
Hoe goed het systeem presteert
Bij tests op meldingen die het nog niet had gezien, kwam MedDefects‑BERT 86% van de tijd overeen met de eerste keuze van de experts. Als het systeem zijn drie meest waarschijnlijke categorieën mocht voorstellen, zat de juiste categorie 96% van de tijd in de lijst. Dit is belangrijk omdat een echte medewerker eenvoudig een korte lijst met suggesties kan beoordelen in plaats van vanaf nul te beginnen. Het systeem werkte beter voor categorieën met meer trainingsvoorbeelden, wat typisch is voor machine learning. Desondanks verhoogde het toestaan van maximaal drie voorgestelde labels de prestatie boven 70% voor elke categorie, ook voor zeldzamere. De vertrouwensscores van het model — getallen tussen 0 en 1 die aangeven hoe zeker het is — vertoonden een sterke samenhang met hoe vaak het juist was. Door een drempel voor vertrouwen in te stellen liet het team zien dat ze de nauwkeurigheid konden verhogen tot ongeveer 91% voor “zekere” voorspellingen, terwijl een bescheiden deel van de gevallen als “onzeker” werd gemarkeerd voor nader menselijk onderzoek.
Inzicht in de beslissingen van het model
De auteurs pakten ook een belangrijke zorg rond AI in veiligheidskritische domeinen aan: transparantie. Ze gebruikten visualisatietools om te laten zien dat meldingen met dezelfde defectcategorie in de interne “kaart” van documentbetekenissen van het model bij elkaar clusteren, terwijl verkeerd geclassificeerde meldingen aan de randen tussen clusters zitten. Op het niveau van individuele woorden pasten ze een methode genaamd SHAP toe om te benadrukken welke termen in een melding het model naar een bepaalde categorie duwden. Bijvoorbeeld, woorden gerelateerd aan schimmels of meeldauw beïnvloedden sterk voorspellingen van microbiële verontreiniging, terwijl termen als “sediment” of “neerslag” een categorie ondersteunden die verband houdt met afzettingen in producten. Deze verklaringen geven medewerkers een snelle manier om te zien waarom het model een suggestie deed en te beoordelen of deze zinvol is in de context.
Het systeem slimmer en efficiënter maken
Om de prestaties verder te verbeteren zonder zware rekenkosten toe te voegen, gebruikte het team een techniek die bekendstaat als deep prompt tuning. In plaats van alle interne instellingen van het model te wijzigen, voegden ze kleine trainbare “prefixes” toe aan elke laag die het model zachtjes in de richting van deze specifieke taak sturen. Het combineren van traditionele fijnafstemming met deze prompts verhoogde de nauwkeurigheid van het systeem in meer dan de helft van de defectcategorieën en verbeterde het vermogen om gevallen correct te detecteren in het algemeen. Tests op nieuwere meldingen uit 2022 toonden aan dat de nauwkeurigheid van het systeem in de loop van de tijd standhield, wat suggereert dat het begrip van defectmeldingen niet snel verouderde.
Wat dit betekent voor patiënten en toezichthouders
De studie toont aan dat een goed ontworpen taalmodel toezichthouders aanzienlijk kan helpen bij het doorzoeken van grote aantallen meldingen over gebrekkige gezondheidsproducten, het standaardiseren van de manier waarop zaken worden gecategoriseerd en het sneller signaleren van risico’s met hoge prioriteit. Omdat het systeem ook uitlegt welke woorden en passages zijn suggesties hebben gestuurd, blijven menselijke experts stevig verantwoordelijk voor de eindbeslissingen. Met verdere verfijning — zoals het omgaan met meerdere defecttypen in één melding en uitbreiding naar zeldzamere categorieën — zouden vergelijkbare hulpmiddelen het toezicht op medicijnkwaliteit wereldwijd kunnen versterken, vertragingen bij het terugroepen van gevaarlijke producten kunnen verminderen en uiteindelijk betere bescherming voor patiënten kunnen bieden.
Bronvermelding: Sancenon, V., Huang, Y., Zou, L. et al. Classification of health product defect reports by deep learning. Sci Rep 16, 13528 (2026). https://doi.org/10.1038/s41598-026-43961-3
Trefwoorden: veiligheid van geneesmiddelen, kwaliteit van geneesmiddelen, deep learning, toezichthouding, natuurlijke taalverwerking