Clear Sky Science · nl
Objectvolg-algoritme gebaseerd op deformeerbaar attentiemechanisme
Bijhouden in een drukke, rommelige wereld
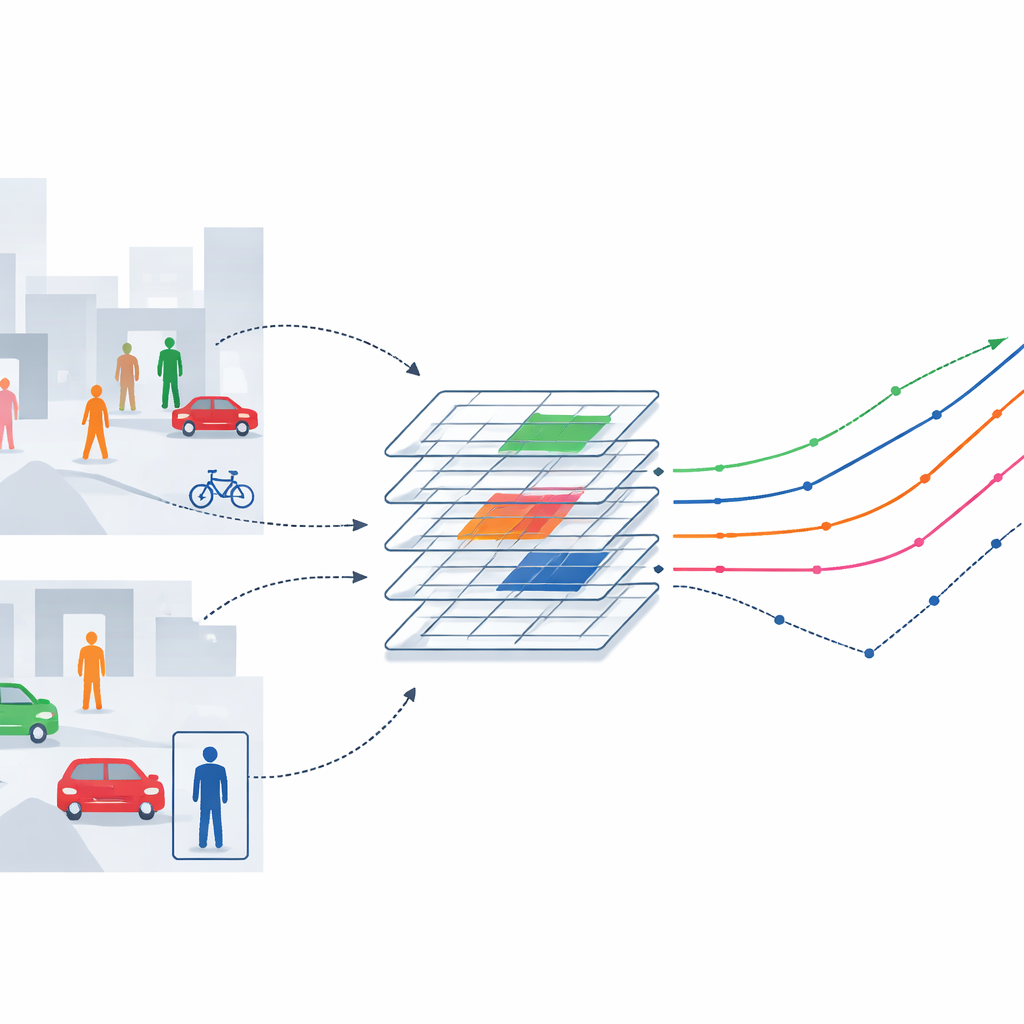
Moderne camera’s houden drukke straten, winkelcentra en fabrieksvloeren in de gaten, maar computers leren om vele bewegende mensen en objecten in zulke scènes te volgen is verrassend lastig. Wanneer iemand achter een zuil loopt, wanneer koplampen schitteren, of wanneer een menigte zich door een deuropening wringt, kan zelfs geavanceerde volgersoftware het spoor bijster raken, identiteiten door elkaar halen of te veel rekencapaciteit verbruiken. Dit artikel introduceert een nieuwe volgbenadering die ontworpen is om doelwitten betrouwbaarder vast te houden in deze realistische, chaotische situaties, terwijl het nog steeds efficiënt genoeg draait voor praktisch gebruik.
Waarom traditionele tracking tekortschiet
Objectvolgsystemen werken gewoonlijk in drie stappen: ze scannen eerst elk videoframe om visuele details te extraheren, combineren vervolgens informatie van verschillende schalen en gebieden, en voorspellen tenslotte hoe elk doelwit zich in de tijd voortbeweegt. Veel recente methoden hebben één van deze stappen afzonderlijk verbeterd — bijvoorbeeld door de detector beter te maken, berekeningen te versnellen of slimere bewegingsmodellen toe te voegen. Maar in drukke, snel veranderende scènes treden de zwaktes tussen deze onderdelen duidelijker naar voren. Vaste “gezichtsvelden” in standaardnetwerken kunnen zich niet soepel aanpassen aan gebogen lichamen of wisselende houdingen, en bewegingsvoorspellingen die een vloeiende, eenvoudige beweging veronderstellen kunnen sterk afdrijven wanneer mensen stoppen, draaien of kortstondig achter obstakels verdwijnen.
Een flexibel oog voor bewegende doelen
De auteurs pakken deze beperkingen aan door het volgsysteem een flexibeler manier te geven om naar de scène te “kijken”. Ze beginnen met een veelgebruikt beeldverwerkingsbackbone genaamd ResNet-18 en weven daar een deformeerbaar attentiemechanisme doorheen. In plaats van altijd visuele informatie op starre, gelijkmatig verdeelde punten te bemonsteren, leert dit mechanisme zijn bemonsteringslocaties naar de meest informatieve plekken op een persoon of object te schuiven — zoals de omtrek van torso of hoofd — terwijl storende achtergrondprikkels worden genegeerd. Door deze flexibele aandacht in diepere lagen van het netwerk in te voegen, kan het systeem zijn focus aanpassen als mensen van houding veranderen, schalen variëren of deels verborgen zijn, zonder veel extra rekencapaciteit toe te voegen. Tests op grote benchmarks tonen aan dat dit flexibele oog niet alleen de volgnauwkeurigheid verhoogt maar dit doet met minder dan 8% extra rekenwerk en slechts een kleine toename in parameters.
Details mengen over schalen en door de tijd
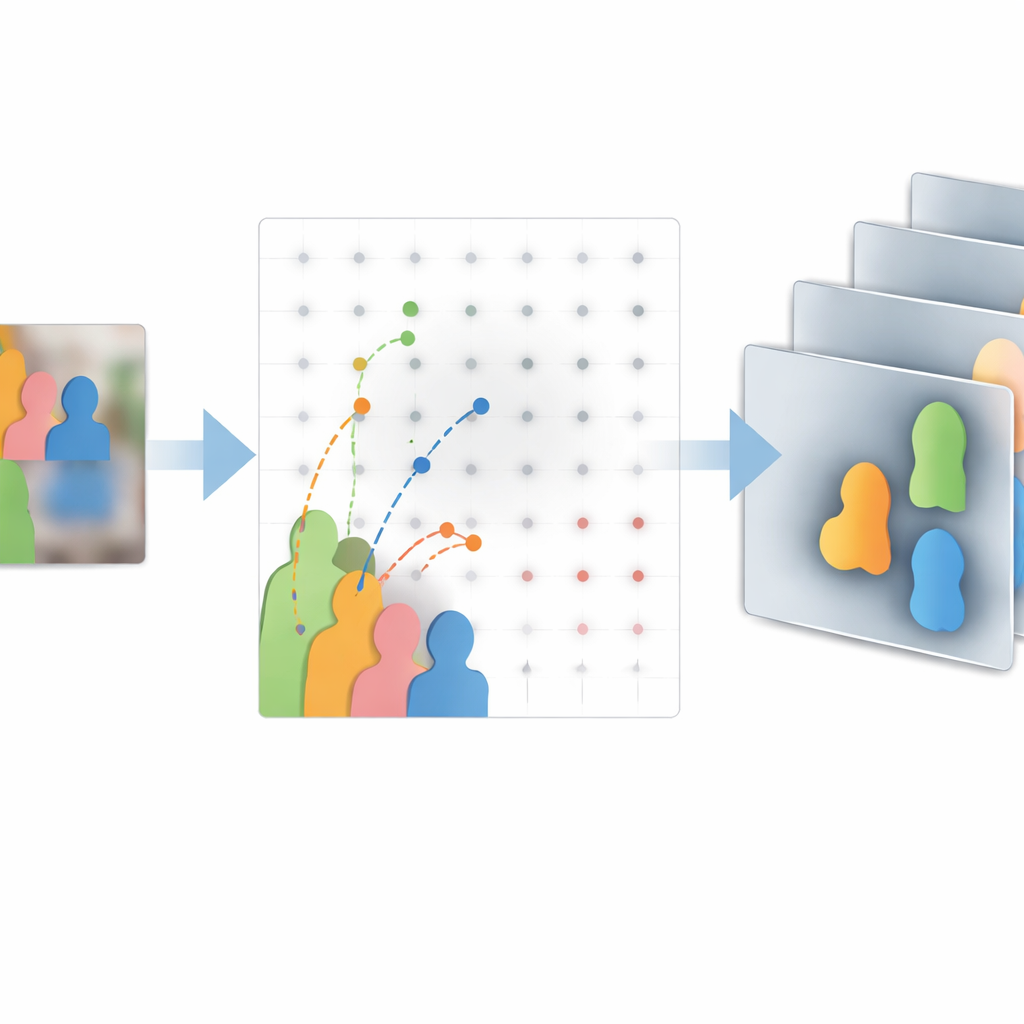
Het gelijktijdig volgen van vele objecten vereist ook dat het systeem zowel fijne details als het grotere plaatje begrijpt. Om dit te bereiken gebruikt de methode een speciaal feature-fusiecomponent, een bidirectionele feature-piramide, die informatie mengt van grovere, hoog-niveau weergaven en fijne, laag-niveau details. De auteurs versterken dit module met hetzelfde deformeerbare aandachtidee, zodat het features beter kan uitlijnen die anders niet goed overeenkomen wanneer mensen overlappen of snel bewegen. Dit helpt individuen in dichte menigten te scheiden en vermindert identiteitsverwisselingen. Op de tijdsdimensie vertrouwt het algoritme op een klassiek hulpmiddel uit de regeltechniek, het Kalman-filter, maar op een slimmer manier. In plaats van de voorspelling van het model als de hoofdwaarheid te zien en de detector als kleine correctie, wordt het gedrag van het filter gestuurd door hoe zeker de detector in elk frame is. Wanneer de detector zeker is, vertrouwt het systeem die direct en voorkomt het ophoping van fouten; wanneer de detector onzeker is, leunt het filter meer op eerdere bewegingen en mengt beide bronnen soepel.
Hoe goed werkt het in de praktijk?
Het team evalueert hun aanpak — DAM-Track genoemd — op uitdagende openbare datasets die bedoeld zijn om volgalgoritmen op de proef te stellen. Bij tests met enkelvoudige objecten die lange reeksen en moeilijke situaties zoals sterke vervorming en volledige occlusie benadrukken, verbetert hun deformeerbare attentie-backbone overlap- en succeskansen ten opzichte van standaard ResNet-18, zonder grote extra kosten. Op een beroemde multi-object benchmark vol extreem dichte voetgangersmenigten behaalt DAM-Track hogere totale nauwkeurigheid, scherpere lokalisatie en betere identiteitconsistentie dan veelgebruikte methoden zoals ByteTrack en DeepSORT. Het behoudt meer trajecten langer, verliest minder doelwitten en presteert bijzonder goed in het vermijden van identiteitswisselingen, wat cruciaal is voor toepassingen zoals veiligheidsmonitoring en verkeersanalyse.
Wat dit betekent voor alledaagse toepassingen
Voor niet-specialisten is de kernboodschap dat dit werk computervisietrackers robuuster maakt in de soorten rommelige, onvoorspelbare scènes die in de praktijk het meest relevant zijn — van treinstations en stadsstraten tot slimme winkels en autonome voertuigen. Door het systeem toe te staan zijn “blik” naar belangrijke regio’s te buigen en door feature-extractie, multiscale fusie en bewegingsvoorspelling te coördineren via een gedeelde maat van zekerheid, bouwen de auteurs een gesloten-lus tracker die beter bijhoudt wie waar is in de loop van de tijd. Hoewel verder testen nodig is in nachtelijke, lucht- en multi-camera omgevingen, wijst dit flexibele, zekerheid-gestuurde ontwerp op een nieuwe generatie volgsystemen die complexe omgevingen betrouwbaarder kunnen monitoren zonder onpraktische rekeneisen.
Bronvermelding: Liu, Q., Yu, N. & Cheng, J. Object tracking algorithm based on deformable attention mechanism. Sci Rep 16, 12454 (2026). https://doi.org/10.1038/s41598-026-43147-x
Trefwoorden: multi-object tracking, computer vision, attention mechanisms, crowd surveillance, autonomous driving