Clear Sky Science · en
Object tracking algorithm based on deformable attention mechanism
Keeping Track in a Crowded, Messy World
Modern cameras watch over busy streets, shopping malls, and factory floors, but teaching computers to follow many moving people and objects in these scenes is surprisingly hard. When someone walks behind a pillar, when headlights flare, or when a crowd squeezes through a doorway, even advanced tracking software can lose track, mix up identities, or burn too much computing power. This paper introduces a new tracking approach designed to stay locked onto targets more reliably in these real-world, chaotic situations, while still running efficiently enough for practical use.
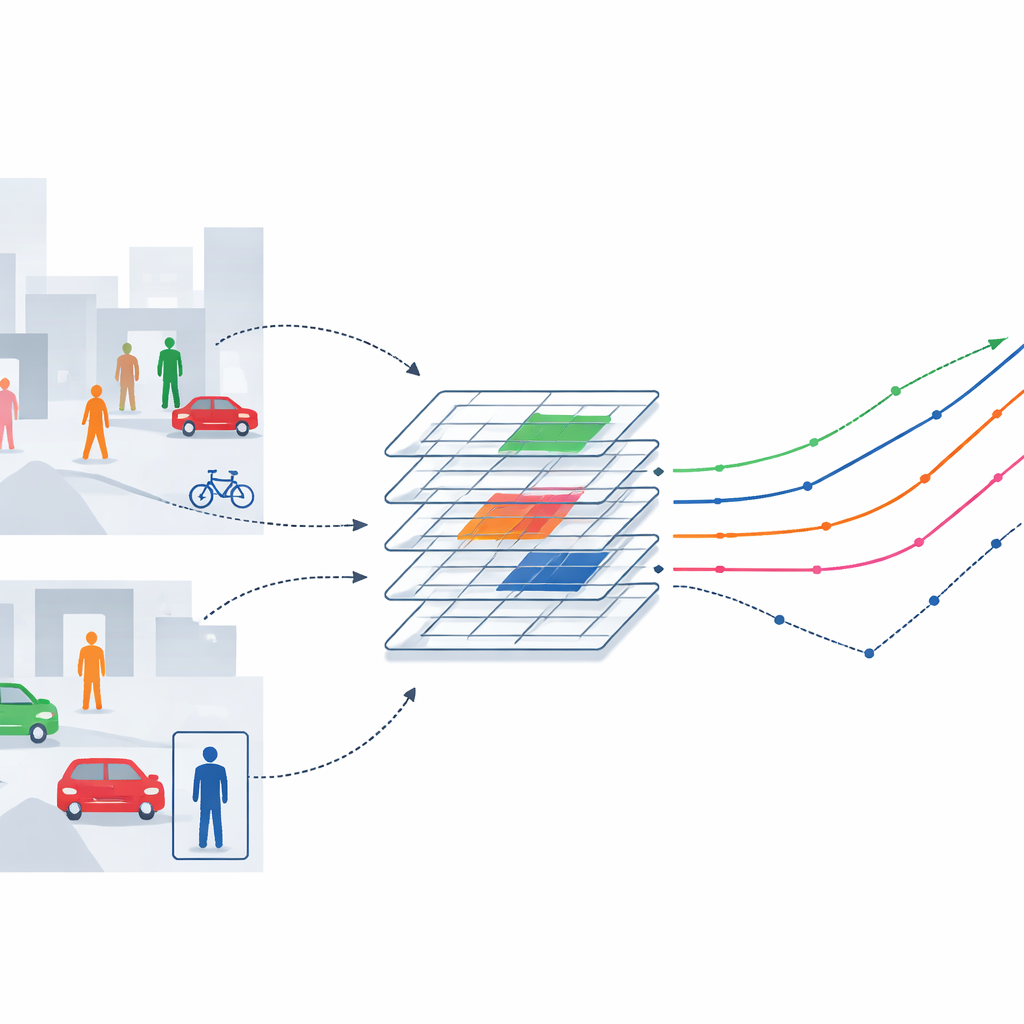
Why Traditional Tracking Falls Short
Object tracking systems usually work in three stages: they first scan each video frame to pull out visual details, then combine information from different scales and areas, and finally predict how each target moves over time. Many recent methods have improved one of these steps at a time—for example, making the detector better, speeding up computations, or adding smarter motion models. But in crowded, fast-changing scenes, the weaknesses between these parts show through. Fixed "fields of view" in standard networks can’t flex around bending bodies or shifting poses, and motion prediction that assumes smooth, simple movement can drift badly when people stop, turn, or vanish briefly behind obstacles.
A Flexible Eye for Moving Targets
The authors tackle these limits by giving the tracking system a more flexible way of “looking” at the scene. They start with a popular image-processing backbone called ResNet-18 and weave in a deformable attention mechanism. Instead of always sampling visual information at rigid, evenly spaced points, this mechanism learns to slide its sampling locations toward the most informative spots on a person or object—such as the outline of a torso or head—while ignoring distracting background clutter. By inserting this flexible attention into deeper layers of the network, the system can adapt its focus as people change pose, scale, or are partly hidden, without adding much computational burden. Tests on large benchmarks show that this flexible eye not only boosts tracking accuracy but does so with less than an 8% increase in computation and only a small increase in parameters.
Blending Details Across Scales and Over Time
Tracking many objects at once also demands that the system understand both fine details and the bigger picture. To do this, the method uses a special feature-fusion module, a bidirectional feature pyramid, that mixes information from coarse, high-level views and fine, low-level details. The authors enhance this module with the same deformable attention idea, allowing it to better align features that might otherwise be mis-matched when people overlap or move quickly. This helps separate individuals in dense crowds and reduces identity mix-ups. On the time dimension, the algorithm relies on a classic tool from control theory, the Kalman filter, but in a smarter way. Instead of treating the model’s prediction as the main truth and the detector as a small correction, the filter’s behavior is driven by how confident the detector is in each frame. When the detector is sure, the system trusts it directly and cuts off error buildup; when it is uncertain, the filter leans more on past motion, blending both sources smoothly.
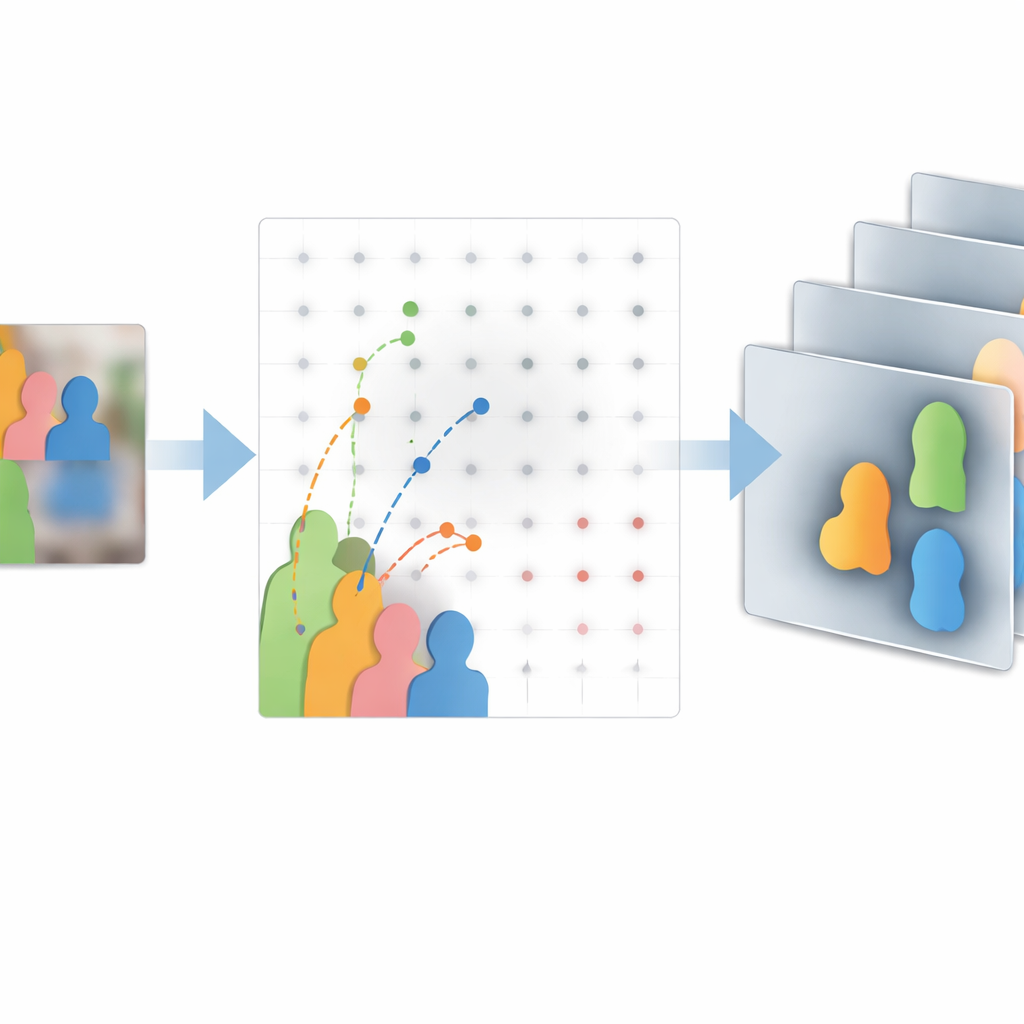
How Well Does It Work in the Real World?
The team evaluates their approach—called DAM-Track—on challenging public datasets designed to stress-test tracking algorithms. On single-object tests that emphasize long sequences and difficult situations like strong deformation and full occlusion, their deformable attention backbone improves overlap and success rates over standard ResNet-18, without heavy extra cost. On a famous multi-object benchmark filled with extremely dense pedestrian crowds, DAM-Track achieves higher overall accuracy, sharper localization, and better identity consistency than widely used methods such as ByteTrack and DeepSORT. It maintains more trajectories for longer, loses fewer targets, and performs particularly well at avoiding identity switches, which are crucial for applications such as safety monitoring and traffic analysis.
What This Means for Everyday Applications
For a non-specialist, the takeaway is that this work makes computer vision trackers more resilient in the kinds of messy, unpredictable scenes that matter most in practice—from train stations and city streets to smart shops and autonomous vehicles. By allowing the system’s “gaze” to bend toward important regions and by coordinating feature extraction, multi-scale fusion, and motion prediction through a shared notion of confidence, the authors build a closed-loop tracker that keeps better tabs on who is where over time. While further testing is needed in night-time, aerial, and multi-camera settings, this flexible, confidence-aware design points toward a new generation of tracking systems that can watch complex environments more reliably without demanding impractical computing resources.
Citation: Liu, Q., Yu, N. & Cheng, J. Object tracking algorithm based on deformable attention mechanism. Sci Rep 16, 12454 (2026). https://doi.org/10.1038/s41598-026-43147-x
Keywords: multi-object tracking, computer vision, attention mechanisms, crowd surveillance, autonomous driving