Clear Sky Science · nl
Diep leren voor het voorspellen van stamcel‑efficiëntie voor gebruik bij beta‑cel differentiatie
Waarom dit onderzoek belangrijk is voor toekomstige diabeteszorg
Voor mensen met type 1 diabetes is er een opkomende droom om verloren insulinproducerende cellen te vervangen in plaats van te vertrouwen op levenslange injecties. Wetenschappers kunnen zulke cellen nu kweken uit de eigen stamcellen van een patiënt, maar het proces is traag, kostbaar en vaak niet succesvol. Deze studie laat zien hoe kunstmatige intelligentie vroege microscoopbeelden van stamcellen kan analyseren en binnen slechts een paar dagen kan voorspellen welke batches waarschijnlijk goede insulinproducerende cellen zullen worden en welke zullen teleurstellen—waardoor mogelijk tijd, geld en kostbaar biologisch materiaal bespaard kunnen worden.
Van huidcellen naar insulinemakerende cellen
In modern onderzoek naar celtherapie kunnen gewone volwassen cellen van een patiënt worden teruggeprogrammeerd naar een stamcelachtige staat, aangeduid als geïnduceerde pluripotente stamcellen. Deze stamcellen kunnen vervolgens in een proces van ongeveer een maand worden geleid om pancreas‑beta‑cellen te worden, de cellen die insuline afscheiden. In theorie biedt dit een persoonlijke, afstotingsbestendige bron van vervangende cellen voor mensen met type 1 diabetes. In de praktijk gedraagt elke stamcel "klont" van een patiënt zich anders: sommige leveren veel gezonde beta‑cellen op, andere zeer weinig. Omdat de verschillen in het begin subtiel zijn, kunnen zelfs ervaren experts niet betrouwbaar vroegtijdig zeggen welke klonen goed zullen presteren. Die onzekerheid dwingt onderzoekers om zwakke klonen door de volledige 34‑daagse procedure te laten lopen, waardoor moeite wordt verspild en de kosten stijgen.
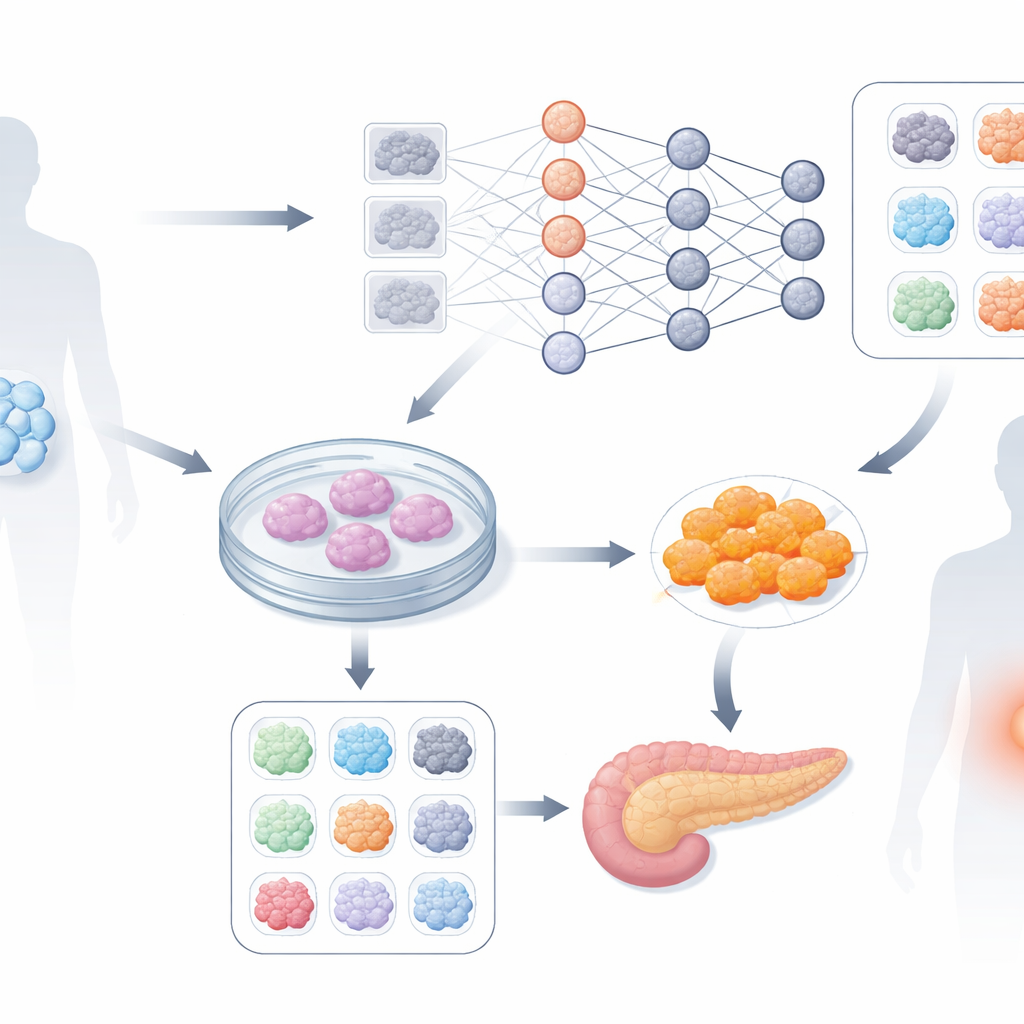
Computers leren subtiele cellulair patronen te lezen
De auteurs wilden onderzoeken of een diep‑leersysteem—vergelijkbaar met systemen die in beeldherkenning worden gebruikt—vroegtijdige visuele aanwijzingen in eenvoudige, labelvrije microscoopbeelden kon herkennen. Ze werkten met zes patiëntafgeleide stamcelklonen, allemaal gericht op hetzelfde doelceltype. In plaats van gekleurde kleurstoffen of complexe beeldvorming gebruikten ze standaard fase‑contrastfoto’s die elk uur werden genomen tijdens de eerste vier dagen van de ontwikkeling. Later werd het succes van elke kloon gemeten met een bekend merker op dag vier die correleert met hoe goed de cellen uiteindelijk in functionele beta‑cellen veranderen. Klonen werden ingedeeld in “goed” en “slecht” op basis van deze merker, en het neurale netwerk werd getraind om deze groepen alleen aan de hand van vroege beelden uit elkaar te houden.
Hoe goed het systeem succes kan voorspellen
Met een op EfficientNet gebaseerd diep‑leermodel sneden de onderzoekers hoge resolutie beelden in kleinere stukjes en trainden het netwerk op vele dergelijke fragmenten van elke kloon. Ze evalueerden de prestaties op twee manieren: hoe vaak individuele fragmenten correct werden geclassificeerd, en hoe vaak de algehele voorspelling voor een hele kloon klopte, met behulp van een stemschema. Terwijl beelden gemaakt voordat differentiatie begon geen nuttige visuele verschillen bevatten, werden de voorspellingen van het netwerk rond twee dagen in het proces opvallend accuraat. Rond 53 uur identificeerde het systeem de uiteindelijke uitkomst correct voor 96,7 procent van de klonen, wat een sterk vroeg waarschuwingssignaal gaf over welke stamcelbatches de moeite waard waren om door te zetten en welke konden worden gestopt en opnieuw gestart met nieuwe cellen.
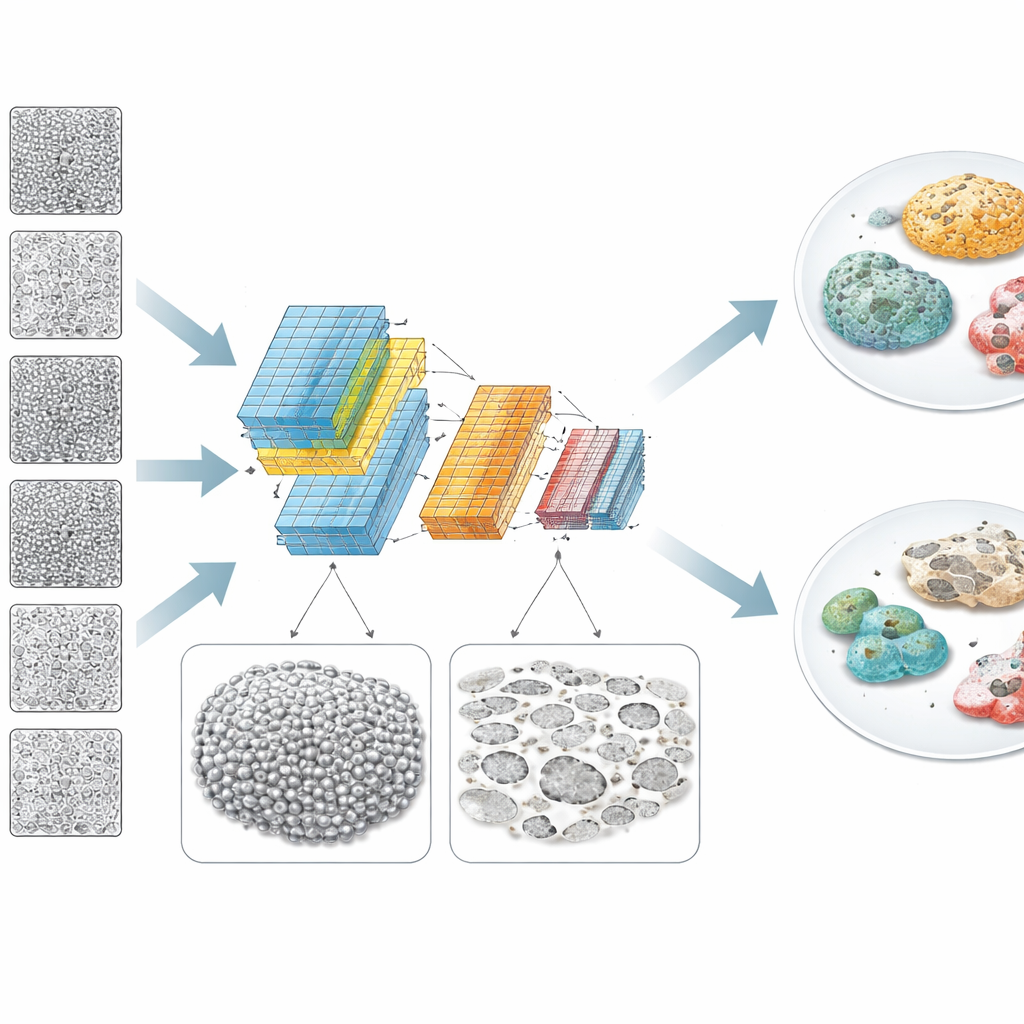
Waar de computer naar "kijkt" in de cellen
Om verder te gaan dan een black‑boxvoorspelling gebruikte het team explainable‑AI‑tools en traditionele beeldanalyse om te begrijpen welke visuele kenmerken van belang waren. Heatmaps van de aandacht van het netwerk suggereerden dat het niet op individuele cellen focuste, maar op bredere patronen over het celvlak. Goede klonen vormden doorgaans meer continue, uniforme lagen van cellen, terwijl slechte klonen meer lege plekken of “gaten” en ongelijkmatige helderheid over gebieden van tientallen tot honderden micrometers vertoonden. Een aparte wiskundige analyse van de beeldstructuur ondersteunde dit beeld: bij slechte klonen waren intensiteitsvariaties sterker over intermediaire lengteschalen, consistent met vlekkerige bedekking en debris. De verklaringen van het model correleerden met eenvoudige maten zoals helderheidsvariantie, en de auteurs toonden aan hoe verschillende beeldnormalisatiestrategieën de prestatie beïnvloedden afhankelijk van hoe schoon of vervuild de kweek was.
Stappen naar efficiëntere en betaalbaardere celtherapie
Dit werk is een vroege maar veelbelovende demonstratie dat diep leren, gecombineerd met zeer eenvoudige live‑celbeeldvorming, kan fungeren als een geautomatiseerde vroege kwaliteitsinspectie voor stamcelproductie. Door zwakke klonen al na een paar dagen te signaleren, zouden dergelijke systemen het aantal verspilde kweekruns kunnen verminderen en de kosten voor het produceren van patiëntspecifieke beta‑cellen kunnen verlagen, waardoor celtherapie voor type 1 diabetes dichter bij routinematige klinische toepassing komt. Hoewel de studie slechts zes klonen omvatte en gevalideerd moet worden op grotere en meer diverse datasets, laat ze zien dat subtiele, populatie‑niveau cellulair patronen rijke informatie bevatten die computers kunnen benutten lang voordat het menselijk oog duidelijke verschillen ziet.
Bronvermelding: Schöb, F.J., Binder, A., Zamarian, V. et al. Deep learning for predicting stem cell efficiency for use in beta cell differentiation. Sci Rep 16, 12788 (2026). https://doi.org/10.1038/s41598-026-42830-3
Trefwoorden: type 1 diabetes celtherapie, geïnduceerde pluripotente stamcellen, deep learning microscopie, beta‑cel differentiatie, beeldgebaseerde kwaliteitscontrole