Clear Sky Science · fr
Apprentissage profond pour prédire l’efficacité des cellules souches en vue de la différenciation en cellules bêta
Pourquoi cette recherche compte pour les soins futurs du diabète
Pour les personnes atteintes de diabète de type 1, un rêve en devenir est de remplacer les cellules productrices d’insuline perdues plutôt que de dépendre d’injections à vie. Les scientifiques peuvent désormais générer ces cellules à partir des propres cellules souches d’un patient, mais le processus est lent, coûteux et souvent infructueux. Cette étude montre comment l’intelligence artificielle peut analyser de simples images microscopiques précoces de cellules souches et prédire, en seulement quelques jours, quels lots sont susceptibles de devenir de bonnes cellules productrices d’insuline et lesquels sont voués à décevoir — économisant potentiellement du temps, de l’argent et du matériel biologique précieux.
Des cellules de la peau aux cellules productrices d’insuline
En recherche sur la thérapie cellulaire moderne, des cellules adultes ordinaires d’un patient peuvent être reprogrammées en un état proche des cellules souches, appelé cellules souches pluripotentes induites. Ces cellules souches peuvent ensuite être guidées au cours d’un processus d’un mois pour devenir des cellules bêta pancréatiques, les cellules qui libèrent l’insuline. En théorie, cela fournit une source personnelle et sans risque de rejet de cellules de remplacement pour les personnes atteintes de diabète de type 1. En pratique, chaque « clone » de cellules souches d’un patient se comporte différemment : certains produisent de nombreuses cellules bêta saines, d’autres très peu. Comme les différences sont subtiles au départ, même des experts qualifiés ne peuvent pas dire de façon fiable dès le début quels clones fonctionneront bien. Cette incertitude contraint les chercheurs à mener des clones faibles tout au long de la procédure de 34 jours, gaspillant des efforts et augmentant les coûts.
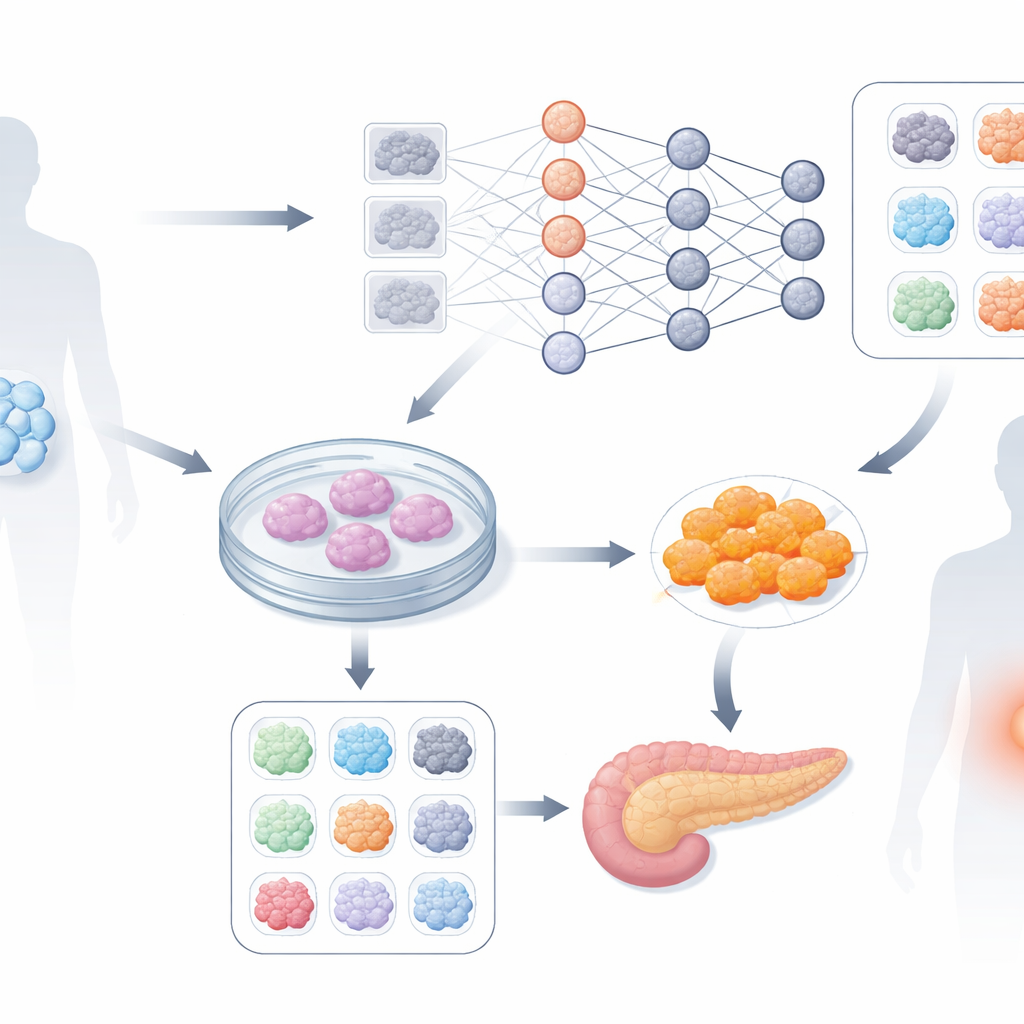
Apprendre aux ordinateurs à lire des motifs cellulaires subtils
Les auteurs ont cherché à savoir si un système d’apprentissage profond — semblable à ceux utilisés en reconnaissance d’images — pouvait repérer des indices visuels précoces dans des images microscopiques simples et sans marquage. Ils ont travaillé avec six clones de cellules souches dérivées de patients, tous orientés vers le même type cellulaire cible. Au lieu d’utiliser des colorations ou une imagerie complexe, ils se sont appuyés sur des images en contraste de phase standard prises toutes les heures pendant les quatre premiers jours de développement. Plus tard, le succès de chaque clone a été mesuré à l’aide d’un marqueur connu au jour 4, qui corrèle avec la capacité des cellules à devenir des cellules bêta fonctionnelles. Les clones ont été regroupés en « bons » et « mauvais » selon ce marqueur, et le réseau neuronal a été entraîné à distinguer ces groupes à partir des seules images précoces.
Quelle est la précision des prédictions
En utilisant un modèle d’apprentissage profond basé sur EfficientNet, les chercheurs ont découpé les images haute résolution en petits morceaux et entraîné le réseau sur de nombreux fragments provenant de chaque clone. Ils ont évalué les performances de deux façons : la fréquence de classification correcte des fragments individuels, et la fréquence à laquelle la prédiction globale pour un clone entier était correcte, en utilisant un système de vote. Alors que les images prises avant le début de la différenciation ne présentaient aucune différence visuelle utile, vers environ deux jours de processus les prévisions du réseau sont devenues remarquablement précises. Vers 53 heures environ, le système identifiait correctement le résultat final pour 96,7 % des clones, fournissant un signal d’alerte précoce solide sur les lots de cellules souches qui valent la peine d’être poursuivis et ceux qui pourraient être arrêtés et relancés avec de nouvelles cellules.
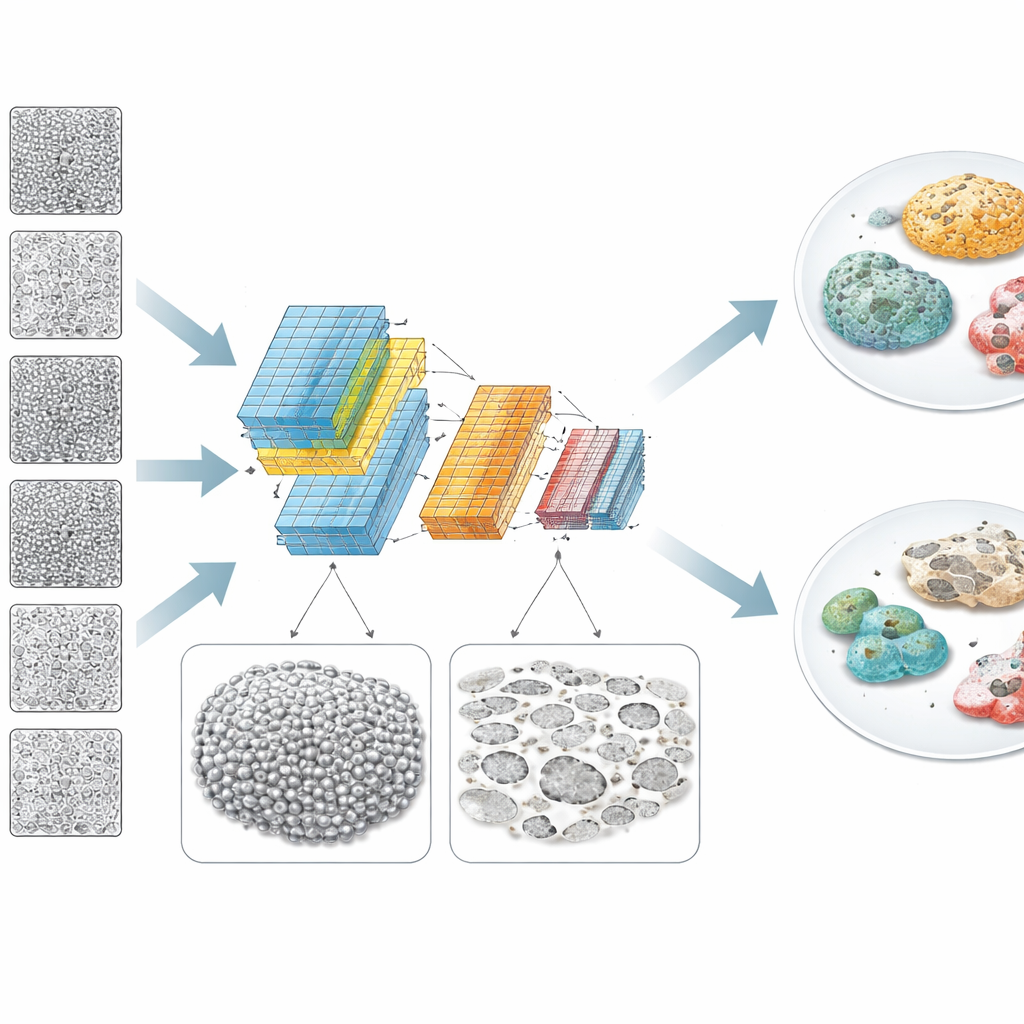
Ce que l’ordinateur « regarde » dans les cellules
Pour dépasser une prédiction en boîte noire, l’équipe a utilisé des outils d’IA explicable et une analyse d’image traditionnelle pour comprendre quelles caractéristiques visuelles importaient. Les cartes de chaleur de l’attention du réseau suggéraient qu’il ne se concentrait pas sur des cellules individuelles, mais sur des motifs plus larges à l’échelle de la nappe cellulaire. Les bons clones avaient tendance à former des couches cellulaires plus continues et uniformes, tandis que les mauvais présentaient davantage de zones vides ou de « trous » et une luminosité inégale sur des régions s’étendant sur des dizaines à des centaines de micromètres. Une analyse mathématique séparée de la structure des images a confirmé cela : pour les mauvais clones, les variations d’intensité étaient plus marquées à des échelles intermédiaires, cohérentes avec une couverture irrégulière et des débris. Les explications du modèle corrélaient avec des mesures simples comme la variance de luminosité, et les auteurs ont montré comment différentes stratégies de normalisation d’image affectaient les performances selon que la culture était propre ou riche en débris.
Vers une thérapie cellulaire plus efficace et abordable
Ce travail est une démonstration précoce mais prometteuse que l’apprentissage profond, combiné à une imagerie vivante très simple, peut servir d’inspecteur automatisé de la qualité précoce pour la production de cellules souches. En signalant les clones faibles après seulement quelques jours, de tels systèmes pourraient réduire les cultures gaspillées et abaisser le coût de production de cellules bêta spécifiques au patient, aidant à rapprocher la thérapie cellulaire pour le diabète de type 1 d’un usage clinique courant. Bien que l’étude ait impliqué seulement six clones et doive être validée sur des jeux de données plus larges et diversifiés, elle montre que des motifs cellulaires subtils à l’échelle de la population contiennent des informations riches que les ordinateurs peuvent exploiter bien avant que l’œil humain ne distingue des différences nettes.
Citation: Schöb, F.J., Binder, A., Zamarian, V. et al. Deep learning for predicting stem cell efficiency for use in beta cell differentiation. Sci Rep 16, 12788 (2026). https://doi.org/10.1038/s41598-026-42830-3
Mots-clés: thérapie cellulaire diabète de type 1, cellules souches pluripotentes induites, microscopie apprentissage profond, différenciation en cellules bêta, contrôle qualité basé sur l’image