Clear Sky Science · de
Deep Learning zur Vorhersage der Effizienz von Stammzellen für die Differenzierung zu Beta-Zellen
Warum diese Forschung für die zukünftige Diabetesversorgung wichtig ist
Für Menschen mit Typ-1-Diabetes ist ein wachsender Traum, verlorene insulinproduzierende Zellen zu ersetzen, statt sich auf lebenslange Injektionen zu verlassen. Wissenschaftler können solche Zellen inzwischen aus den eigenen Stammzellen eines Patienten züchten, doch der Prozess ist langsam, teuer und oft fehleranfällig. Diese Studie zeigt, wie künstliche Intelligenz frühe Mikroskopbilder von Stammzellen analysieren kann und bereits nach wenigen Tagen vorhersagt, welche Chargen voraussichtlich gute insulinproduzierende Zellen ergeben und welche wahrscheinlich enttäuschen werden – was Zeit, Geld und wertvolles biologisches Material sparen könnte.
Von Hautzellen zu insulinbildenden Zellen
In der modernen Zelltherapieforschung können gewöhnliche adulte Zellen eines Patienten zurück in einen stammezellenähnlichen Zustand reprogrammiert werden, die sogenannten induzierten pluripotenten Stammzellen. Diese Stammzellen lassen sich dann über einen etwa einmonatigen Prozess in pankreatische Beta-Zellen führen, jene Zellen, die Insulin freisetzen. Theoretisch bietet das eine persönliche, abstoßungsfreie Quelle von Ersatzzellen für Menschen mit Typ‑1‑Diabetes. Praktisch verhält sich jedoch jede Stammzell-„Klon“-Linie unterschiedlich: Einige liefern viele gesunde Beta-Zellen, andere sehr wenige. Da die Unterschiede zu Beginn subtil sind, können selbst erfahrene Expertinnen und Experten früh nicht zuverlässig vorhersagen, welche Klone gut funktionieren werden. Diese Unsicherheit zwingt Forschende dazu, schwache Klone den kompletten 34-tägigen Ablauf durchlaufen zu lassen, was Aufwand verursacht und die Kosten erhöht.
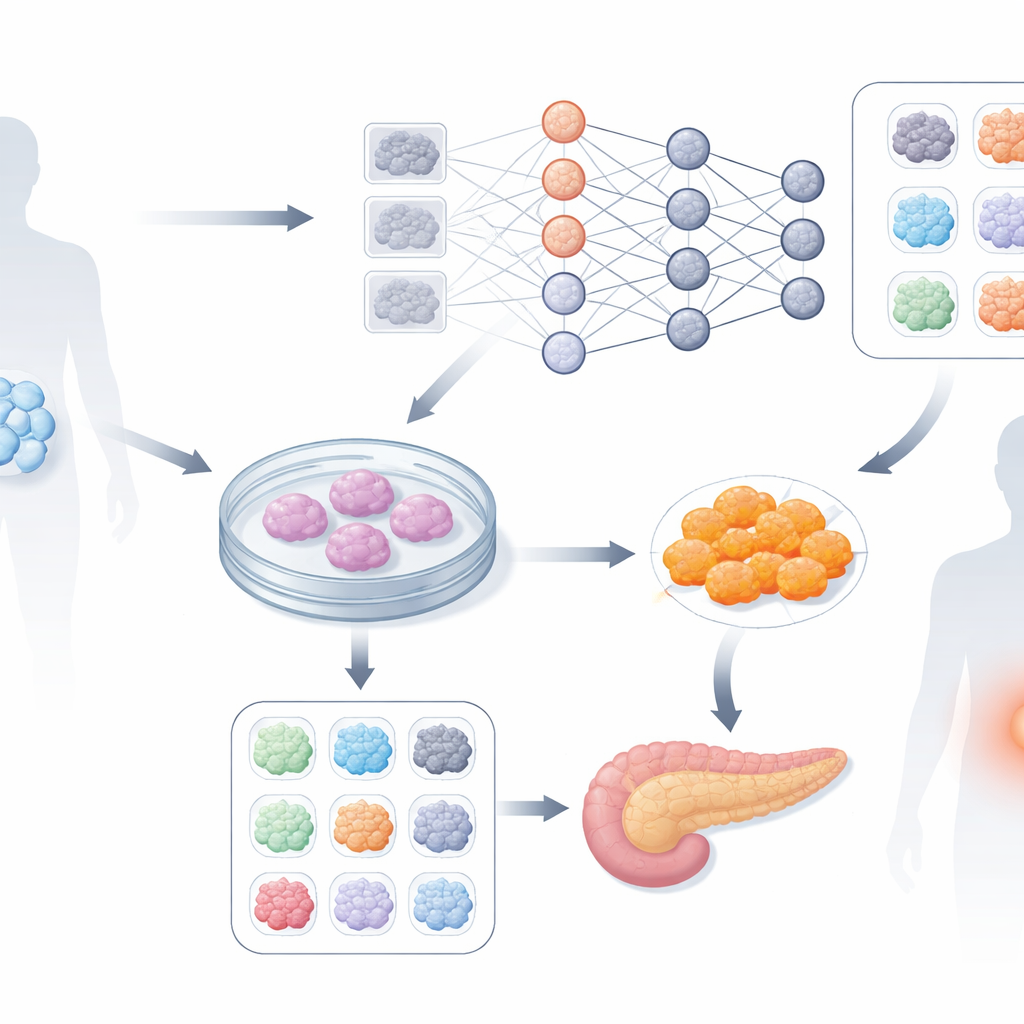
Computern beibringen, subtile Zellmuster zu lesen
Die Autorinnen und Autoren prüften, ob ein Deep‑Learning‑System – ähnlich denen, die in der Bilderkennung eingesetzt werden – frühe visuelle Hinweise in einfachen, ungefärbten Mikroskopaufnahmen erkennen kann. Sie arbeiteten mit sechs patientenabgeleiteten Stammzellklonen, die alle auf denselben Zielzelltyp ausgerichtet waren. Anstatt farbiger Färbungen oder komplexer Bildgebung nutzten sie Standard-Phasenkontrastaufnahmen, die in der ersten Entwicklungswoche stündlich aufgenommen wurden. Den Erfolg jedes Klons maßen sie später anhand eines bekannten Markers am Tag vier, der mit der späteren Fähigkeit der Zellen korreliert, zu funktionellen Beta‑Zellen zu werden. Basierend auf diesem Marker wurden Klone in „gut“ und „schlecht“ gruppiert, und das neuronale Netzwerk wurde darauf trainiert, diese Gruppen allein aus frühen Bildern zu unterscheiden.
Wie gut das System Erfolg voraussehen kann
Mit einem auf EfficientNet basierenden Deep‑Learning‑Modell zerteilten die Forschenden hochauflösende Bilder in kleinere Patches und trainierten das Netzwerk mit vielen solchen Bildausschnitten aus jedem Klon. Die Leistung bewerteten sie auf zwei Arten: wie oft einzelne Patches korrekt klassifiziert wurden und wie oft die Gesamtauskunft für einen ganzen Klon korrekt war, wobei ein Abstimmungsschema verwendet wurde. Während Bilder vor Beginn der Differenzierung keine nützlichen visuellen Unterschiede zeigten, wurden die Vorhersagen des Netzwerks nach etwa zwei Tagen auffallend genau. Bei ungefähr 53 Stunden identifizierte das System das spätere Ergebnis für 96,7 Prozent der Klone korrekt und lieferte damit ein starkes frühes Warnsignal, welche Stammzellchargen es sich lohnt weiterzuführen und welche abgebrochen und mit neuem Material neu begonnen werden sollten.
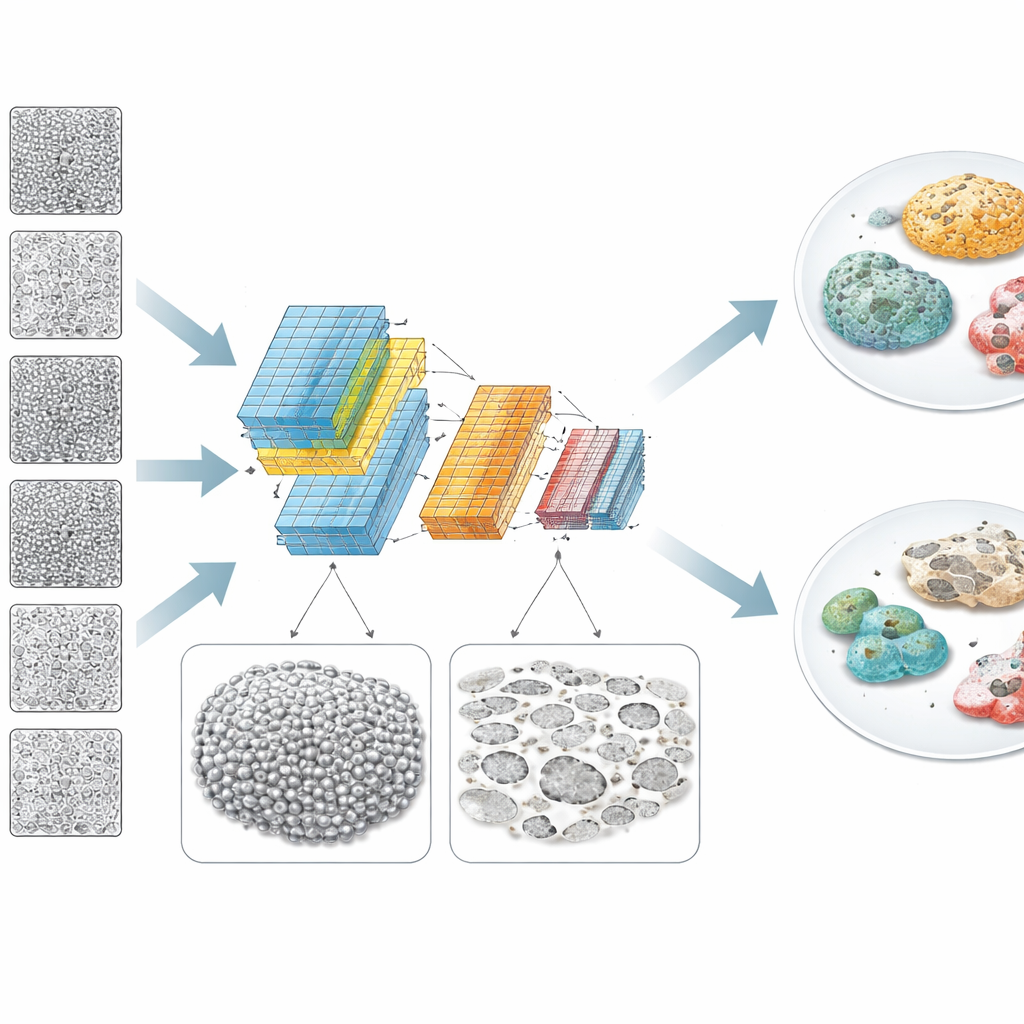
Worauf der Computer in den Zellen "sieht"
Um über eine Black‑Box‑Vorhersage hinauszugehen, nutzte das Team erklärbare KI‑Werkzeuge und traditionelle Bildanalyse, um zu verstehen, welche visuellen Merkmale bedeutsam waren. Heatmaps der Netzwerk‑Aufmerksamkeit legten nahe, dass es sich nicht auf einzelne Zellen konzentrierte, sondern auf breitere Muster über dem Zellblatt. Gute Klone bildeten tendenziell zusammenhängendere, gleichmäßigere Zellschichten, während schlechte Klone mehr leere Stellen oder „Löcher“ und ungleichmäßige Helligkeit über Bereiche im Bereich von zehn bis mehreren hundert Mikrometern zeigten. Eine separate mathematische Analyse der Bildstruktur bestätigte dies: Bei schlechten Klonen waren Intensitätsschwankungen über mittlere Längenskalen stärker ausgeprägt, konsistent mit ungleichmäßiger Bedeckung und Zelltrümmern. Die Erklärungen des Modells korrelierten mit einfachen Kennzahlen wie Helligkeitsvarianz, und die Autorinnen und Autoren zeigten, wie verschiedene Strategien zur Bildnormalisierung die Leistung beeinflussten, abhängig davon, wie sauber oder mit Ablagerungen belastet die Kultur war.
Schritte zu effizienterer und erschwinglicherer Zelltherapie
Diese Arbeit ist eine frühe, aber vielversprechende Demonstration, dass Deep Learning in Verbindung mit sehr einfacher Live‑Zell‑Bildgebung als automatischer Früh‑Qualitätsprüfer bei der Stammzellproduktion dienen kann. Indem schwache Klone bereits nach wenigen Tagen markiert werden, könnten solche Systeme unnötige Kulturdurchläufe reduzieren und die Kosten für die Herstellung patientenspezifischer Beta‑Zellen senken, wodurch Zelltherapie bei Typ‑1‑Diabetes näher an die routinemäßige klinische Anwendung rücken könnte. Obwohl die Studie nur sechs Klone umfasste und an größeren, diverseren Datensätzen validiert werden muss, zeigt sie, dass subtile, populationsweite Zellmuster reichhaltige Informationen enthalten, die Computer deutlich früher nutzen können, als das menschliche Auge klare Unterschiede erkennt.
Zitation: Schöb, F.J., Binder, A., Zamarian, V. et al. Deep learning for predicting stem cell efficiency for use in beta cell differentiation. Sci Rep 16, 12788 (2026). https://doi.org/10.1038/s41598-026-42830-3
Schlüsselwörter: Zelltherapie bei Typ-1-Diabetes, induzierte pluripotente Stammzellen, Tiefenlernen Mikroskopie, Differenzierung zu Beta-Zellen, bildbasierte Qualitätskontrolle