Clear Sky Science · nl
Bio-geoptimaliseerde complex-waardige spatiotemporele GNN voor classificatie van kruiden soorten
Waarom slimme kruididentificatie ertoe doet
Van huismiddeltjes tot moderne geneesmiddelen: veel behandelingen beginnen met het eenvoudige blad. Toch is het moeilijk om de ene medicinale plant van de andere te onderscheiden, zelfs voor experts, en fouten kunnen onderzoek, landbouw en gezondheidszorg beïnvloeden. Deze studie introduceert een computersysteem dat automatisch kruidensoorten identificeert op basis van foto's van hun bladeren, met als doel plantherkenning sneller, nauwkeuriger en gebruiksvriendelijker te maken buiten specialistische laboratoria. 
Bladfoto's omzetten in betrouwbare aanwijzingen
De onderzoekers richten zich op het idee dat een enkel blad een rijke vingerafdruk van zijn soort draagt. Vorm, randpatroon, kleurtonen en nerftextuur coderen allemaal nuttige aanwijzingen. Maar echte foto's zijn rommelig: achtergronden zijn lawaaierig, bladeren overlappen, verlichting varieert en veel soorten lijken misleidend op elkaar. Bestaande hulpmiddelen vertrouwen vaak op een paar handgemaakte kenmerken of eenvoudige deep learning, die kunnen struikelen wanneer bladeren beschadigd zijn, deels verborgen of vermengd met aarde en andere objecten. Het nieuwe systeem is ontworpen om met deze complexiteit om te gaan door de afbeeldingen zorgvuldig te reinigen en vervolgens subtiele visuele patronen dieper te leren dan eerdere benaderingen.
De afbeelding opschonen voordat er een oordeel valt
De eerste fase van het systeem pakt rommelige afbeeldingen aan. Een methode genaamd Multiple Local Particle Filter scant elke foto in kleine regio's en schat in hoe de echte bladpixels eruit zouden moeten zien. In de praktijk verwijdert deze stap spetters, schaduwen en achtergrondrommel terwijl fijne details zoals nervenlijnen en bladranden behouden blijven. Zodra de afbeelding is gereinigd, breekt een techniek genaamd Revised Tunable Q-Factor Wavelet Transform het blad in vele kleine patches van kleur en textuur op verschillende schalen. Dit extraheert niet alleen de omtrek maar ook oppervlaktestructuren en kleurmengingen, zodat het systeem niet alleen afhankelijk is van vorm of alleen van textuur bij het vergelijken van soorten. 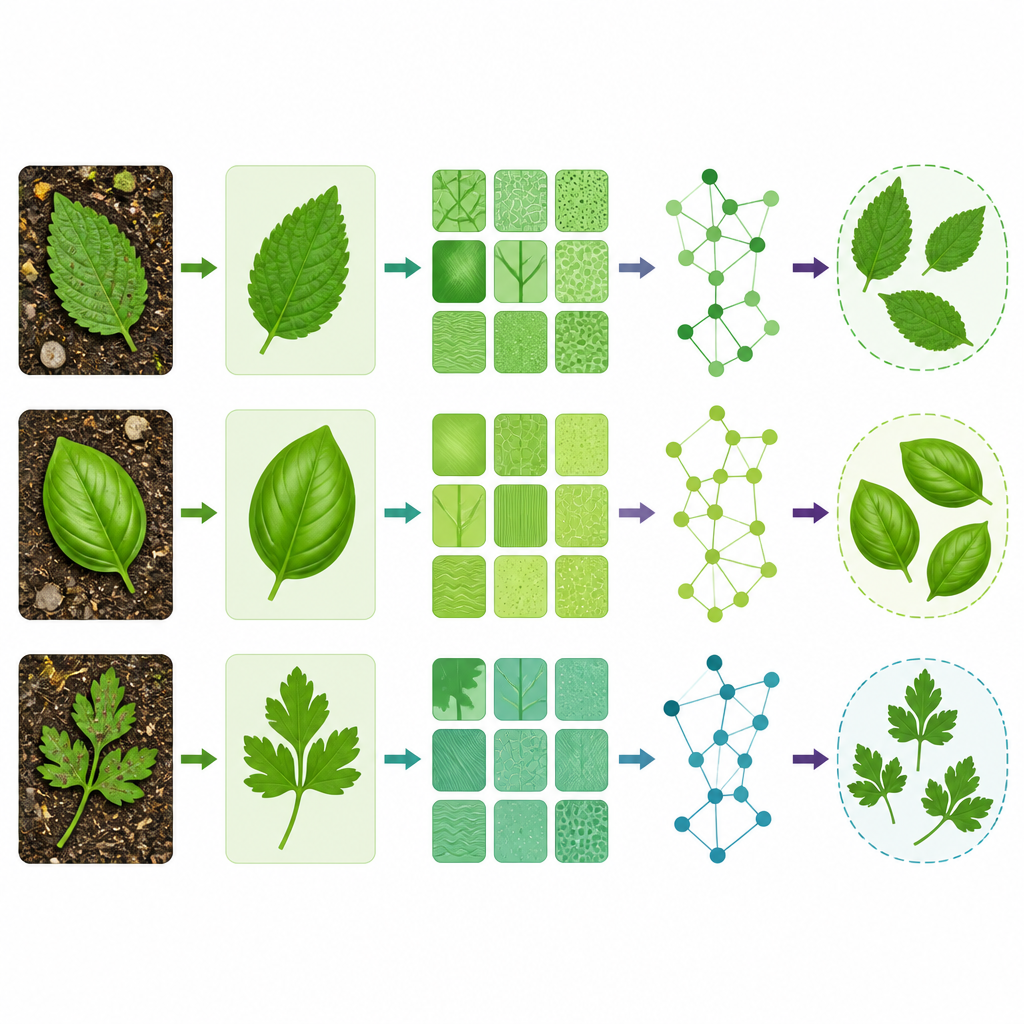
Bladeren lezen als een netwerk van verbonden delen
Na feature-extractie behandelt het systeem elk blad als een netwerk van gerelateerde regio's in plaats van een vlakke afbeelding. Dit gebeurt met een complex-waardig spatiotemporeel graph neural network, dat zowel kan weergeven hoe sterk een visueel patroon is als hoe het georiënteerd is over het bladoppervlak. Nerrichtingen, bijvoorbeeld, worden gestructureerde relaties tussen regio's in plaats van geïsoleerde pixels. Door op deze grafen te leren kan het model soorten onderscheiden die een vergelijkbare omtrek delen maar verschillen in fijnere structuur, zoals hoe nerven zich uitwaaieren of hoe textuur verandert van centrum naar rand. Tests werden uitgevoerd op twee openbare datasets van medicinale bladeren, waaronder de bekende FLAVIA-collectie en een mobiele telefoonset van medische bladeren die realistischere afbeeldingsomstandigheden weerspiegelt.
Een door de natuur geïnspireerde zoektocht het model laten afstemmen
Om de beste prestaties uit deze grafgebaseerde lezer te persen, gebruiken de auteurs een optimalisatiemethode geïnspireerd op het foerageergedrag van mantaroggen. In deze stap worden veel kandidaatinstellingen voor het netwerk verkend, waarbij het algoritme brede zoektocht en fijn afstemmen in balans houdt, vergelijkbaar met dieren die hun zoekgebied afbakenen en vervolgens versmallen tijdens het zoeken naar voedsel. Dit proces stemt de netwerkgewichten af om zowel valse alarmen als gemiste detecties te verminderen. Als gevolg bereikt het systeem ongeveer 99,4 procent nauwkeurigheid, met vergelijkbaar hoge precisie en recall, en behoudt het lage foutpercentages over veel verschillende kruidensoorten en datasets.
Wat dit betekent voor dagelijks gebruik
In eenvoudige termen toont de studie aan dat het combineren van slimmere beeldreiniging, rijkere feature-extractie en een netwerk dat elk blad als een verbonden structuur behandelt automatische kruididentificatie extreem betrouwbaar kan maken. Hoewel de methode nog getest moet worden op meer wilde, realistische foto's en nieuwe soorten, wijst het op hulpmiddelen die boeren, kruidendeskundigen en onderzoekers snel kunnen helpen plantidentiteit te bevestigen met alleen bladbeelden. Bij verdere ontwikkeling zouden dergelijke systemen veiliger gebruik van medicinale planten, betere biodiversiteitstracking en efficiëntere landbouwmonitoring kunnen ondersteunen.
Bronvermelding: Vats, P., Vats, S., Sharma, A. et al. Bio-optimized complex valued spatiotemporal GNN for herbal species classification. Sci Rep 16, 15329 (2026). https://doi.org/10.1038/s41598-026-41760-4
Trefwoorden: classificatie van kruidensoorten, bladbeeldherkenning, graph neural network, computer vision in botanie, geneeskrachtige planten