Clear Sky Science · it
GNN spazotemporale a valori complessi bio-ottimizzata per la classificazione di specie erbacee
Perché l’identificazione intelligente delle erbe è importante
Dai rimedi casalinghi ai farmaci moderni, molti trattamenti nascono dalla semplice foglia. Tuttavia distinguere una pianta medicinale da un’altra è difficile, anche per gli esperti, e gli errori possono influenzare ricerca, agricoltura e assistenza sanitaria. Questo studio presenta un sistema informatico che identifica automaticamente le specie erbacee a partire da foto delle loro foglie, con l’obiettivo di rendere il riconoscimento delle piante più veloce, più accurato e più accessibile anche fuori dai laboratori specialistici. 
Trasformare le foto di foglie in indizi affidabili
I ricercatori si concentrano sull’idea che una singola foglia porta un ricco “impronta” della sua specie. Forma, pattern dei bordi, tonalità di colore e trama delle nervature codificano tutti indizi utili. Ma le foto reali sono disordinate: sfondi rumorosi, foglie sovrapposte, variazioni di illuminazione e molte specie che sembrano ingannevolmente simili. Gli strumenti esistenti spesso si basano su poche caratteristiche progettate a mano o su semplici metodi di deep learning, che possono fallire quando le foglie sono danneggiate, parzialmente nascoste o mescolate con terra e altri oggetti. Il nuovo sistema è progettato per gestire questa complessità ripulendo attentamente le immagini e poi apprendendo pattern visivi sottili più in profondità rispetto agli approcci precedenti.
Ripulire l’immagine prima di decidere
La prima fase del sistema affronta le immagini disordinate. Un metodo chiamato Multiple Local Particle Filter scansiona ogni foto in piccole regioni e stima quali dovrebbero essere i veri pixel della foglia. In pratica, questo passaggio rimuove macchie, ombre e rumore di sfondo preservando dettagli fini come le linee delle nervature e i bordi della foglia. Una volta ripulita, una tecnica denominata Revised Tunable Q-Factor Wavelet Transform suddivide la foglia in numerose piccole patch di colore e texture a diverse scale. Questo estrae non solo il contorno ma anche i pattern superficiali e le mescolanze di colore, così il sistema non dipende esclusivamente dalla forma o dalla sola texture nel confronto tra specie. 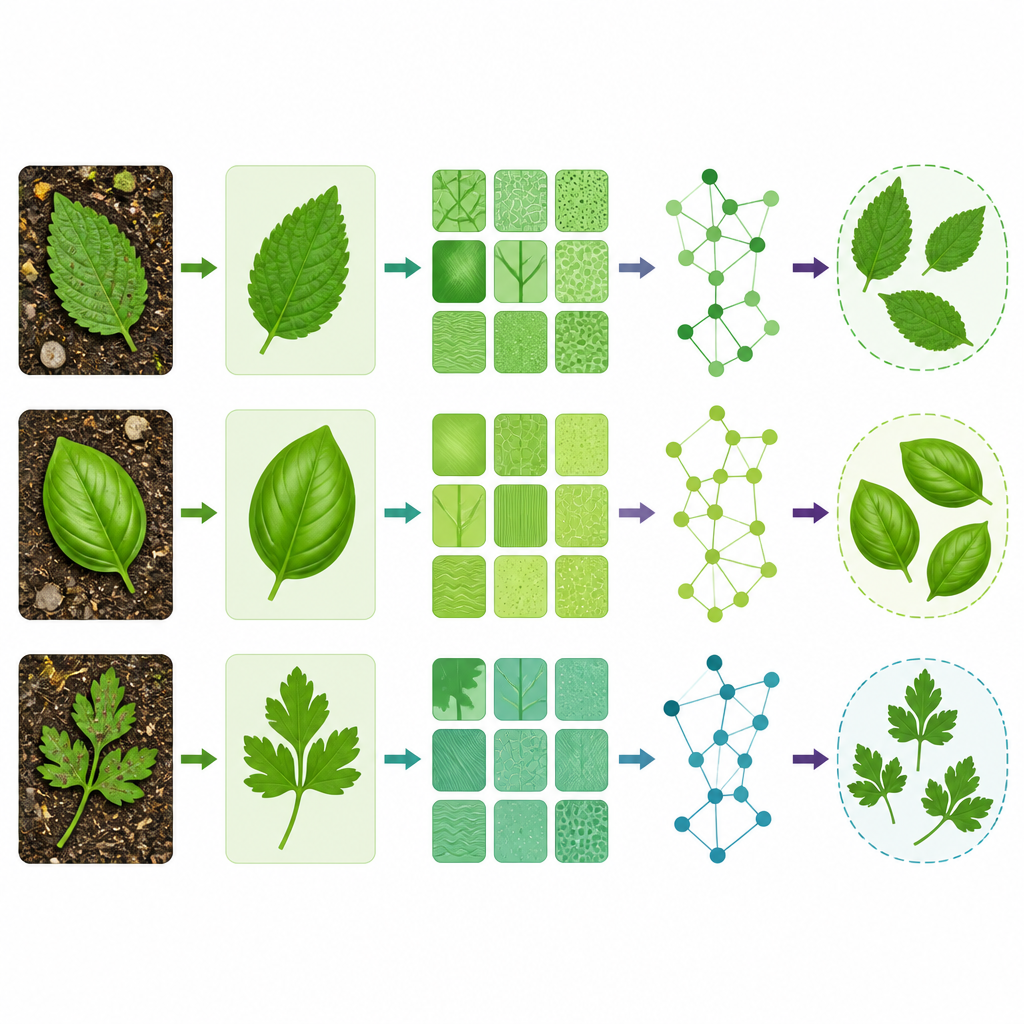
Leggere le foglie come una rete di parti connesse
Dopo l’estrazione delle caratteristiche, il sistema tratta ogni foglia come una rete di regioni correlate piuttosto che come un’immagine piatta. Questo avviene con una rete neurale a grafo spazotemporale a valori complessi, che può rappresentare sia l’intensità di un pattern visivo sia la sua orientazione sulla superficie della foglia. Le direzioni delle nervature, per esempio, diventano relazioni strutturate tra regioni anziché pixel isolati. Apprendendo su questo grafo, il modello distingue specie che condividono un profilo approssimativo ma differiscono nella struttura più fine, come il modo in cui le nervature si diramano o come la texture cambia dal centro al margine. I test sono stati condotti su due dataset pubblici di foglie medicinali, inclusa la nota collezione FLAVIA e un set di immagini da telefoni cellulari che riflette condizioni più realistiche di acquisizione.
Lasciare che una ricerca ispirata alla natura calibrI il modello
Per ottenere le migliori prestazioni da questo apprendimento basato su grafo, gli autori impiegano un metodo di ottimizzazione ispirato al comportamento di foraggiamento delle mante. In questa fase vengono esplorate molte configurazioni candidate per la rete, con l’algoritmo che bilancia ricerca ampia e aggiustamento fine, proprio come gli animali che scandagliano e restringono l’area di ricerca del cibo. Questo processo calibra i pesi della rete per ridurre sia falsi allarmi sia mancate rilevazioni. Di conseguenza, il sistema raggiunge circa il 99,4% di accuratezza, con precisione e recall altrettanto elevati, mantenendo bassi tassi di errore su molte specie erbacee e dataset diversi.
Cosa significa per l’uso quotidiano
In termini semplici, lo studio dimostra che combinare una pulizia delle immagini più intelligente, un’estrazione di caratteristiche più ricca e una rete che considera ogni foglia come una struttura connessa può rendere l’identificazione automatica delle erbe estremamente affidabile. Sebbene il metodo debba ancora essere testato su foto selvatiche più eterogenee e su nuove specie, indica la strada verso strumenti che potrebbero aiutare agricoltori, erboristi e ricercatori a confermare rapidamente l’identità delle piante usando solo immagini delle foglie. Se ulteriormente sviluppati, tali sistemi potrebbero favorire un uso più sicuro delle piante medicinali, un monitoraggio della biodiversità più accurato e una sorveglianza agricola più efficiente.
Citazione: Vats, P., Vats, S., Sharma, A. et al. Bio-optimized complex valued spatiotemporal GNN for herbal species classification. Sci Rep 16, 15329 (2026). https://doi.org/10.1038/s41598-026-41760-4
Parole chiave: classificazione delle specie erbacee, riconoscimento di immagini di foglie, rete neurale a grafo, visione artificiale in botanica, piante medicinali