Clear Sky Science · fr
GNN spatiotemporelle à valeurs complexes optimisée biologiquement pour la classification d’espèces médicinales
Pourquoi l’identification intelligente des plantes médicinales compte
Des remèdes de grand-mère aux médicaments modernes, de nombreux traitements commencent par la modeste feuille. Pourtant, distinguer une plante médicinale d’une autre est difficile, même pour les spécialistes, et les erreurs peuvent nuire à la recherche, à l’agriculture et aux soins de santé. Cette étude présente un système informatique qui identifie automatiquement les espèces à partir de photos de feuilles, visant à rendre la reconnaissance des plantes plus rapide, plus précise et plus facile à utiliser en dehors des laboratoires spécialisés. 
Transformer des photos de feuilles en indices fiables
Les auteurs s’appuient sur l’idée qu’une seule feuille porte une empreinte riche de son espèce. La forme, le motif des bords, les nuances de couleur et la texture des nervures codent tous des indices utiles. Mais les photos réelles sont désordonnées : arrière-plans bruyants, feuilles qui se chevauchent, variations d’éclairage, et nombreuses espèces se ressemblant fortement. Les outils existants s’appuient souvent sur quelques caractéristiques conçues à la main ou sur des approches d’apprentissage profond simples, qui peuvent échouer lorsque les feuilles sont abîmées, partiellement cachées ou mêlées à de la terre et d’autres objets. Le nouveau système est conçu pour gérer cette complexité en nettoyant soigneusement les images, puis en apprenant des motifs visuels subtils plus en profondeur que les approches antérieures.
Nettoyer l’image avant de décider
La première étape du système traite les images encombrées. Une méthode appelée Multiple Local Particle Filter parcourt chaque photo en petites régions et estime à quoi devraient ressembler les vrais pixels de la feuille. En pratique, cette étape supprime les taches, les ombres et le désordre d’arrière-plan tout en préservant des détails fins tels que les nervures et les bords. Une fois l’image nettoyée, une technique nommée Revised Tunable Q-Factor Wavelet Transform découpe la feuille en nombreux petits patchs de couleur et de texture à différentes échelles. Cela extrait non seulement le contour mais aussi les motifs de surface et les dégradés de couleur, de sorte que le système ne dépend ni de la forme seule ni de la texture seule pour comparer les espèces. 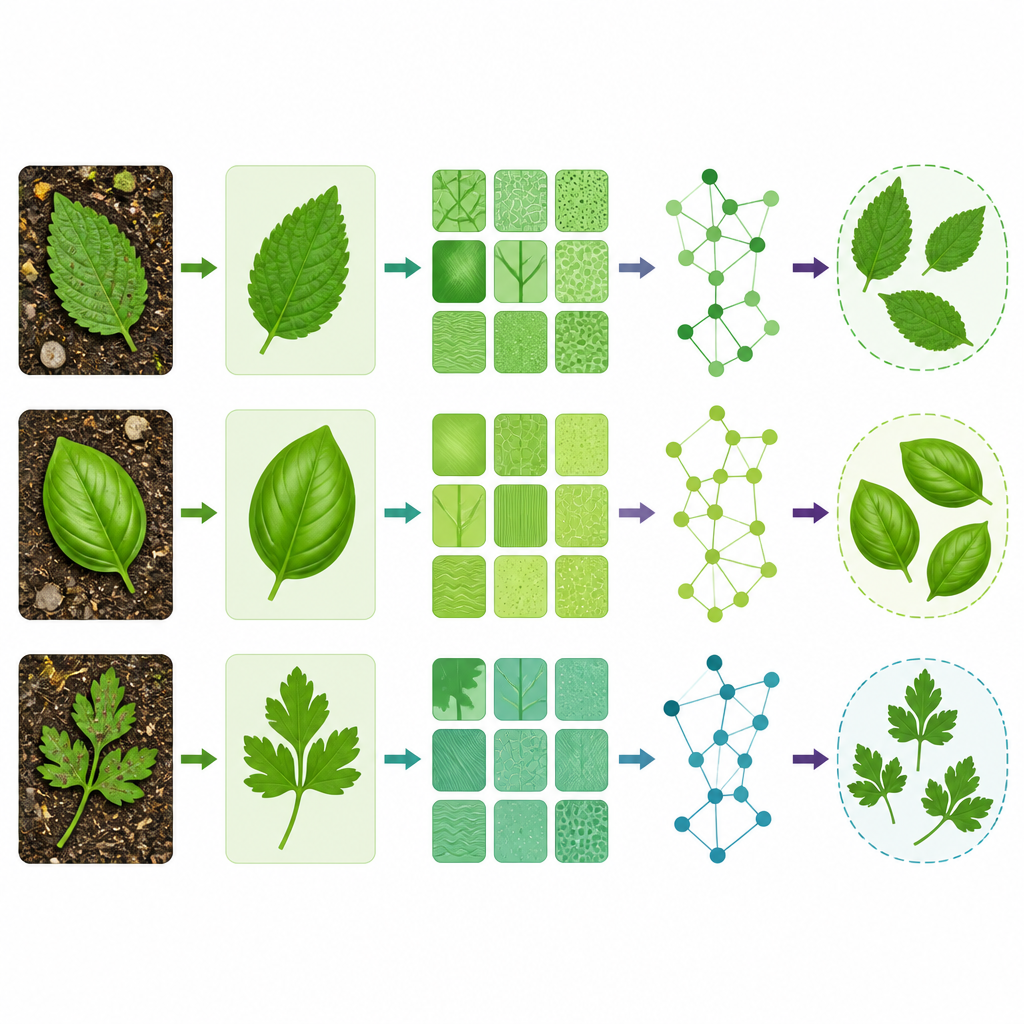
Lire les feuilles comme un réseau de parties connectées
Après l’extraction des caractéristiques, le système considère chaque feuille comme un réseau de régions liées plutôt que comme une image plate. Cela se fait via un réseau de neurones sur graphes spatiotemporel à valeurs complexes, capable de représenter à la fois l’intensité d’un motif visuel et son orientation à la surface de la feuille. Les directions des nervures, par exemple, deviennent des relations structurées entre régions plutôt que des pixels isolés. En apprenant sur ce graphe, le modèle distingue des espèces qui partagent un contour général mais diffèrent par une structure plus fine, comme la façon dont les nervures s’éventent ou comment la texture varie du centre vers le bord. Les tests ont été effectués sur deux jeux de données publics de feuilles médicinales, incluant la bien connue collection FLAVIA et un ensemble de photos prises au téléphone portable reflétant des conditions d’image plus réalistes.
Permettre à une recherche inspirée de la nature d’ajuster le modèle
Pour extraire les meilleures performances de cet apprenant basé sur un graphe, les auteurs utilisent une méthode d’optimisation inspirée du comportement de recherche de nourriture des raies manta. À cette étape, de nombreux paramètres candidats du réseau sont explorés, l’algorithme équilibrant recherche large et ajustement fin, un peu comme des animaux qui balayent puis resserrent leur zone de recherche pour trouver de la nourriture. Ce processus règle les poids du réseau pour réduire à la fois les fausses alertes et les détections manquées. En conséquence, le système atteint environ 99,4 % de précision, avec une précision et un rappel également élevés, et maintient de faibles taux d’erreur sur de nombreuses espèces et jeux de données.
Ce que cela signifie pour un usage quotidien
En termes simples, l’étude montre que combiner un nettoyage d’image plus intelligent, une extraction de caractéristiques plus riche et un réseau qui traite chaque feuille comme une structure liée peut rendre l’identification automatique des plantes médicinales extrêmement fiable. Bien que la méthode doive encore être testée sur davantage de photos sauvages et du monde réel et sur de nouvelles espèces, elle ouvre la voie à des outils qui pourraient aider agriculteurs, herboristes et chercheurs à confirmer rapidement l’identité des plantes à partir de simples images de feuilles. Si elle est développée plus avant, une telle technologie pourrait soutenir un usage plus sûr des plantes médicinales, un meilleur suivi de la biodiversité et une surveillance agricole plus efficace.
Citation: Vats, P., Vats, S., Sharma, A. et al. Bio-optimized complex valued spatiotemporal GNN for herbal species classification. Sci Rep 16, 15329 (2026). https://doi.org/10.1038/s41598-026-41760-4
Mots-clés: classification d’espèces médicinales, reconnaissance d’images de feuilles, réseau de neurones sur graphes, vision par ordinateur en botanique, plantes médicinales