Clear Sky Science · nl
Rampenverhalen en kennisgrafen uit wereldnieuws met grote taalmodellen en retrieval-augmented generation
Van koppen naar behulpzame verhalen
Wanneer een overstroming, bosbrand of epidemie toeslaat, stromen nieuwsberichten sneller binnen dan officiële statistieken of gedetailleerde onderzoeken. In deze artikelen liggen aanwijzingen over wat er gebeurde, wie het hardst werd getroffen en welke acties hielpen. Dit artikel beschrijft een nieuwe open dataset die geavanceerde AI gebruikt om een decennium aan wereldwijde rampennieuws om te zetten in gestructureerde verhalen en kaarten van oorzaak en gevolg, zodat onderzoekers, planners en hulpdiensten beter kunnen begrijpen hoe rampen verlopen en hoe risico’s met elkaar verbonden zijn.
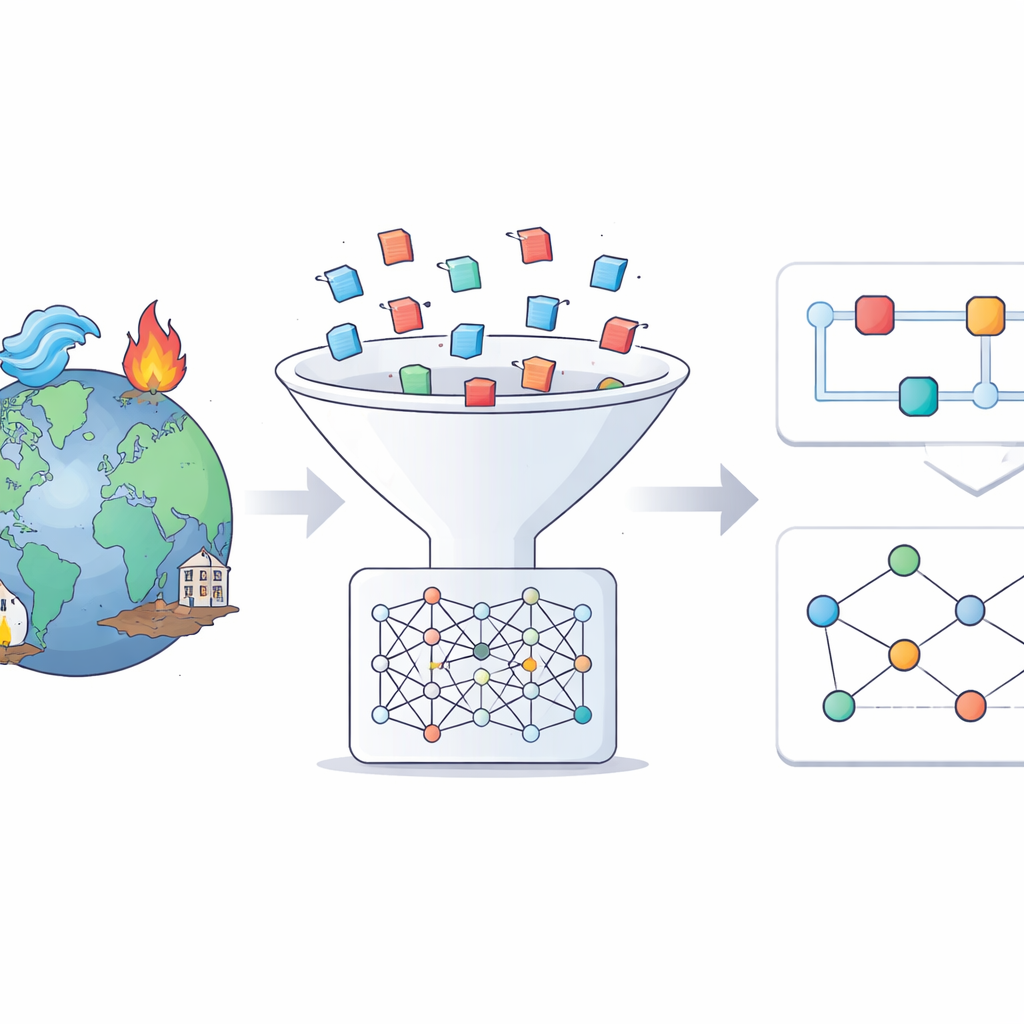
Van rauw nieuws naar gestructureerde gebeurtenisverhalen
De auteurs vertrekken van een betrouwbaar wereldwijd rampencatalogus genaamd EM-DAT, dat duizenden grote gebeurtenissen wereldwijd vermeldt. Voor elk evenement tussen 2014 en 2024 doorzoeken ze een enorme meertalige nieuwsarchief, de Europe Media Monitor, met nadruk op Engelstalige berichtgeving. Met moderne AI‑hulpmiddelen zeven ze miljoenen artikelen om die te vinden die daadwerkelijk over een specifieke overstroming, aardbeving, hittegolf of andere bedreiging gaan. Slechts een klein deel van de opgehaalde artikelen doorstaat dit filter, maar degenen die dat wel doen leveren rijke, gerichte informatie over elk evenement.
Hoe AI verhalen en oorzaak‑gevolgkaarten bouwt
Zodra de relevante artikelen zijn verzameld, wordt een groot taalmodel gevraagd om voor elke ramp een gestructureerde feitenfiche, of “storyline”, te schrijven. Deze narratieven volgen een duidelijk sjabloon: wat er gebeurde en waar, hoe ernstig het was, de belangrijkste drijfveren, wie en wat blootgesteld waren, de belangrijkste gevolgen, mogelijke kettingreacties en de reacties en herstelmaatregelen. In een tweede stap leest hetzelfde type model de storyline en haalt het eenvoudige oorzaak‑gevolgstellingen eruit in de vorm van triples zoals “zware neerslag veroorzaakt plotselinge overstromingen” of “vroege waarschuwingssystemen voorkomen slachtoffers.” Deze uitspraken worden vervolgens samengevoegd in kennisgrafen — netwerkachtige diagrammen die gevaren, drijfveren, gevolgen en reacties met elkaar verbinden.
Wat de nieuwe dataset bevat
De resulterende dataset bestrijkt 3.158 rampgebeurtenissen in 175 landen en 26 typen gevaren, van aardbevingen en stormen tot droogtes en epidemieën. Elke rij in een enkele CSV‑bestand bevat standaardinformatie uit EM‑DAT naast de door AI geschreven storyline en de geëxtraheerde oorzaak‑gevolgtriples. Een online dashboard laat gebruikers evenementen doorzoeken op land, type en gebeurteniscodes, en vervolgens zowel het narratief als de bijbehorende grafiek inspecteren. Hoewel het systeem slechts ongeveer de helft van alle EM‑DAT‑gebeurtenissen in het decennium vastlegt, omvat het ongeveer 80% van de gerapporteerde economische verliezen, wat de intense mediabelangstelling voor de meest schadelijke rampen weerspiegelt.
Kwaliteit testen met veldexperts
Aangezien rampenrisicobeheer een domein met hoge inzet is, testte het team zorgvuldig hoe betrouwbaar hun AI‑gegenereerde grafen zijn. Zes experts onderzochten 1.000 willekeurig geselecteerde oorzaak‑gevolguitspraken en beoordeelden of elk statement werd ondersteund door de brontekst. In totaal werd bijna twee derde van de uitspraken door een meerderheid als correct beoordeeld, met matige overeenstemming tussen de experts. In een aparte workshop beoordeelden ongeveer 30 rampenprofessionals van Europese civiele bescherming 34 volledige grafen. De meeste beoordelingen vielen in “volledig correct” of “grotendeels correct”, vooral voor beter gedocumenteerde gebeurtenissen zoals overstromingen en stormen. Een kleine online enquête wees uit dat deelnemers de verhalen over het algemeen als nauwkeurig en de grafen als enigszins nuttig beschouwden om complexe situaties te doorgronden.
Waarom dit ertoe doet voor toekomstige rampen
Voor het brede publiek en beleidsmakers is de kernboodschap dat dit project laat zien hoe AI kan helpen greep te krijgen op overweldigende stromen rampennieuws. Door verspreide berichten te transformeren in consistente verhalen en eenvoudige kaarten van wat tot wat leidt, ondersteunt de dataset betere risicoanalyses, scenario‑planning en ontwerp van vroege waarschuwingen. De auteurs benadrukken dat hun grafen geen perfecte of volledige modellen van de werkelijkheid zijn, en dat nieuwsbronnen en Engelstalige vooringenomenheid belangrijke hiaten laten. Toch kunnen anderen, omdat alle data, code en prompts openlijk gedeeld worden, de aanpak verfijnen, uitbreiden en aanpassen. Op de lange termijn kunnen dergelijke hulpmiddelen samenlevingen helpen sneller en verstandiger te reageren wanneer de volgende crisis toeslaat.
Bronvermelding: Ronco, M., Bandelli, L., Bertolini, L. et al. Disaster Storylines and Knowledge Graphs from Global News with Large Language Models and Retrieval-Augmented Generation. Sci Data 13, 689 (2026). https://doi.org/10.1038/s41597-026-07036-2
Trefwoorden: rampenrisico, kennisgrafen, nieuwsgegevens, grote taalmodellen, vroege waarschuwing