Clear Sky Science · de
Katastrophen-Storylines und Wissensgraphen aus globalen Nachrichten mit großen Sprachmodellen und Retrieval-Augmented Generation
Schlagzeilen in hilfreiche Geschichten verwandeln
Wenn eine Überschwemmung, ein Waldbrand oder eine Epidemie ausbricht, treffen Nachrichtenmeldungen meist schneller ein als offizielle Statistiken oder detaillierte Studien. In diesen Artikeln verbergen sich Hinweise darauf, was geschehen ist, wer am stärksten betroffen war und welche Maßnahmen geholfen haben. Dieses Papier beschreibt einen neuen offenen Datensatz, der mit fortschrittlicher KI ein Jahrzehnt globaler Katastrophennachrichten in strukturierte Geschichten und Ursache‑Wirkungs‑Karten überführt, um Forschenden, Planer*innen und Rettungsdiensten ein besseres Verständnis dafür zu ermöglichen, wie Katastrophen sich entfalten und wie Risiken zusammenhängen.
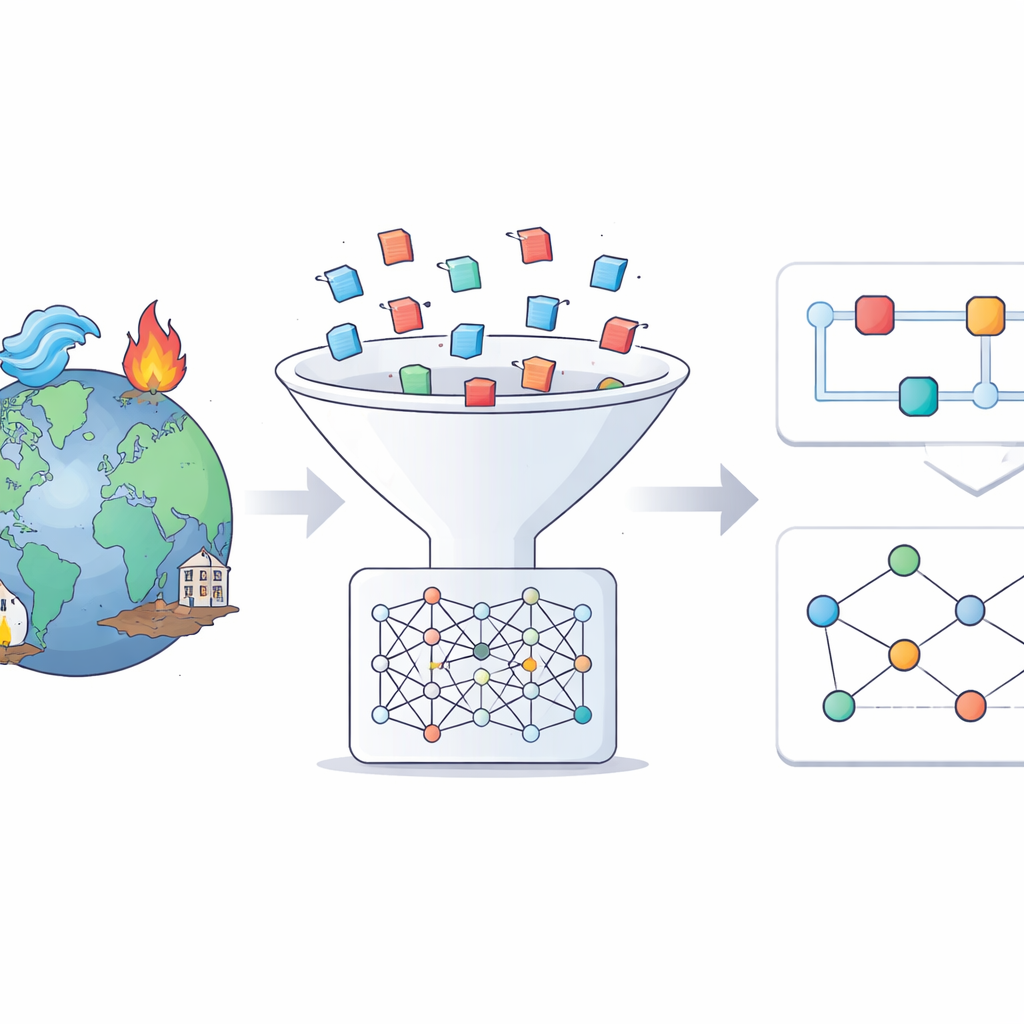
Von rohen Nachrichten zu strukturierten Ereignisgeschichten
Die Autor*innen starten mit einem vertrauenswürdigen globalen Katastrophenkatalog namens EM‑DAT, der Tausende großer Ereignisse weltweit auflistet. Für jedes Ereignis zwischen 2014 und 2024 durchsuchen sie ein riesiges mehrsprachiges Nachrichtenarchiv, den Europe Media Monitor, mit Schwerpunkt auf englischsprachiger Berichterstattung. Mit modernen KI‑Werkzeugen sichten sie Millionen von Artikeln, um diejenigen zu finden, die tatsächlich über ein bestimmtes Hochwasser, Erdbeben, eine Hitzewelle oder eine andere Gefahr berichten. Nur ein kleiner Teil der gefundene n Artikel übersteht diesen Filter, doch die erhaltenen Texte liefern reichhaltige, fokussierte Informationen zu jedem Ereignis.
Wie KI Narrative und Ursache‑Wirkungs‑Karten erstellt
Sobald die relevanten Artikel gesammelt sind, wird ein großes Sprachmodell gebeten, für jede Katastrophe ein strukturiertes Factsheet oder eine „Storyline“ zu schreiben. Diese Erzählungen folgen einer klaren Vorlage: was und wo etwas geschehen ist, wie schwerwiegend es war, die wichtigsten Treiber, wer und was exponiert war, die zentralen Auswirkungen, mögliche Folgerisiken sowie Maßnahmen zu Reaktion und Wiederaufbau. In einem zweiten Schritt liest dasselbe Modell die Storyline und extrahiert einfache Ursache‑Wirkungs‑Aussagen in Form von Tripeln wie „starke Niederschläge verursachen Sturzfluten“ oder „Frühwarnsysteme verhindern Opfer“. Diese Aussagen werden anschließend zu Wissensgraphen zusammengesetzt — netzwerkähnlichen Diagrammen, die Gefahren, Treiber, Auswirkungen und Reaktionen verbinden.
Was der neue Datensatz enthält
Der resultierende Datensatz erfasst 3.158 Katastrophenereignisse in 175 Ländern und 26 Gefahrenarten, von Erdbeben und Stürmen bis zu Dürren und Epidemien. Jede Zeile einer einzigen CSV‑Datei enthält Standardinformationen aus EM‑DAT neben der KI‑verfassten Storyline und den extrahierten Ursache‑Wirkungs‑Tripeln. Ein Online‑Dashboard erlaubt es Nutzenden, Ereignisse nach Land, Typ und Ereigniscode zu durchsuchen und sowohl die Narrative als auch den zugehörigen Graphen einzusehen. Obwohl das System im betrachteten Jahrzehnt nur etwa die Hälfte aller EM‑DAT‑Ereignisse erfasst, umfasst es rund 80 % der gemeldeten wirtschaftlichen Verluste, was die starke Medienaufmerksamkeit für die schädlichsten Katastrophen widerspiegelt.
Qualitätstest mit Fachleuten aus dem Feld
Da Katastrophenrisikomanagement ein Bereich mit hohen Einsätzen ist, prüfte das Team sorgfältig, wie vertrauenswürdig ihre KI‑generierten Graphen sind. Sechs Expert*innen untersuchten 1.000 zufällig ausgewählte Ursache‑Wirkungs‑Aussagen und bewerteten, ob jede einzelne durch den Quelltext gestützt wird. Insgesamt wurden fast zwei Drittel der Aussagen von der Mehrheitsmeinung als korrekt eingestuft, mit moderater Übereinstimmung zwischen den Expert*innen. In einem separaten Workshop überprüften etwa 30 Katastrophenfachleute aus europäischen Zivilschutzbehörden 34 vollständige Graphen. Die meisten Bewertungen fielen in die Kategorien „vollständig korrekt“ oder „größtenteils korrekt“, insbesondere für besser dokumentierte Ereignisse wie Überschwemmungen und Stürme. Eine kleine Online‑Umfrage ergab, dass Teilnehmende die Narrative im Allgemeinen als zutreffend und die Graphen als einigermaßen nützlich für das Verständnis komplexer Situationen einschätzten.
Warum das für künftige Katastrophen wichtig ist
Für die breite Öffentlichkeit und Entscheidungstragende ist die Kernbotschaft, dass dieses Projekt zeigt, wie KI helfen kann, überwältigende Mengen an Katastrophennachrichten zu ordnen. Indem verstreute Berichte in konsistente Geschichten und einfache Karten dessen umgesetzt werden, was zu was führt, unterstützt der Datensatz bessere Risikoabschätzungen, Szenarioplanung und die Gestaltung von Frühwarnsystemen. Die Autor*innen betonen, dass ihre Graphen keine perfekten oder vollständigen Abbildungen der Realität sind und dass Nachrichtenquellen sowie die Fokussierung auf englischsprachige Berichterstattung wichtige Lücken hinterlassen. Dennoch können andere die offen geteilten Daten, Codes und Prompt‑Vorlagen verfeinern, erweitern und anpassen. Langfristig könnten solche Werkzeuge Gesellschaften dabei helfen, beim nächsten Krisenfall schneller und klüger zu reagieren.
Zitation: Ronco, M., Bandelli, L., Bertolini, L. et al. Disaster Storylines and Knowledge Graphs from Global News with Large Language Models and Retrieval-Augmented Generation. Sci Data 13, 689 (2026). https://doi.org/10.1038/s41597-026-07036-2
Schlüsselwörter: Katastrophenrisiko, Wissensgraphen, Nachrichtendaten, große Sprachmodelle, Frühwarnung