Clear Sky Science · it
Trame di catastrofi e grafi di conoscenza dai notiziari globali con grandi modelli linguistici e generazione aumentata da retrieval
Trasformare i titoli in storie utili
Quando si verifica un’alluvione, un incendio boschivo o un’epidemia, i resoconti giornalistici arrivano molto più rapidamente rispetto alle statistiche ufficiali o agli studi dettagliati. Sepolti in questi articoli ci sono indizi su cosa è successo, chi è stato colpito più duramente e quali azioni hanno funzionato. Questo articolo descrive un nuovo dataset aperto che utilizza l’IA avanzata per trasformare un decennio di notizie globali sulle catastrofi in storie strutturate e mappe di causa-effetto, aiutando ricercatori, pianificatori e servizi di emergenza a comprendere meglio come si sviluppano i disastri e come i rischi sono collegati.
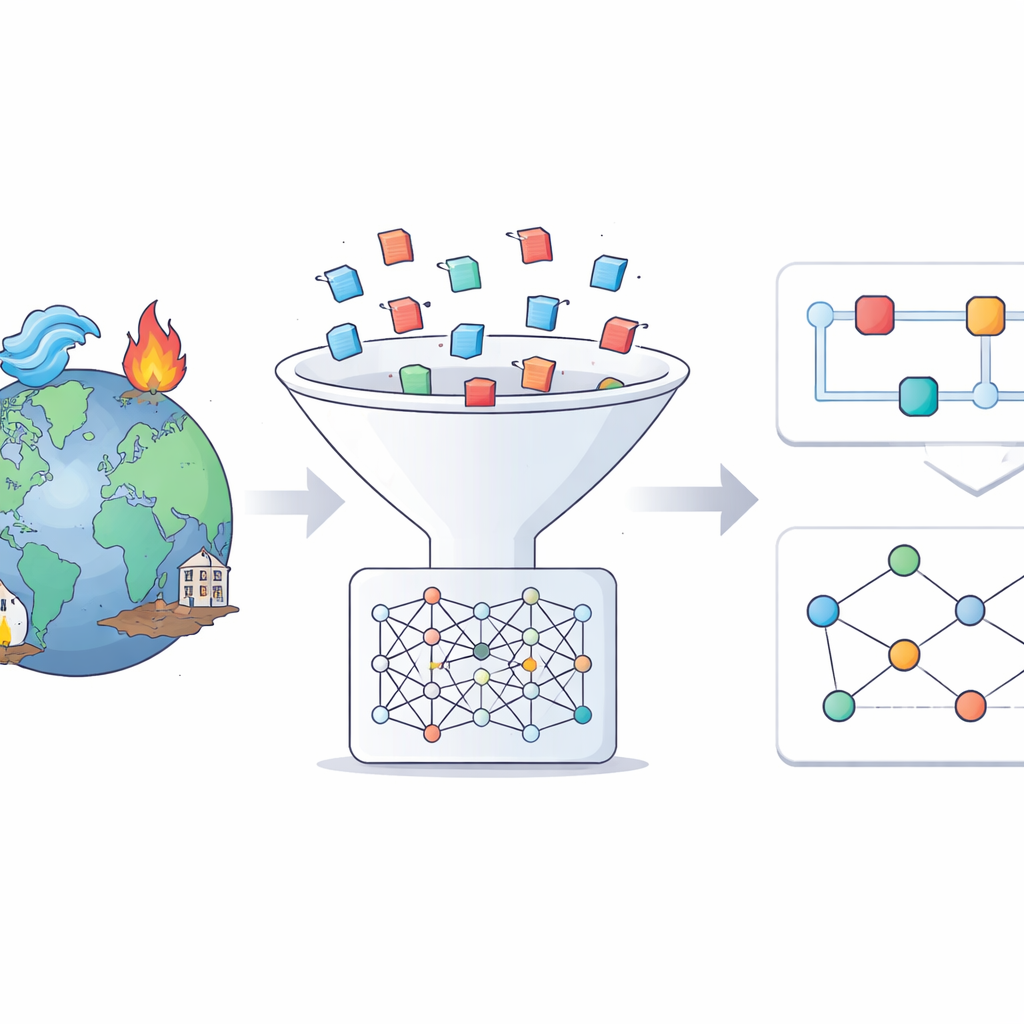
Dalle notizie grezze alle storie di eventi strutturate
Gli autori partono da un catalogo globale affidabile delle catastrofi chiamato EM-DAT, che elenca migliaia di eventi importanti nel mondo. Per ogni evento tra il 2014 e il 2024, cercano in un vasto archivio di notizie multilingue, l’Europe Media Monitor, concentrandosi sulla copertura in lingua inglese. Usando strumenti IA moderni, setacciano milioni di articoli per trovare quelli che trattano effettivamente uno specifico allagamento, terremoto, ondata di calore o altro pericolo. Solo una piccola frazione degli articoli recuperati supera questo filtro, ma quelli che lo fanno forniscono informazioni ricche e focalizzate su ciascun evento.
Come l’IA costruisce narrazioni e mappe di causa-effetto
Una volta raccolti gli articoli rilevanti, a un grande modello linguistico viene chiesto di redigere una scheda informativa strutturata, o “trama”, per ciascuna catastrofe. Queste narrazioni seguono un modello chiaro: cosa è successo e dove, quanto è stata grave la situazione, i principali fattori scatenanti, chi e cosa è stato esposto, gli impatti chiave, i possibili rischi a catena e le misure di risposta e recupero. In una seconda fase, lo stesso tipo di modello legge la trama ed estrae dichiarazioni semplici di causa-effetto sotto forma di triple, ad esempio “forti precipitazioni causano allagamenti improvvisi” o “i sistemi di allerta precoce prevengono vittime”. Queste affermazioni vengono poi assemblate in grafi di conoscenza — diagrammi a rete che collegano pericoli, fattori scatenanti, impatti e risposte.
Cosa contiene il nuovo dataset
Il dataset risultante copre 3.158 eventi catastrofici in 175 paesi e 26 tipi di pericoli, dai terremoti e tempeste alle siccità e alle epidemie. Ogni riga di un singolo file CSV contiene informazioni standard tratte da EM-DAT insieme alla trama scritta dall’IA e alle triple di causa-effetto estratte. Una dashboard online permette agli utenti di sfogliare gli eventi per paese, tipo e codice evento, e poi ispezionare sia la narrazione sia il grafo corrispondente. Sebbene il sistema catturi solo circa la metà di tutti gli eventi EM-DAT nel corso del decennio, include circa l’80% delle perdite economiche riportate, riflettendo l’intensa attenzione mediatica riservata ai disastri più dannosi.
Testare la qualità con esperti del settore
Poiché la gestione del rischio di catastrofi è un ambito ad alto rischio, il team ha testato con cura quanto siano affidabili i loro grafi generati dall’IA. Sei esperti hanno esaminato 1.000 dichiarazioni di causa-effetto campionate casualmente e hanno valutato se ciascuna fosse supportata dal testo sorgente. Nel complesso, quasi due terzi delle affermazioni sono state giudicate corrette da voto di maggioranza, con un accordo moderato tra gli esperti. In un workshop separato, circa 30 professionisti della protezione civile europei hanno revisionato 34 grafi completi. La maggior parte delle valutazioni è ricaduta in “completamente corretto” o “per lo più corretto”, specialmente per eventi meglio documentati come inondazioni e tempeste. Un piccolo sondaggio online ha rilevato che i partecipanti consideravano generalmente le narrazioni accurate e i grafi utili in certa misura per comprendere situazioni complesse.
Perché questo è importante per le catastrofi future
Per il pubblico generale e i decisori, il messaggio chiave è che questo progetto dimostra come l’IA possa aiutare a dare senso a flussi travolgenti di notizie sulle catastrofi. Trasformando resoconti dispersi in storie coerenti e mappe semplici di cosa conduce a cosa, il dataset supporta migliori valutazioni del rischio, pianificazione di scenari e progettazione di sistemi di allerta precoce. Gli autori sottolineano che i loro grafi non sono modelli perfetti o completi della realtà, e che le fonti giornalistiche e il bias della lingua inglese lasciano vuoti importanti. Tuttavia, poiché tutti i dati, il codice e i prompt sono condivisi apertamente, altri possono raffinare, ampliare e adattare l’approccio. A lungo termine, tali strumenti potrebbero aiutare le società a rispondere più rapidamente e in modo più intelligente quando colpirà la prossima crisi.
Citazione: Ronco, M., Bandelli, L., Bertolini, L. et al. Disaster Storylines and Knowledge Graphs from Global News with Large Language Models and Retrieval-Augmented Generation. Sci Data 13, 689 (2026). https://doi.org/10.1038/s41597-026-07036-2
Parole chiave: rischio di disastro, grafi di conoscenza, dati di notizie, grandi modelli linguistici, allerta precoce