Clear Sky Science · nl
Een informatietheoretische benadering om de sequentie-afhankelijke respons van nucleïnezuurmotoren te kwantificeren met toepassingen voor nanopore-DNA-sequencing
DNA lezen met piepkleine machientjes
Elke cel in je lichaam is afhankelijk van microscopische machientjes die langs DNA kruipen om het te kopiëren en te repareren. Datzelfde soort machientjes drijft nu snelle DNA-sequencingapparaten aan. Deze studie stelt een ogenschijnlijk eenvoudige vraag met grote implicaties: naast de gebruikelijke elektrische signalen die bij nanopore-sequencing worden gebruikt, hoeveel extra informatie over de DNA-sequentie is verborgen in de manier waarop deze kleine machientjes bewegen — hoe lang ze pauzeren en hoe vaak ze achteruit stappen? Met instrumenten uit de informatietheorie laten de auteurs zien dat deze subtiele bewegingen de nauwkeurigheid van het lezen van DNA aanzienlijk kunnen verhogen, en ze schetsen hoe men in de toekomst betere moleculaire motoren kan ontwerpen voor sequencingtechnologieën.
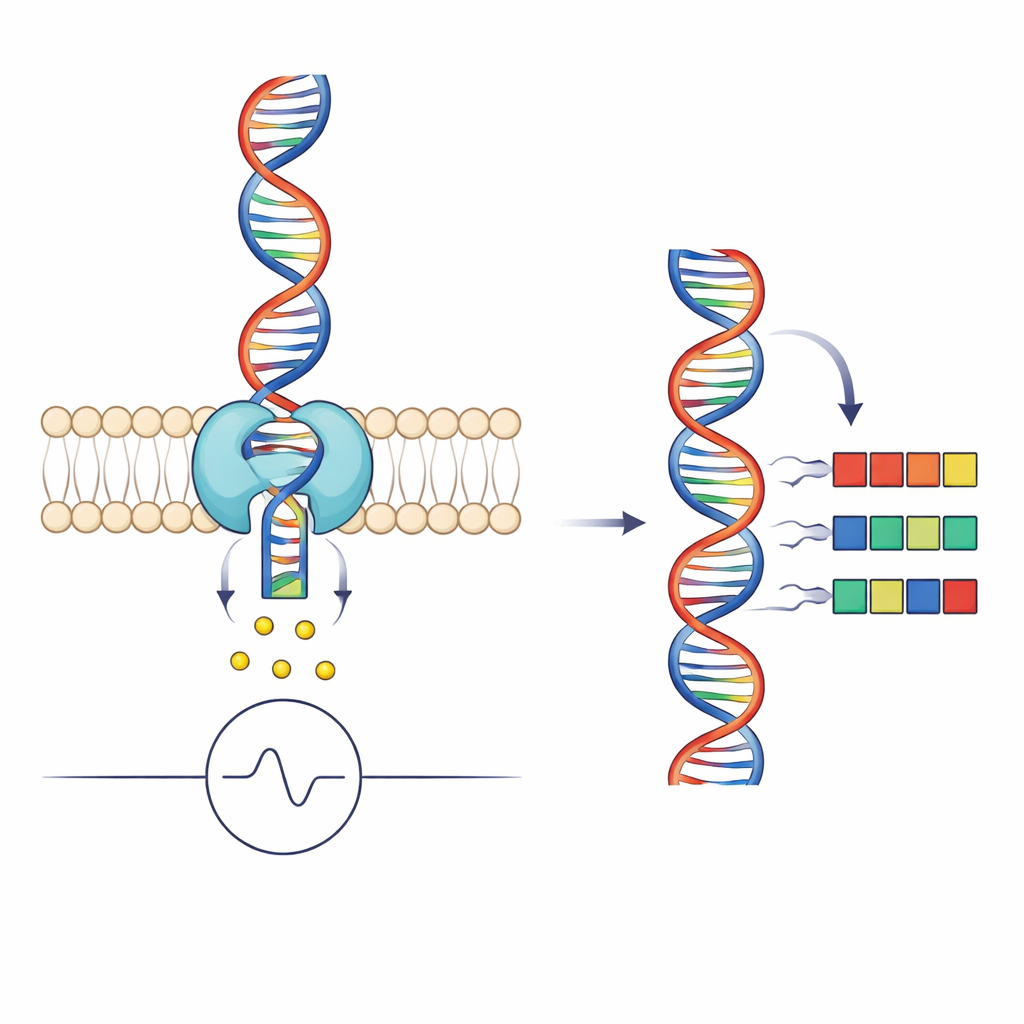
Hoe nanopores DNA in signalen omzetten
Nanopore-sequencing werkt door een enkele DNA-streng door een piepklein gat in een membraan te leiden terwijl de stroom van ionen door de porie wordt gemeten. Wanneer verschillende groepen DNA-basen het smalste deel van de porie bezetten, blokkeren ze de stroom op kenmerkende manieren, wat een elektrisch patroon oplevert dat ontcijferd kan worden tot een sequentie. Een motorenzym, hier een helicase genaamd Hel308, grijpt het DNA en voert het in kleine stappen door de porie. Elke sequencing‑"read" is dus niet alleen een stroomtrace, maar ook een gedetailleerd verslag van hoe de helicase beweegt: hoe lang hij op elke positie wacht en of hij af en toe achteruit glijdt.
Verborgen aanwijzingen meten met informatietheorie
De auteurs gebruiken een concept dat wederzijdse informatie (mutual information) heet om te kwantificeren hoe sterk de DNA-sequentie verschillende waarneembare signalen aanstuurt: de ionenstroom, de tijd die Hel308 op elke stap doorbrengt, en de kans dat hij achteruit stapt. Wederzijdse informatie, gemeten in bits, beantwoordt de vraag: hoeveel kunnen we gemiddeld van een DNA-base leren uit een gegeven signaal? Door duizenden metingen te analyseren, ontdekken ze dat de ionenstroom het meest gevoelig is voor een korte stretch van ongeveer vier basen in de porievernauwing, terwijl de beweging van Hel308 voornamelijk wordt bepaald door basen op 16–21 posities afstand. In het bijzonder beïnvloeden basen op twee posities (ongeveer 17 en 20 nucleotiden van de porie) sterk hoe lang het enzym verblijft en hoe waarschijnlijk het is dat het achteruit stapt. Het combineren van verblijftijd en achteruitstapgedrag onthult meer over deze basen dan elk kenmerk afzonderlijk.
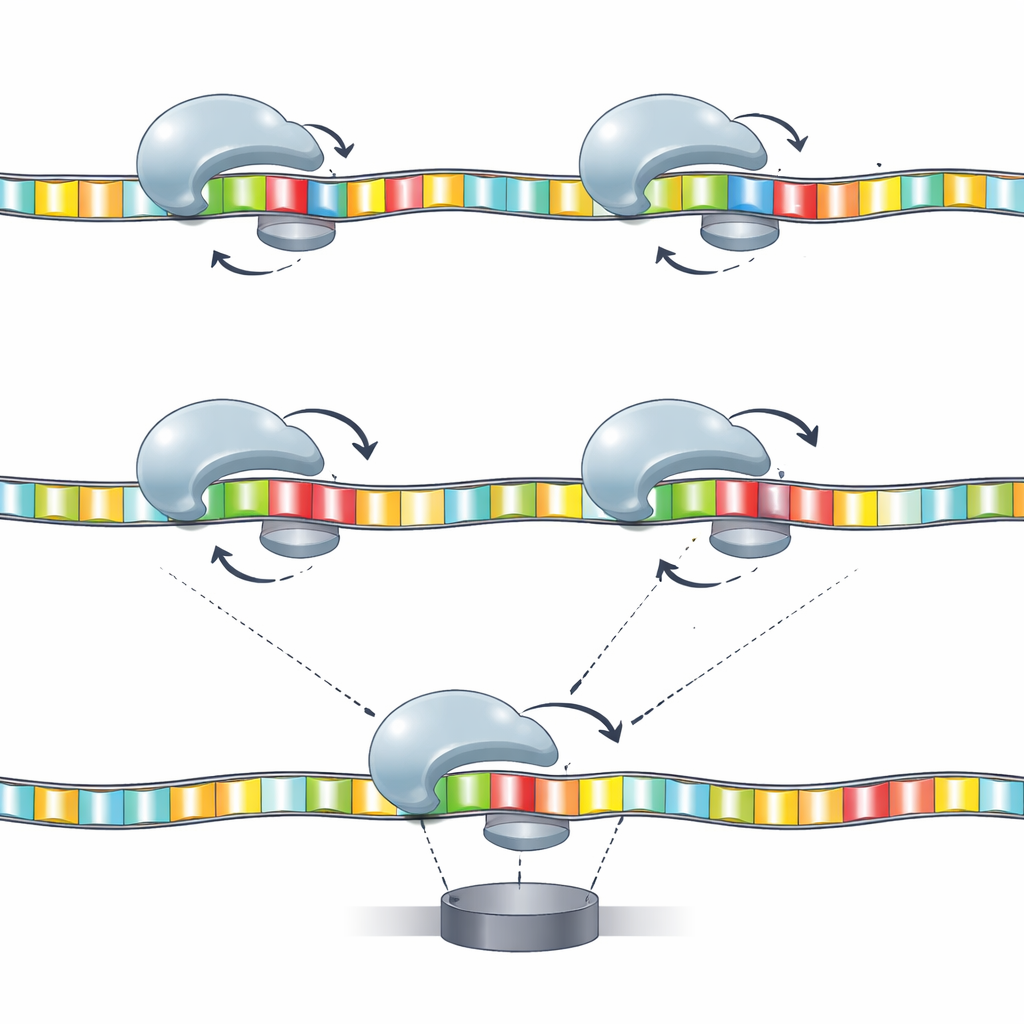
Kaarten bouwen van beweging naar sequentie
Sequencingapparaten vertrouwen vaak op "k‑mer"-modellen, die een kleine groep van k aangrenzende basen koppelen aan een karakteristiek signaal. Hier passen de auteurs dat idee toe op de beweging van de helicase. Ze construeren modellen waarin specifieke paren of triplets van basen op sleutelposities gezamenlijk het patroon van verblijftijden en achteruitstappen bepalen. Informatietheorie toont aan dat bepaalde combinaties — zoals basen op posities 17 en 20, of trimers inclusief posities 16, 17 en 20 — veel meer informatie dragen dan een enkele base alleen. Met andere woorden, het enzym voelt niet slechts één base tegelijk; het reageert op kleine sequentiemotieven verspreid over de streng, en die reacties zijn systematisch in kaart te brengen.
Gesimuleerde sequencing laat grote winst zien
Om te testen hoe nuttig deze extra op beweging gebaseerde informatie in de praktijk kan zijn, simuleerde het team nanopore-sequencingruns met realistische modellen van zowel stroom als kinetiek. Ze gebruikten vervolgens een decodeeralgoritme om DNA-sequenties te reconstrueren uit drie soorten input: alleen stroom, alleen kinetiek, of beide gecombineerd. Ionenstroom alleen presteert al goed, terwijl kinetiek alleen minder nauwkeurig is. Maar wanneer beide gecombineerd worden, dalen de foutpercentages sterk — ruwweg vier- tot vijfvoudig bij hoge dekking vergeleken met alleen stroom. Opvallend is dat een bescheiden aantal reads die beide signalen gebruiken, beter kan presteren dan veel meer reads die alleen stroom gebruiken, wat wijst op snellere en nauwkeurigere sequencing als kinetische data volledig worden benut.
De moleculaire motor zelf afstemmen
De onderzoekers onderzoeken ook hoe het veranderen van de helicase de prestaties verder kan verbeteren. Geleid door structurele data muteerden ze individuele aminozuren in Hel308 die contact maken met het DNA en onderzochten hoe deze veranderingen verblijftijden en achteruitstappen beïnvloedden. De meeste mutaties hadden weinig effect, maar een paar veroorzaakten grote, systematische verschuivingen in hoe lang het enzym bleef hangen en hoe vaak het achteruit stapte, terwijl de sequentiegevoeligheid behouden bleef. Twee posities in het eiwit weerspiegelden daarbij specifiek de sleutelposities in de sequentie die door de informatieanalyse werden benadrukt, wat wijst op een directe koppeling tussen bepaalde aminozuren en het sequentie‑sensorische gedrag van het enzym. De studie toont ook aan dat er een afweging bestaat: een mutant die per stap iets meer informatie draagt, beweegt langzamer, zodat de totale informatie per seconde vergelijkbaar is met die van het oorspronkelijke enzym.
Waarom dit belangrijk is voor toekomstig DNA‑lezen
Voor de niet‑specialist is de kernboodschap dat nanopore‑sequencers meer kunnen dan alleen elektrische patronen van DNA lezen; ze kunnen ook afluisteren hoe de moleculaire motor zich gedraagt terwijl hij over de streng loopt. Dit werk biedt een rigoureuze manier om te meten hoeveel extra sequentie-informatie in die beweging zit en laat zien dat het meenemen ervan de nauwkeurigheid sterk kan verbeteren, vooral in lastige regio’s zoals herhalingen of bij uitgebreide genetische alfabetten. Door informatietheorie als ontwerptool en screeningsmiddel te gebruiken, kunnen wetenschappers motorenzymen systematisch ontwerpen waarvan de pauzes en haperingen DNA-sequenties beter leesbaar maken, wat de weg vrijmaakt voor snellere, betrouwbaardere en veelzijdigere sequencingtechnologieën.
Bronvermelding: Craig, J.M., Laszlo, A.H., Brinkerhoff, H. et al. An information theory approach to quantifying the sequence-dependent response of nucleic acid motors with applications to nanopore DNA sequencing. Nat Commun 17, 3231 (2026). https://doi.org/10.1038/s41467-026-69867-2
Trefwoorden: nanopore-sequencing, helicase-kinetiek, informatietheorie, DNA-motorenzymen, k-mer-modellen