Clear Sky Science · es
Un enfoque de teoría de la información para cuantificar la respuesta dependiente de la secuencia de motores de ácidos nucleicos con aplicaciones al secuenciado de ADN por nanoporo
Leer el ADN con máquinas diminutas
Cada célula de tu cuerpo depende de máquinas microscópicas que se desplazan a lo largo del ADN, copiándolo y reparándolo. Ese mismo tipo de máquinas ahora impulsan dispositivos de secuenciación de ADN rápidos. Este estudio plantea una pregunta aparentemente simple con grandes implicaciones: más allá de las señales eléctricas habituales usadas en la secuenciación por nanoporo, ¿cuánta información adicional sobre la secuencia de ADN está oculta en la forma en que se mueven estas diminutas máquinas—cuánto tiempo hacen una pausa y con qué frecuencia retroceden? Empleando herramientas de la teoría de la información, los autores muestran que estos movimientos sutiles pueden aumentar sustancialmente la precisión de la lectura del ADN y describen cómo diseñar mejores motores moleculares para tecnologías de secuenciación futuras.
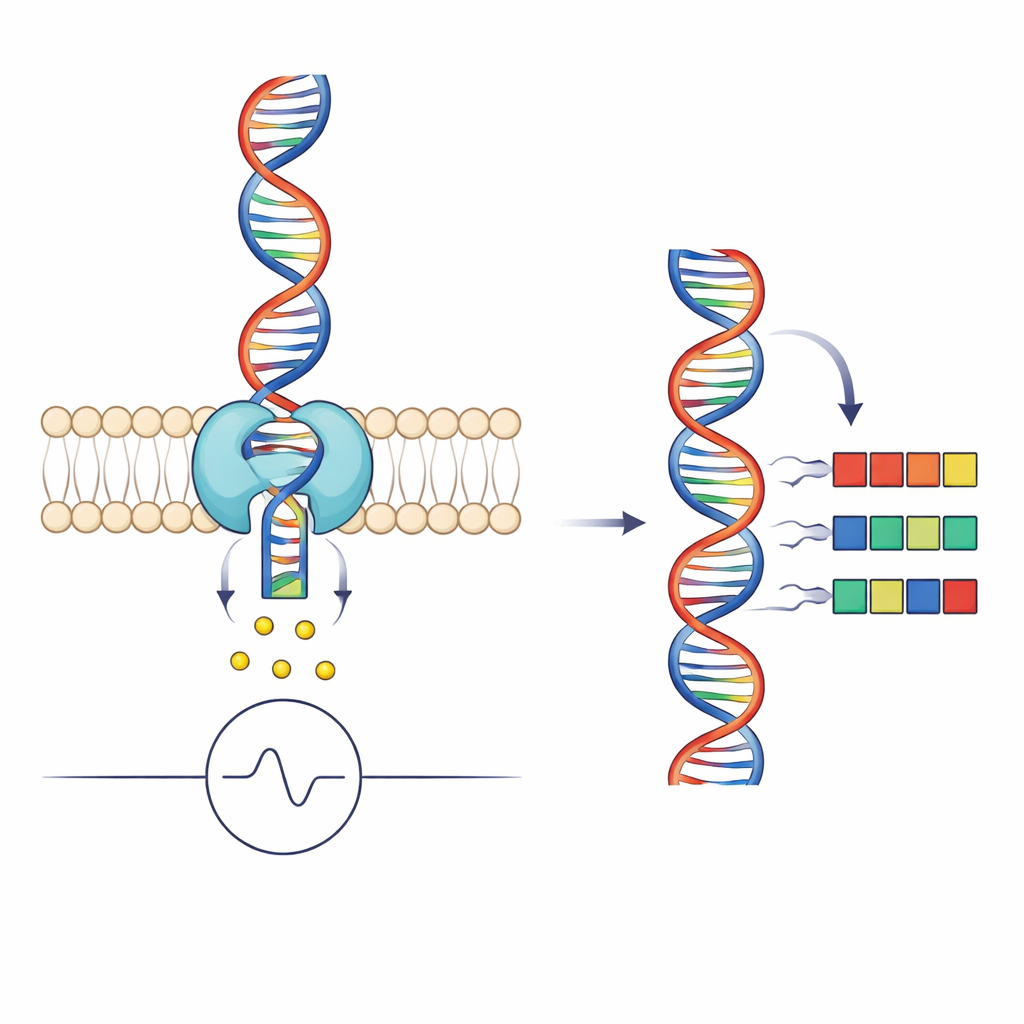
Cómo los nanoporos convierten el ADN en señales
La secuenciación por nanoporo funciona haciendo pasar una sola hebra de ADN por un agujero diminuto en una membrana mientras se mide el flujo de iones a través del poro. A medida que distintos grupos de bases del ADN ocupan la parte más estrecha del poro, bloquean parcialmente la corriente de maneras características, produciendo un patrón eléctrico que puede decodificarse en una secuencia. Una enzima motor, en este caso una helicasa llamada Hel308, sujeta el ADN y lo alimenta por el poro en pasos pequeños. Cada «lectura» de secuenciación es por tanto no solo una traza de corriente, sino también un registro detallado de cómo se mueve la helicasa: cuánto tiempo espera en cada posición y si ocasionalmente resbala hacia atrás.
Usar la teoría de la información para medir pistas ocultas
Los autores emplean un concepto llamado información mutua para cuantificar hasta qué punto la secuencia de ADN controla diferentes observables: la corriente iónica, el tiempo que Hel308 pasa en cada paso y su probabilidad de retroceder. La información mutua, medida en bits, responde: en promedio, ¿cuánto podemos aprender sobre una base de ADN a partir de una señal dada? Al analizar miles de mediciones, encuentran que la corriente iónica es más sensible a un tramo corto de aproximadamente cuatro bases ubicado en la constricción del poro, mientras que el movimiento de Hel308 está gobernado principalmente por bases situadas a 16–21 posiciones de distancia. En particular, las bases en dos posiciones (aproximadamente 17 y 20 nucleótidos desde el poro) influyen fuertemente en cuánto dura la permanencia de la enzima y en la probabilidad de retroceso. Combinar el tiempo de permanencia y el comportamiento de retroceso revela más sobre estas bases que cualquiera de las características por separado.
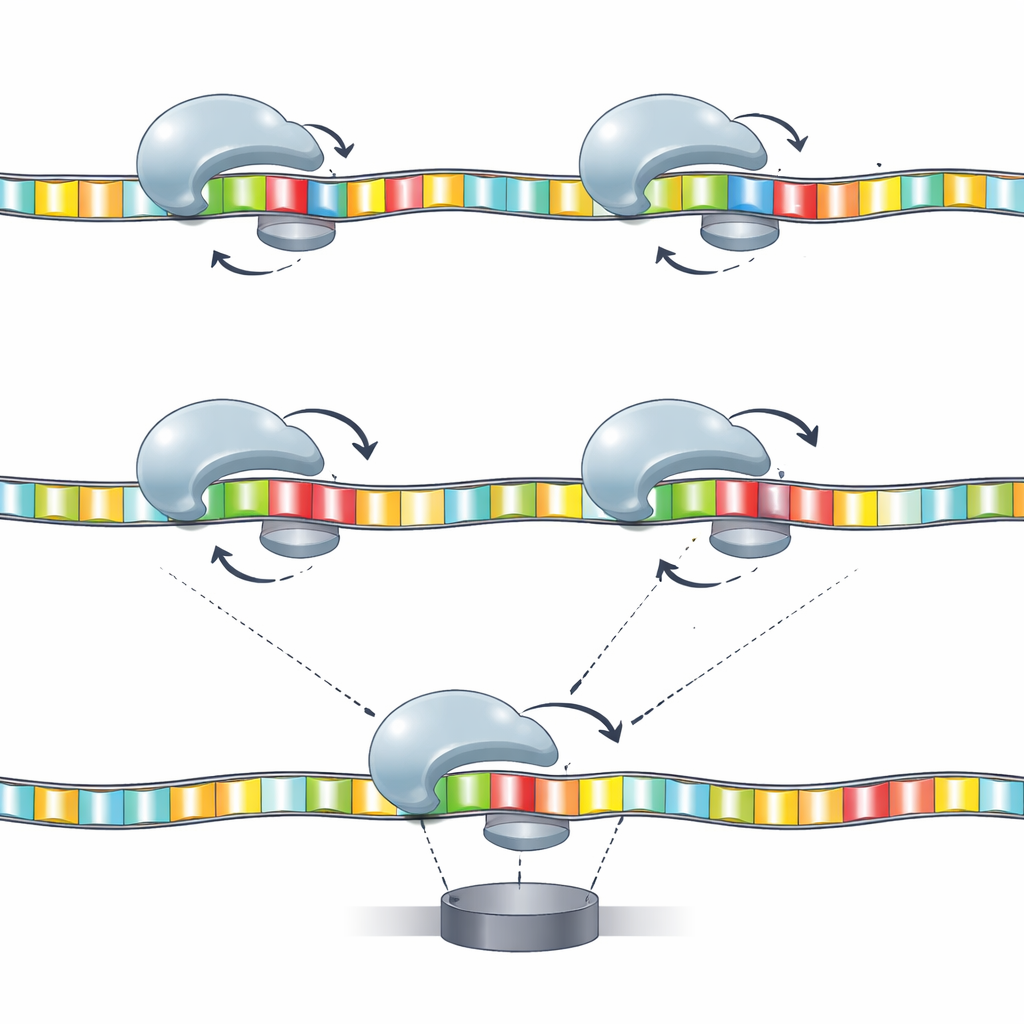
Construir mapas del movimiento a la secuencia
Los dispositivos de secuenciación a menudo se basan en modelos de «k-mer», que vinculan un pequeño grupo de k bases vecinas con una señal característica. Aquí, los autores adaptan esa idea al movimiento de la helicasa. Construyen modelos en los que pares o tríos específicos de bases en posiciones clave determinan conjuntamente el patrón de tiempos de permanencia y retrocesos. La teoría de la información muestra que ciertas combinaciones—como las bases en las posiciones 17 y 20, o trimers que incluyen las posiciones 16, 17 y 20—aportan mucha más información que cualquier base individual. En otras palabras, la enzima no «siente» sólo una base a la vez; responde a pequeños motivos de secuencia distribuidos a lo largo de la hebra, y esas respuestas se pueden mapear sistemáticamente.
Secuenciación simulada muestra una gran ganancia
Para probar cuán útil podría ser en la práctica esta información basada en el movimiento, el equipo simuló corridas de secuenciación por nanoporo usando modelos realistas tanto de la corriente como de la cinética. Luego emplearon un algoritmo de decodificación para reconstruir secuencias de ADN a partir de tres tipos de entrada: solo corriente, solo cinética o ambas combinadas. La corriente iónica por sí sola ya rinde bien, mientras que la cinética sola es menos precisa. Pero cuando se combinan ambas, las tasas de error caen bruscamente—aproximadamente entre cuatro y cinco veces menos en coberturas altas en comparación con usar únicamente la corriente. Notablemente, un número modesto de lecturas que emplean ambas señales puede superar a muchas más lecturas que usan solo la corriente, lo que sugiere secuenciación más rápida y más precisa si se aprovechan completamente los datos cinéticos.
Ajustar el propio motor molecular
Los investigadores también exploran cómo cambiar la helicasa podría aumentar aún más el rendimiento. Guiados por datos estructurales, mutaron aminoácidos individuales en Hel308 que contactan el ADN y examinaron cómo esos cambios afectaban los tiempos de permanencia y los retrocesos. La mayoría de las mutaciones tuvo poco efecto, pero algunas produjeron cambios grandes y sistemáticos en cuánto tiempo permanecía la enzima y en la frecuencia de retrocesos, manteniendo a la vez su sensibilidad a la secuencia. Dos posiciones en la proteína, en particular, reflejaron las posiciones de secuencia clave destacadas por el análisis de información, lo que sugiere un vínculo directo entre aminoácidos específicos y el comportamiento de detección de secuencia de la enzima. El estudio también muestra que existe una compensación: un mutante que aporta ligeramente más información por paso se mueve más despacio, por lo que su información total por segundo es similar a la de la enzima original.
Por qué esto importa para la lectura futura del ADN
Para un público no especializado, la conclusión es que los secuenciadores por nanoporo pueden hacer más que leer patrones eléctricos del ADN; también pueden «escuchar» cómo se comporta el motor molecular mientras camina a lo largo de la hebra. Este trabajo ofrece una forma rigurosa de medir cuánta información adicional de la secuencia transporta ese movimiento y demuestra que incluirla podría mejorar mucho la precisión, especialmente en regiones difíciles como repeticiones o en alfabetos genéticos ampliados. Al usar la teoría de la información como herramienta de diseño y cribado, los científicos pueden diseñar sistemáticamente enzimas motoras cuyas pausas y titubeos hagan que las secuencias de ADN sean más fáciles de leer, abriendo la puerta a tecnologías de secuenciación más rápidas, fiables y versátiles.
Cita: Craig, J.M., Laszlo, A.H., Brinkerhoff, H. et al. An information theory approach to quantifying the sequence-dependent response of nucleic acid motors with applications to nanopore DNA sequencing. Nat Commun 17, 3231 (2026). https://doi.org/10.1038/s41467-026-69867-2
Palabras clave: secuenciación por nanoporo, cinética de helicasas, teoría de la información, enzimas motoras de ADN, modelos k-mer