Clear Sky Science · en
An information theory approach to quantifying the sequence-dependent response of nucleic acid motors with applications to nanopore DNA sequencing
Reading DNA with Tiny Machines
Every cell in your body relies on microscopic machines that crawl along DNA, copying and repairing it. The same kinds of machines now power fast DNA sequencing devices. This study asks a deceptively simple question with big implications: beyond the usual electrical signals used in nanopore sequencing, how much extra information about the DNA sequence is hidden in the way these tiny machines move—how long they pause and how often they step backward? Using tools from information theory, the authors show that these subtle motions can substantially boost the accuracy of reading DNA, and they outline how to engineer better molecular motors for future sequencing technologies.
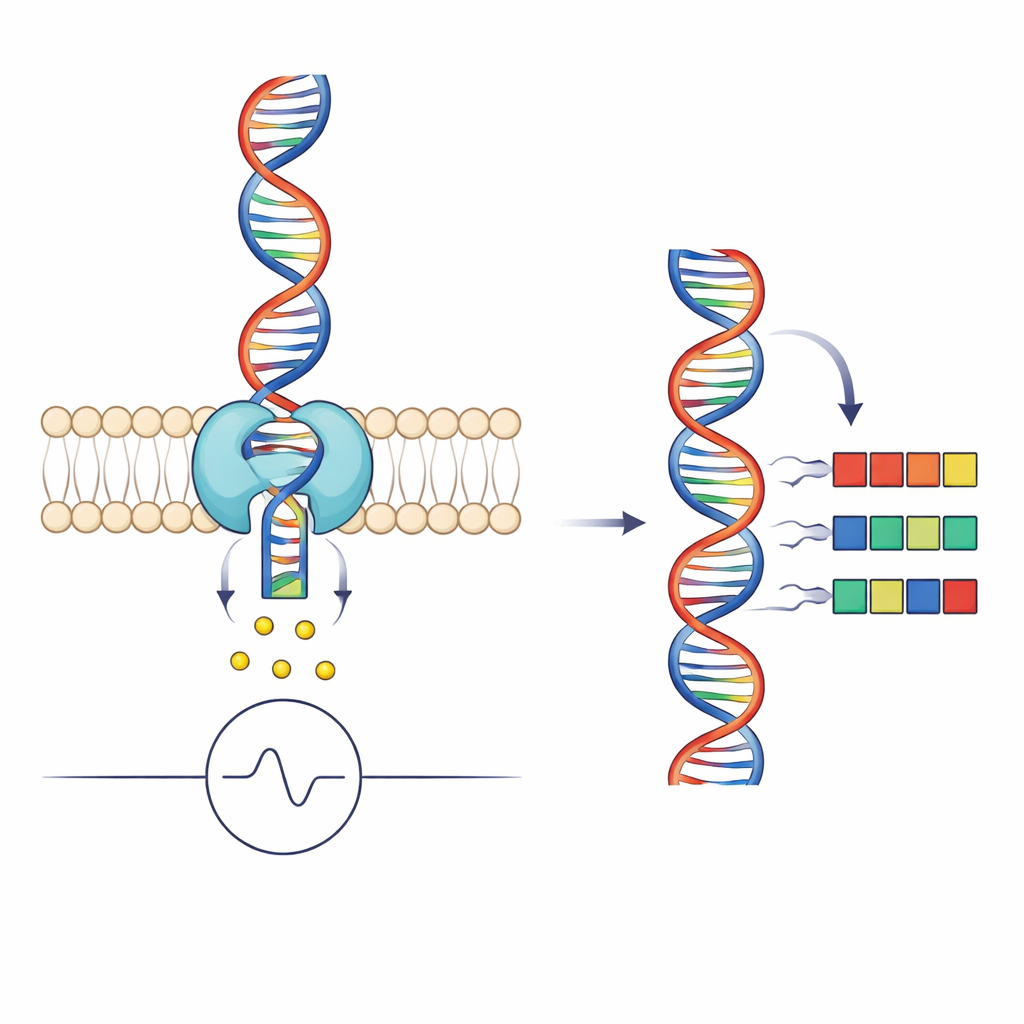
How Nanopores Turn DNA into Signals
Nanopore sequencing works by threading a single DNA strand through a tiny hole in a membrane while measuring the flow of ions through the pore. As different groups of DNA bases occupy the narrowest part of the pore, they partially block the current in distinct ways, producing a characteristic electrical pattern that can be decoded into a sequence. A motor enzyme, here a helicase called Hel308, grips the DNA and feeds it through the pore in small steps. Each sequencing "read" is therefore not just a current trace but also a detailed record of how the helicase moves: how long it waits at each position and whether it occasionally slips backward.
Using Information Theory to Measure Hidden Clues
The authors use a concept called mutual information to quantify how strongly the DNA sequence controls different observables: the ion current, the time Hel308 spends at each step, and its probability of stepping backward. Mutual information, measured in bits, answers: on average, how much can we learn about a DNA base from a given signal? By analyzing thousands of measurements, they find that ion current is most sensitive to a short stretch of about four bases located in the pore constriction, while Hel308’s motion is governed mainly by bases located 16–21 positions away. In particular, bases at two positions (roughly 17 and 20 nucleotides from the pore) strongly influence how long the enzyme dwells and how likely it is to backstep. Combining dwell time and backstep behavior reveals more about these bases than either feature alone.
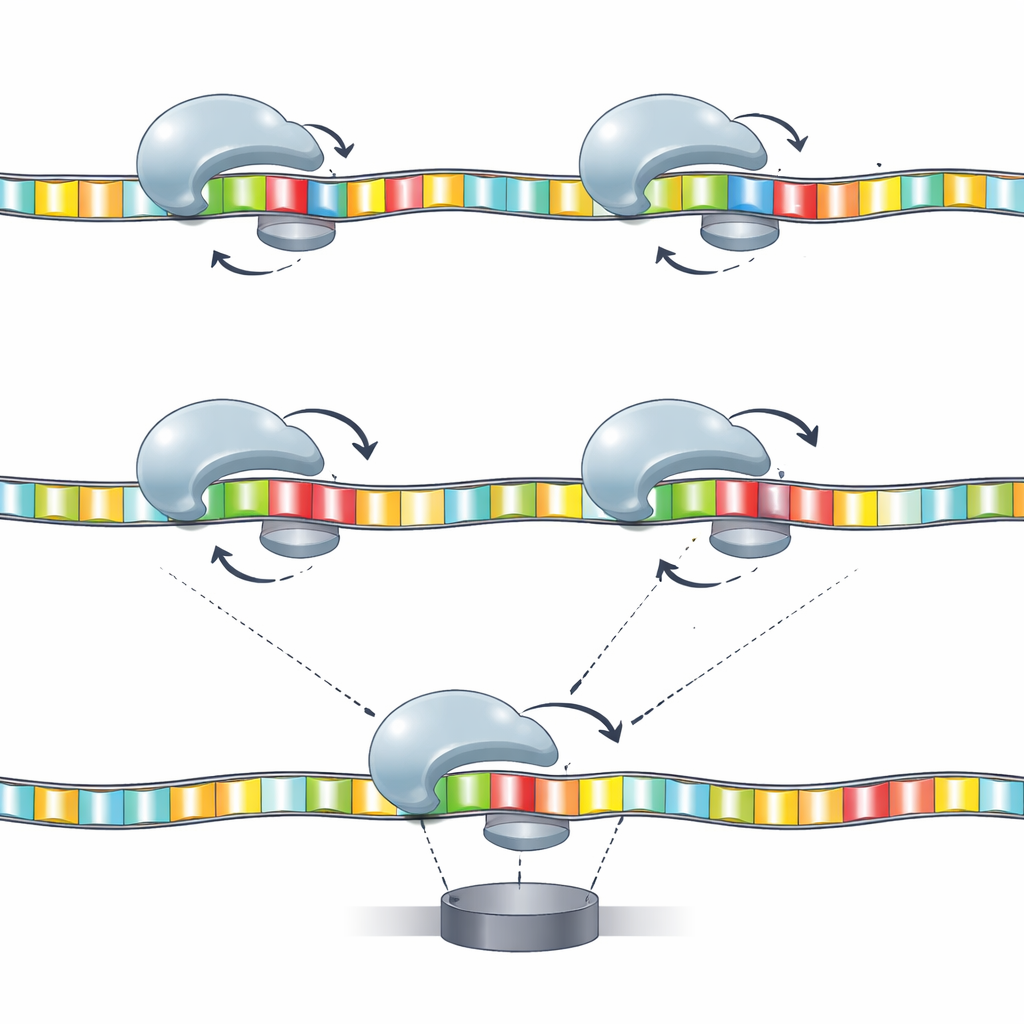
Building Maps from Motion to Sequence
Sequencing devices often rely on "k-mer" models, which link a small group of k neighboring bases to a characteristic signal. Here, the authors adapt that idea to the helicase’s motion. They construct models in which specific pairs or triplets of bases at key positions jointly determine the pattern of dwell times and backsteps. Information theory shows that certain combinations—such as bases at positions 17 and 20, or trimers including positions 16, 17, and 20—carry much more information than any single base alone. In other words, the enzyme does not just "feel" one base at a time; it responds to small sequence motifs spread out along the strand, and those responses can be systematically mapped.
Simulated Sequencing Shows a Big Payoff
To test how useful this extra motion-based information could be in practice, the team simulated nanopore sequencing runs using realistic models of both current and kinetics. They then used a decoding algorithm to reconstruct DNA sequences from three types of input: current only, kinetics only, or both together. Ion current alone already performs well, while kinetics alone is less accurate. But when both are combined, error rates drop sharply—by roughly four- to five-fold at high coverage compared with using current alone. Notably, a modest number of reads that use both signals can outperform many more reads that use current only, suggesting faster and more accurate sequencing if kinetic data are fully exploited.
Tuning the Molecular Motor Itself
The researchers also explore how changing the helicase might further boost performance. Guided by structural data, they mutated individual amino acids in Hel308 that contact the DNA and examined how these changes affected dwell times and backsteps. Most mutations had little effect, but a few caused large, systematic shifts in how long the enzyme lingered and how often it stepped backward, while preserving its sensitivity to sequence. Two positions in the protein, in particular, mirrored the key sequence positions highlighted by the information analysis, suggesting a direct link between specific amino acids and the enzyme’s sequence-sensing behavior. The study also shows that there is a trade-off: a mutant that carries slightly more information per step moves more slowly, so its total information per second is similar to the original enzyme.
Why This Matters for Future DNA Reading
For a non-specialist, the bottom line is that nanopore sequencers can do more than just read electrical patterns from DNA; they can also listen to how the molecular motor behaves as it walks along the strand. This work provides a rigorous way to measure how much extra sequence information is carried in that motion and shows that including it could greatly improve accuracy, especially in tough regions like repeats or in expanded genetic alphabets. By using information theory as a design and screening tool, scientists can systematically engineer motor enzymes whose pauses and stutters make DNA sequences easier to read, opening the door to faster, more reliable, and more versatile sequencing technologies.
Citation: Craig, J.M., Laszlo, A.H., Brinkerhoff, H. et al. An information theory approach to quantifying the sequence-dependent response of nucleic acid motors with applications to nanopore DNA sequencing. Nat Commun 17, 3231 (2026). https://doi.org/10.1038/s41467-026-69867-2
Keywords: nanopore sequencing, helicase kinetics, information theory, DNA motor enzymes, k-mer models