Clear Sky Science · nl
Optimalisatie van testgevalsampling voor veiligheidsvalidatie van geautomatiseerde rijsystemen
Waarom veiligere robotbestuurders voor iedereen belangrijk zijn
Zelfrijdende auto's beloven minder ongevallen, vloeiendere woon-werkverkeer en nieuwe mobiliteit voor mensen die nu niet kunnen autorijden. Maar voordat het publiek deze systemen vertrouwt, hebben we overtuigend bewijs nodig dat ze ten minste zo veilig zijn als menselijke bestuurders. Dat bewijs hangt af van hoe we ze testen: in welke situaties we ze plaatsen en hoe we beoordelen of ze slagen of falen. Dit artikel pakt een centraal probleem in dat proces aan — hoe kies je een kleine maar effectieve set rij situaties die de rommelige, onvoorspelbare echte wereld trouw weerspiegelt, inclusief de zeldzame maar gevaarlijke momenten waarop ongevallen plaatsvinden.
Van eindeloze wegen naar een slimme testlijst
Op echte wegen verlopen bijna alle ritten zonder incidenten. Ernstige ongevallen zijn zeldzaam, maar juist dat is wat voor de veiligheid telt. Als toezichthouders geautomatiseerde auto's zouden testen door simpelweg miljarden mijlen te rijden en af te wachten wat er gebeurt, zou validatie jaren duren en enorm veel kosten met zich meebrengen. Ingenieurs bouwen in plaats daarvan bibliotheken met testgevallen: korte rijsequenties die opnieuw kunnen worden afgespeeld op testbanen of in simulators. Het knelpunt is te beslissen welke gevallen moeten worden opgenomen. Traditionele benaderingen leunen op een paar vertrouwde patronen, zoals eenvoudig volgen van een voertuig of constant remmen, of op computermodellen die andere bestuurders slechts ruw nabootsen. Daardoor kunnen veel subtiele of ongewone situaties die echte ongevallen veroorzaken over het hoofd worden gezien, en kunnen de uiteindelijke veiligheidscijfers vertekenen.
De echte verkeerssituaties uitmijnen voor veelzeggende momenten
De auteurs baseren hun werk op de grootste naturalistische rijstudie in de Verenigde Staten, een project dat duizenden auto's uitrustte met camera's, radar en bewegingssensoren en tientallen miljoenen mijlen gewone ritten en ongevallen registreerde. Uit deze schat bouwen ze een pool van ongeveer 56.000 normale 15-seconden ritten en 90 echte ongevalsequenties, elk beschreven door 48 metingen die vastleggen hoe de auto bewoog, hoe nabijgelegen voertuigen zich gedroegen en hoe druk de omgeving was. Een testgeval kan bijvoorbeeld een auto op snelweg snelheid tonen terwijl een ander voertuig plotseling voordringt, of een rustig segment op een hobbelige weg zonder nabije buren. Deze pool dient als een statistisch getrouwe miniatuur van wat er daadwerkelijk op Amerikaanse wegen gebeurt.
Het vinden van een balans tussen veelvoorkomende scènes en zeldzame gevaren
Om deze enorme pool om te zetten in een praktische testlijst introduceren de onderzoekers Kernel Test Case Sampling (KTCS). Hun methode is gebouwd rond twee helder geformuleerde doelen. Ten eerste representativiteit: samen moeten de gekozen gevallen lijken op het volledige palet van alledaags rijden, zodat het aandeel rustige versus stressvolle momenten overeenkomt met wat mensen werkelijk ervaren. Ten tweede dekking: de lijst moet ook genoeg ongewone, hoogrisico situaties bevatten — de lange staart van zeldzame maar onthullende gebeurtenissen waarin geautomatiseerde systemen het meest waarschijnlijk fouten maken. Wiskundig gebruikt KTCS technieken uit moderne statistiek en machine learning om de featurespace te doorzoeken op een kleine groep gevallen die zowel uitspreidt om extreme condities te dekken als, met zorgvuldig afgestemde gewichten, de algemene verdeling van echt rijden nabootst.
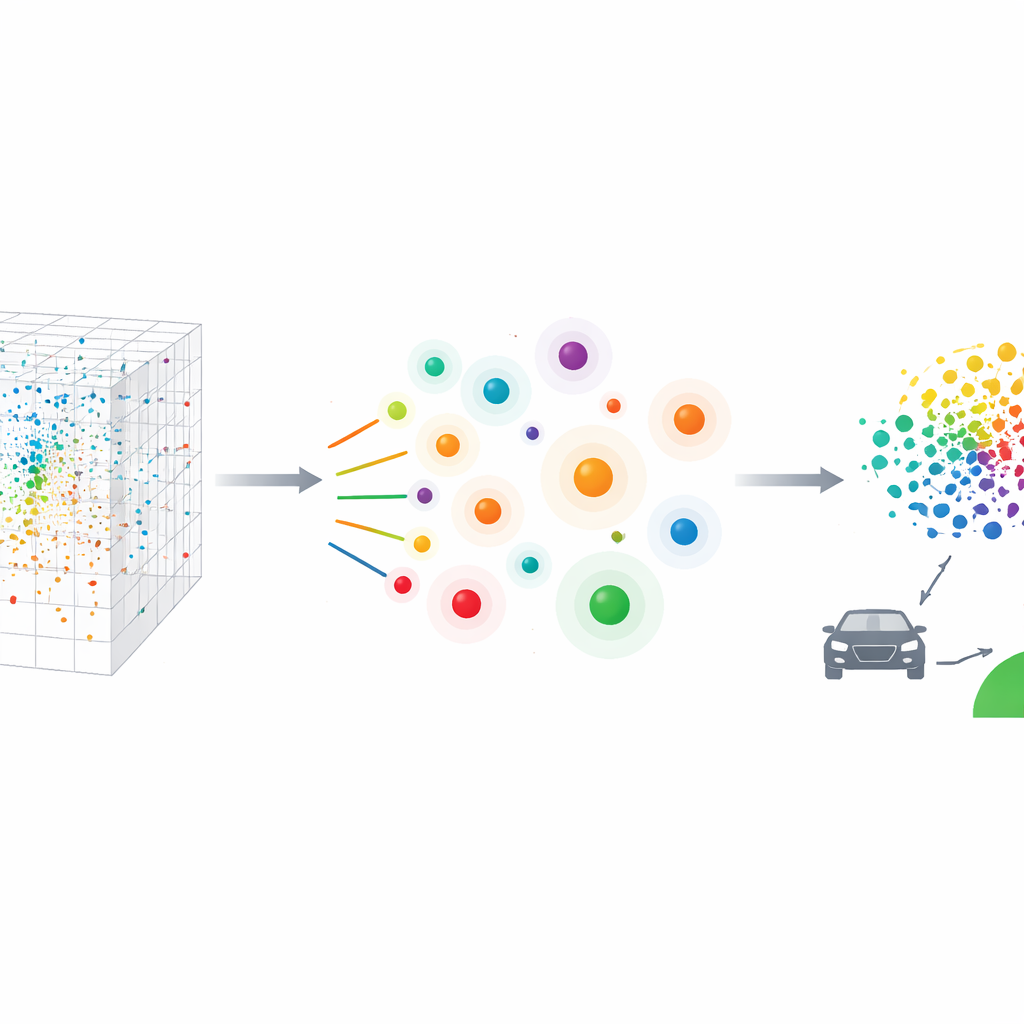
Hoe de nieuwe methode wordt getest
De onderzoekers vergelijken KTCS met verschillende toonaangevende samplingstrategieën die ofwel gevallen gelijkmatig verspreiden, zich richten op dichte regio's, of zich op zeldzame uitbijters richten. Alle methoden moeten slechts 118 gevallen uit de grote pool kiezen. Visuele plots en numerieke scores laten zien dat KTCS het beste de vorm van de oorspronkelijke data vastlegt: het komt nauwkeurig overeen met echt rijgedrag voor elk van de 48 gemeten kenmerken, terwijl het toch veel ver van typisch gelegen gevallen selecteert waar condities extremer zijn. Concurrerende methoden concentreren zich ofwel te sterk op de veiligste, meest voorkomende scènes of jagen bijna uitsluitend op extremen, waardoor ze de verbinding met de dagelijkse realiteit verliezen. KTCS levert daarentegen een compacte set die statistisch lijkt op de volledige verkeerswereld en toch de meest veiligheidkritische scenario's bevat.
Testresultaten omzetten in een duidelijke veiligheidscore
Nadat ze deze verfijnde testset hebben samengesteld, laten de auteurs zien hoe deze kan worden gebruikt om een geautomatiseerd rij systeem te beoordelen. Elk geval wordt eenmaal uitgevoerd in simulatie of op een testbaan; een "pass" betekent geen crash en een "fail" betekent een crash. Omdat elk geval een geassocieerd gewicht en een impliciete gereden afstand heeft, combineert het team het pass–fail patroon tot een geschatte crashfrequentie voor het systeem, uitgedrukt per meter gereden. Ze vergelijken deze frequentie vervolgens met de crashfrequentie van menselijke bestuurders gemeten in dezelfde nationale studie, en definiëren een grootheid genaamd "Scaling Risk" — hoe veel keer risicovoller of veiliger het geautomatiseerde systeem is dan mensen. Cruciaal is dat het falen van een veelvoorkomend, zwaar gewogen scenario veel zwaarder tegen het systeem telt dan het falen van een zeldzaam edge-case, wat weerspiegelt hoe vaak mensen daadwerkelijk met elk situatie in het verkeer worden geconfronteerd.
Wat dit betekent voor toekomstige zelfrijdende auto's
De belangrijkste boodschap van de studie is dat we brute-force kilometers kunnen vervangen door een zorgvuldig gekozen set realistische scenario's en toch de veiligheid eerlijk kunnen schatten. KTCS biedt een principiële manier om die set samen te stellen zodat ze zowel routinematige als risicovolle situaties dekt, en om de resultaten om te zetten in een duidelijke "hoe veilig is het vergeleken met mensen"-score. Dit soort gestandaardiseerde, statistisch onderbouwde testen kan toezichthouders, bedrijven en het publiek helpen het vertrouwen te vergroten dat geautomatiseerde rij systemen beoordeeld worden op realistisch en omvattend bewijs in plaats van op zorgvuldig geselecteerde demo's of te vereenvoudigde labtests.
Bronvermelding: Qian, C., Xu, J., Xing, X. et al. Test case sampling optimization for safety validation of automated driving systems. Nat Commun 17, 3114 (2026). https://doi.org/10.1038/s41467-026-69675-8
Trefwoorden: veiligheid van geautomatiseerd rijden, sampling van testgevallen, naturalistische rijgegevens, edge-case scenario's, validatie van zelfrijdende auto's