Clear Sky Science · de
Optimierung der Testfall-Stichprobe zur Sicherheitsvalidierung automatisierter Fahrsysteme
Warum sicherere Roboterfahrer uns alle betreffen
Selbstfahrende Autos versprechen weniger Unfälle, ruhigere Pendelstrecken und neue Mobilität für Menschen, die heute nicht fahren können. Bevor die Öffentlichkeit diesen Systemen jedoch vertraut, brauchen wir verlässliche Belege, dass sie mindestens so sicher sind wie menschliche Fahrer. Dieser Nachweis hängt davon ab, wie wir sie testen: in welche Situationen wir sie bringen und wie wir beurteilen, ob sie bestehen oder versagen. Dieses Papier behandelt ein zentrales Problem dieses Prozesses — wie wählt man eine kleine, aber wirksame Menge an Fahrsituationen aus, die die unordentliche, unvorhersehbare reale Welt wirklich widerspiegelt, einschließlich der seltenen, aber gefährlichen Momente, in denen Unfälle passieren.
Von endlosen Straßen zu einer smarten Testliste
Auf echten Straßen verlaufen fast alle Fahrten ereignislos. Schwere Unfälle sind selten, aber genau diese Ereignisse sind für die Sicherheit entscheidend. Würden Regulierer versuchen, automatisierte Fahrzeuge einfach durch Milliarden von gefahrenen Meilen zu testen und abzuwarten, würden Validierungen viele Jahre und enorme Kosten erfordern. Stattdessen erstellen Ingenieure Bibliotheken von Testfällen: kurze Fahrsequenzen, die auf Teststrecken oder in Simulatoren abgespielt werden können. Die Schwierigkeit besteht darin, zu entscheiden, welche Fälle aufgenommen werden. Traditionelle Ansätze stützen sich auf einige vertraute Muster, wie einfaches Auffahren oder stetiges Bremsen, oder auf Computermodelle, die andere Verkehrsteilnehmer nur grob nachahmen. Infolgedessen können viele subtile oder ungewöhnliche Situationen, die echte Unfälle verursachen, übersehen werden, und die endgültigen Sicherheitszahlen können verzerrt sein.
Wahre Verkehrsmomente ausgraben
Die Autorinnen und Autoren stützen ihre Arbeit auf die größte naturalistische Fahrstudie in den Vereinigten Staaten, ein Projekt, das Tausende von Autos mit Kameras, Radar und Bewegungssensoren ausstattete und zig Millionen Meilen normalen Fahrens sowie Unfälle aufzeichnete. Aus diesem Fundus bauen sie einen Pool von etwa 56.000 normalen 15‑Sekunden‑Fahrten und 90 echten Unfallsequenzen auf, die jeweils durch 48 Messgrößen beschrieben werden, die erfassen, wie sich das Fahrzeug bewegte, wie sich benachbarte Fahrzeuge verhielten und wie dicht die Umgebung war. Ein Testfall könnte zum Beispiel ein Fahrzeug bei Autobahngeschwindigkeit zeigen, während ein anderes plötzlich einschert, oder ein ruhiges Segment auf einer holprigen Straße ohne nahe Nachbarn. Dieser Pool dient als statistisch getreues Miniaturmodell dessen, was tatsächlich auf US‑Straßen geschieht.
Ausbalancieren häufiger Szenen und seltener Gefahren
Um diesen großen Pool in eine praktische Testliste zu überführen, führt das Team die Kernel Test Case Sampling (KTCS) ein. Ihre Methode basiert auf zwei leicht verständlichen Zielen. Erstens, Repräsentativität: Zusammen sollten die gewählten Fälle die gesamte Mischung des Alltagsverkehrs widerspiegeln, sodass der Anteil ruhiger gegenüber stressigen Momenten dem entspricht, was Menschen wirklich erleben. Zweitens, Abdeckung: Die Liste muss auch genügend ungewöhnliche, risikoreiche Situationen enthalten — die lange Schwanzverteilung seltener, aber aufschlussreicher Ereignisse, in denen automatisierte Systeme am ehesten versagen. Mathematisch nutzt KTCS Werkzeuge aus moderner Statistik und maschinellem Lernen, um den Merkmalsraum nach einer kleinen Gruppe von Fällen zu durchsuchen, die sich sowohl über extreme Bedingungen hinweg ausdehnen als auch, bei sorgfältig abgestimmten Gewichten, die Gesamtdistribution des realen Fahrens nachahmen.
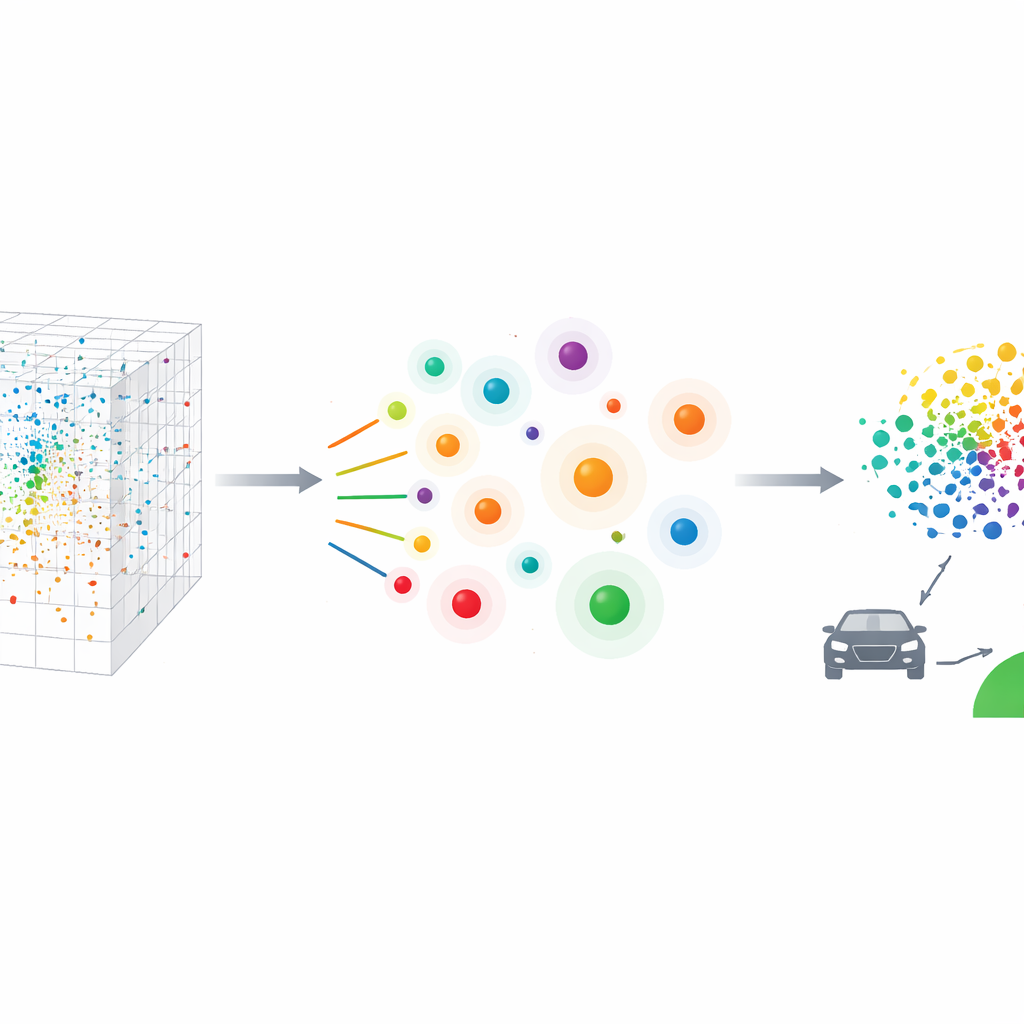
Wie die neue Methode getestet wird
Die Forschenden vergleichen KTCS mit mehreren führenden Stichprobenstrategien, die Fälle entweder gleichmäßig verteilen, sich auf dichte Regionen konzentrieren oder seltene Ausreißer anvisieren. Alle Methoden sollen nur 118 Fälle aus dem großen Pool auswählen. Visuelle Darstellungen und numerische Kennzahlen zeigen, dass KTCS die Form der Originaldaten am besten einfängt: Es stimmt für jede der 48 gemessenen Eigenschaften eng mit dem realen Fahren überein und wählt gleichzeitig viele weit von der Norm entfernt liegende Fälle aus, in denen die Bedingungen extremer sind. Konkurrenzmethoden konzentrieren sich entweder zu stark auf die sichersten, häufigsten Szenen oder jagen fast ausschließlich Extremen nach und verlieren den Bezug zur Alltagsrealität. KTCS liefert hingegen eine kompakte Menge, die statistisch der gesamten Verkehrswelt ähnelt und dennoch die sicherheitskritischsten Szenarien einschließt.
Testresultate in eine klare Sicherheitskennzahl übersetzen
Nachdem dieses verfeinerte Testsatz zusammengestellt ist, zeigen die Autorinnen und Autoren, wie man ihn zur Bewertung eines automatisierten Fahrsystems verwendet. Jeder Fall wird einmal in der Simulation oder auf der Teststrecke gefahren; ein „Bestanden“ bedeutet keinen Unfall, ein „Nicht bestanden“ einen Unfall. Da jeder Fall ein zugehöriges Gewicht und eine implizite gefahrene Distanz hat, kombiniert das Team das Bestehen‑/Versagen‑Muster zu einer geschätzten Unfallrate für das System, ausgedrückt pro Meter Fahrstrecke. Diese Rate vergleichen sie dann mit der Unfallrate menschlicher Fahrer, gemessen in derselben nationalen Studie, und definieren eine Größe namens „Scaling Risk“ — wie viel riskanter oder sicherer das automatisierte System im Vergleich zu Menschen ist. Entscheidend ist, dass das Versagen in einem häufigen, stark gewichteten Szenario viel schwerer ins Gewicht fällt als das Versagen in einem seltenen Randfall, was widerspiegelt, wie oft Menschen tatsächlich mit jeder Situation auf der Straße konfrontiert werden.
Was das für zukünftige selbstfahrende Autos bedeutet
Die zentrale Botschaft der Studie ist, dass wir rohe Meilenleistung durch eine sorgfältig ausgewählte Menge realer Szenarien ersetzen und trotzdem Sicherheit fair schätzen können. KTCS bietet einen prinzipienbasierten Weg, dieses Set so zusammenzustellen, dass es sowohl routinemäßige als auch riskante Situationen abdeckt, und die Ergebnisse in eine klare „Wie sicher ist es im Vergleich zu Menschen“-Zahl zu überführen. Solch standardisierte, statistisch fundierte Tests könnten Regulierern, Unternehmen und der Öffentlichkeit helfen, Vertrauen darin zu gewinnen, dass automatisierte Fahrsysteme anhand realistischer, umfassender Belege bewertet werden und nicht anhand ausgewählter Demos oder vereinfachter Labortests.
Zitation: Qian, C., Xu, J., Xing, X. et al. Test case sampling optimization for safety validation of automated driving systems. Nat Commun 17, 3114 (2026). https://doi.org/10.1038/s41467-026-69675-8
Schlüsselwörter: Sicherheit automatisiertes Fahren, Stichproben von Testfällen, naturalistische Fahrdaten, Randfallszenarien, Validierung selbstfahrender Autos