Clear Sky Science · en
Test case sampling optimization for safety validation of automated driving systems
Why safer robot drivers matter to everyone
Self-driving cars promise fewer crashes, smoother commutes, and new mobility for people who cannot drive today. But before the public can trust these systems, we need solid proof that they are at least as safe as human drivers. That proof hinges on how we test them: which situations we put them in, and how we judge whether they pass or fail. This paper tackles a central problem in that process—how to choose a small but powerful set of driving situations that truly reflects the messy, unpredictable real world, including the rare but dangerous moments when crashes happen.
From endless roads to a smart test list
On real roads, almost all trips are uneventful. Serious crashes are rare, but they are exactly what matters for safety. If regulators tried to test automated cars simply by driving billions of miles and waiting to see what happens, validation would take many years and enormous cost. Instead, engineers build libraries of test cases: short driving sequences that can be replayed on tracks or in simulators. The catch is deciding which cases to include. Traditional approaches lean on a few familiar patterns, like simple car-following or steady braking, or on computer models that only roughly imitate other drivers. As a result, many subtle or unusual situations that cause real crashes can be missed, and the final safety numbers may be biased.
Mining real traffic for telling moments
The authors base their work on the largest naturalistic driving study in the United States, a project that instrumented thousands of cars with cameras, radar, and motion sensors and recorded tens of millions of miles of ordinary driving and crashes. From this trove they build a pool of about 56,000 normal 15‑second trips and 90 real crash sequences, each described by 48 measurements capturing how the car moved, how nearby vehicles behaved, and how crowded the surroundings were. A test case might, for example, show a car traveling at highway speed while another suddenly cuts in, or a quiet segment on a bumpy road with no close neighbors. This pool serves as a statistically faithful miniature of what actually happens on U.S. roads.
Balancing common scenes and rare dangers
To turn this huge pool into a practical test list, the team introduces Kernel Test Case Sampling (KTCS). Their method is built around two plain-language goals. First, representativeness: together, the chosen cases should resemble the full mix of everyday driving, so the share of calm versus stressful moments matches what people really experience. Second, coverage: the list must also include enough unusual, high‑risk situations—the long tail of rare but revealing events where automated systems are most likely to stumble. Mathematically, KTCS uses tools from modern statistics and machine learning to search the feature space for a small group of cases that both spreads out to cover extreme conditions and, when given carefully tuned weights, mimics the overall distribution of real driving.
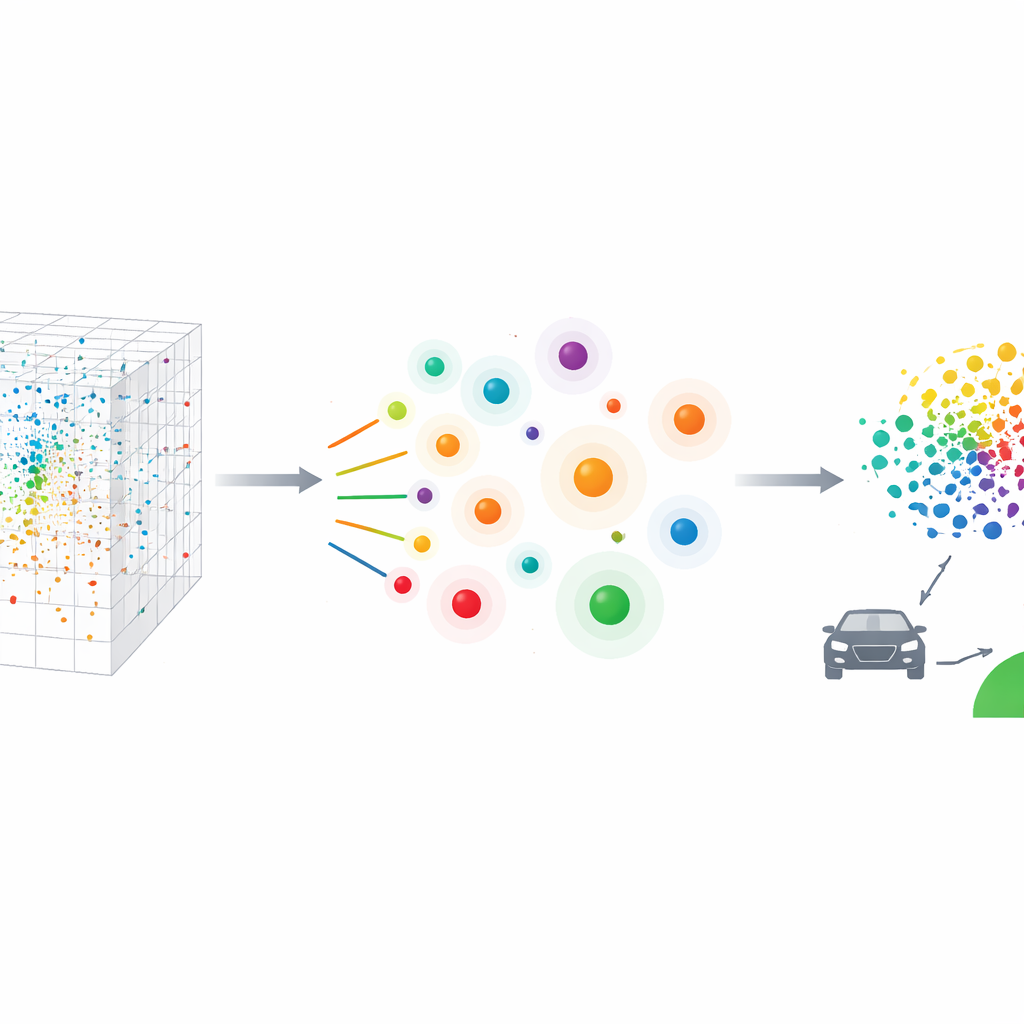
How the new method is tested
The researchers compare KTCS to several leading sampling strategies that either spread cases evenly, focus on dense regions, or target rare outliers. All methods are asked to pick just 118 cases from the large pool. Visual plots and numerical scores show that KTCS best captures the shape of the original data: it aligns closely with real driving for each of the 48 measured features, while still selecting many far‑from‑typical cases where conditions are more extreme. Competing methods either concentrate too heavily on the safest, most common scenes or chase almost nothing but extremes, losing touch with everyday reality. KTCS, by contrast, yields a compact set that looks statistically like the full traffic world yet still includes the most safety‑critical scenarios.
Turning test outcomes into a clear safety score
Having built this refined test set, the authors show how to use it to judge an automated driving system. Each case is run once in simulation or on a track; a "pass" means no crash, and a "fail" means a crash. Because each case has an associated weight and an implied distance driven, the team combines the pass–fail pattern into an estimated crash rate for the system, expressed per meter of driving. They then compare this rate with the crash rate of human drivers measured in the same national study, defining a quantity called "Scaling Risk"—how many times riskier or safer the automated system is than humans. Crucially, failing a common, heavily weighted scenario counts much more against the system than failing a rare edge case, reflecting how often people actually face each situation on the road.
What this means for future self-driving cars
The study’s main message is that we can replace brute‑force mileage with a carefully chosen set of real‑world scenarios and still estimate safety fairly. KTCS offers a principled way to assemble that set so it covers both routine and risky situations, and to turn the results into a clear "how safe is it compared with people" number. This kind of standardized, statistically grounded testing could help regulators, companies, and the public gain confidence that automated driving systems are being judged on realistic, comprehensive evidence rather than on cherry‑picked demos or oversimplified lab tests.
Citation: Qian, C., Xu, J., Xing, X. et al. Test case sampling optimization for safety validation of automated driving systems. Nat Commun 17, 3114 (2026). https://doi.org/10.1038/s41467-026-69675-8
Keywords: automated driving safety, test case sampling, naturalistic driving data, edge case scenarios, self-driving car validation