Clear Sky Science · it
Ottimizzazione del campionamento dei casi di test per la validazione della sicurezza dei sistemi di guida automatizzata
Perché conducenti robot più sicuri contano per tutti
Le auto a guida autonoma promettono meno incidenti, tragitti più fluidi e nuova mobilità per chi oggi non può guidare. Ma prima che il pubblico possa fidarsi di questi sistemi, serve una prova solida che siano almeno altrettanto sicuri dei guidatori umani. Questa prova dipende da come li testiamo: in quali situazioni li mettiamo e come giudichiamo il superamento o il fallimento. Questo articolo affronta un problema centrale di quel processo—come scegliere un insieme piccolo ma efficace di situazioni di guida che rifletta davvero il mondo reale, caotico e imprevedibile, comprese le rare ma pericolose circostanze in cui avvengono gli incidenti.
Dalle strade infinite a una lista di test intelligente
Sulle strade reali quasi tutti i viaggi sono senza eventi degni di nota. Gli incidenti gravi sono rari, ma sono proprio quelli che contano per la sicurezza. Se i regolatori provassero a testare le auto automatizzate limitandosi a percorrere miliardi di miglia e aspettare di vedere cosa succede, la validazione richiederebbe molti anni e costi enormi. Invece, gli ingegneri costruiscono librerie di casi di test: brevi sequenze di guida che possono essere riprodotte in pista o in simulatore. Il problema è decidere quali casi includere. Gli approcci tradizionali fanno affidamento su pochi schemi noti, come il semplice inseguimento di un veicolo o la frenata costante, o su modelli computazionali che imitano solo approssimativamente gli altri guidatori. Di conseguenza, molte situazioni sottili o insolite che causano incidenti reali possono essere trascurate, e i risultati finali sulla sicurezza possono risultare distorti.
Estrarre dal traffico reale i momenti rivelatori
Gli autori basano il loro lavoro sul più grande studio di guida naturalistica negli Stati Uniti, un progetto che ha strumentato migliaia di auto con videocamere, radar e sensori di movimento e ha registrato decine di milioni di miglia di guida ordinaria e incidenti. Da questo archivio costruiscono un insieme di circa 56.000 percorsi normali di 15 secondi e 90 sequenze di incidenti reali, ciascuno descritto da 48 misure che catturano come si è mosso il veicolo, come si sono comportati i veicoli vicini e quanto fossero affollati i dintorni. Un caso di test potrebbe, per esempio, mostrare un’auto che viaggia a velocità autostradale mentre un’altra si inserisce improvvisamente, oppure un tratto tranquillo su una strada sconnessa senza vicini ravvicinati. Questo insieme fa da miniatura statisticamente fedele di ciò che accade realmente sulle strade statunitensi.
Bilanciare scene comuni e pericoli rari
Per trasformare questo enorme insieme in una lista di test pratica, il team introduce il Kernel Test Case Sampling (KTCS). Il loro metodo si basa su due obiettivi espressi in termini chiari. Primo, rappresentatività: insieme, i casi scelti dovrebbero assomigliare al mix completo della guida quotidiana, così che la quota di momenti calmi rispetto a quelli stressanti corrisponda a quanto le persone sperimentano realmente. Secondo, copertura: la lista deve includere anche un numero sufficiente di situazioni insolite e ad alto rischio—la lunga coda di eventi rari ma rivelatori in cui i sistemi automatizzati sono più propensi a inciampare. Matematicamente, KTCS utilizza strumenti della statistica moderna e del machine learning per cercare nello spazio delle caratteristiche un piccolo gruppo di casi che si distribuisca per coprire condizioni estreme e che, una volta dotato di pesi accuratamente calibrati, imiti la distribuzione complessiva della guida reale.
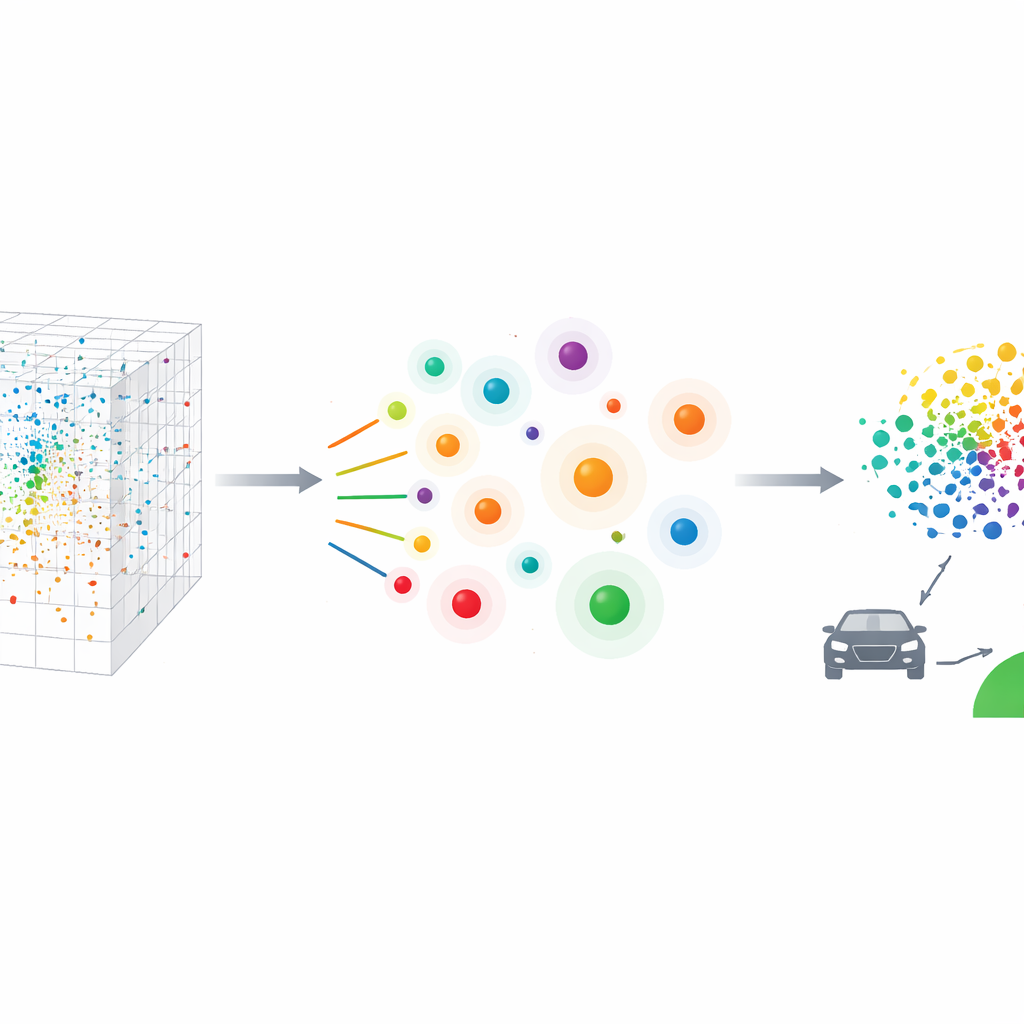
Come viene testato il nuovo metodo
I ricercatori confrontano KTCS con diverse strategie di campionamento all’avanguardia che o distribuiscono i casi in modo uniforme, si concentrano su regioni dense o mirano a outlier rari. A tutti i metodi viene chiesto di selezionare soltanto 118 casi dall’ampio insieme. Grafici visivi e punteggi numerici mostrano che KTCS cattura meglio la forma dei dati originali: si allinea strettamente con la guida reale per ciascuna delle 48 caratteristiche misurate, pur selezionando molti casi lontani dalla tipicità, dove le condizioni sono più estreme. I metodi concorrenti o si concentrano eccessivamente sulle scene più sicure e comuni, oppure inseguono quasi esclusivamente gli estremi, perdendo il contatto con la realtà quotidiana. Al contrario, KTCS produce un insieme compatto che somiglia statisticamente al mondo del traffico completo ma include comunque gli scenari più critici per la sicurezza.
Trasformare i risultati dei test in un chiaro punteggio di sicurezza
Avendo costruito questo set di test raffinato, gli autori mostrano come usarlo per giudicare un sistema di guida automatizzata. Ogni caso viene eseguito una volta in simulazione o in pista; un “pass” significa assenza di incidente e un “fail” significa un incidente. Poiché ogni caso ha un peso associato e una distanza implicita percorsa, il team combina il modello pass–fail in una stima del tasso di incidenti del sistema, espresso per metro percorso. Poi confrontano questo tasso con il tasso di incidenti dei guidatori umani misurato nello stesso studio nazionale, definendo una quantità chiamata “Scaling Risk”—quante volte il sistema automatizzato è più rischioso o più sicuro rispetto agli umani. In modo cruciale, fallire in uno scenario comune e pesato fortemente conta molto di più contro il sistema che fallire in un raro edge case, rispecchiando la frequenza con cui le persone affrontano ciascuna situazione sulla strada.
Cosa significa questo per le future auto a guida autonoma
Il messaggio principale dello studio è che possiamo sostituire la misurazione bruta del chilometraggio con un insieme attentamente selezionato di scenari reali e stimare comunque la sicurezza in modo equo. KTCS offre un modo fondato per assemblare quell’insieme in modo da coprire sia le situazioni di routine sia quelle rischiose, e per trasformare i risultati in un numero chiaro del tipo “quanto è sicuro rispetto alle persone”. Questo tipo di test standardizzato e basato su principi statistici potrebbe aiutare regolatori, aziende e cittadini a guadagnare fiducia sul fatto che i sistemi di guida automatizzata vengono giudicati su prove realistiche e comprensive piuttosto che su demo selezionate o test di laboratorio troppo semplicistici.
Citazione: Qian, C., Xu, J., Xing, X. et al. Test case sampling optimization for safety validation of automated driving systems. Nat Commun 17, 3114 (2026). https://doi.org/10.1038/s41467-026-69675-8
Parole chiave: safety della guida automatizzata, campionamento dei casi di test, dati di guida naturalistica, scenari di edge case, validazione delle auto a guida autonoma