Clear Sky Science · it
OncoRisk: un server web all’avanguardia per collegare banche dati oncologiche e coorti pan-cancro all’oncologia traslazionale
Trasformare i dati del DNA in risposte chiare sul cancro
Il trattamento del cancro dipende sempre più dalla lettura del DNA del tumore del paziente, ma il flusso di dati genetici può sovraccaricare anche gli esperti. Diverse banche dati conservano frammenti del puzzle, ampie coorti di pazienti contengono schemi del mondo reale e le cliniche devono tradurre il tutto in decisioni su farmaci e prognosi. Questo articolo presenta OncoRisk, una piattaforma web gratuita pensata per raccogliere queste risorse disperse in modo che medici e ricercatori possano passare più rapidamente dai dati grezzi del DNA a intuizioni pratiche per le persone con cancro.
Perché il DNA del cancro è così difficile da interpretare
Ogni tumore porta con sé un mix unico di cambiamenti nel DNA. Alcune alterazioni guidano attivamente la crescita tumorale, altre influenzano l’efficacia di un farmaco e molte sono semplicemente rumore di fondo innocuo. Banche dati esperte esistenti come ClinVar, CIViC e OncoKB catturano ciascuna una parte di queste conoscenze, mentre progetti massicci come The Cancer Genome Atlas e AACR Project GENIE hanno profilato centinaia di migliaia di pazienti. Tuttavia queste risorse sono disperse, usano formati diversi e spesso richiedono competenze di programmazione o controlli manuali incrociati su molti siti web. Questa frammentazione rallenta sia la ricerca sia il processo decisionale clinico, soprattutto quando il tumore di un singolo paziente può contenere migliaia di cambiamenti del DNA da esaminare.
Un unico hub web per la conoscenza sulle varianti tumorali
OncoRisk è stato costruito per funzionare come un hub unificato per questo panorama complesso. La piattaforma integra oltre dieci banche di conoscenza oncologica e sette grandi coorti pan-cancro in un’unica interfaccia web. Gli utenti possono cercare un gene, una mutazione specifica, un tipo di cancro o una terapia e vedere immediatamente come sono connessi tra loro. Una funzione di "ricerca rapida" supporta query flessibili usando nomi di geni comuni, codici tecnici delle mutazioni o perfino termini di malattia più generici. Per esplorazioni più approfondite, una vista di rete interattiva mostra come un farmaco, una mutazione e un tipo di cancro siano collegati attraverso evidenze condivise, mentre un “albero genealogico” dei tumori situa ogni malattia all’interno di relazioni più ampie di tessuti e sottotipi.
Da una singola mutazione a strutture 3D e pazienti reali
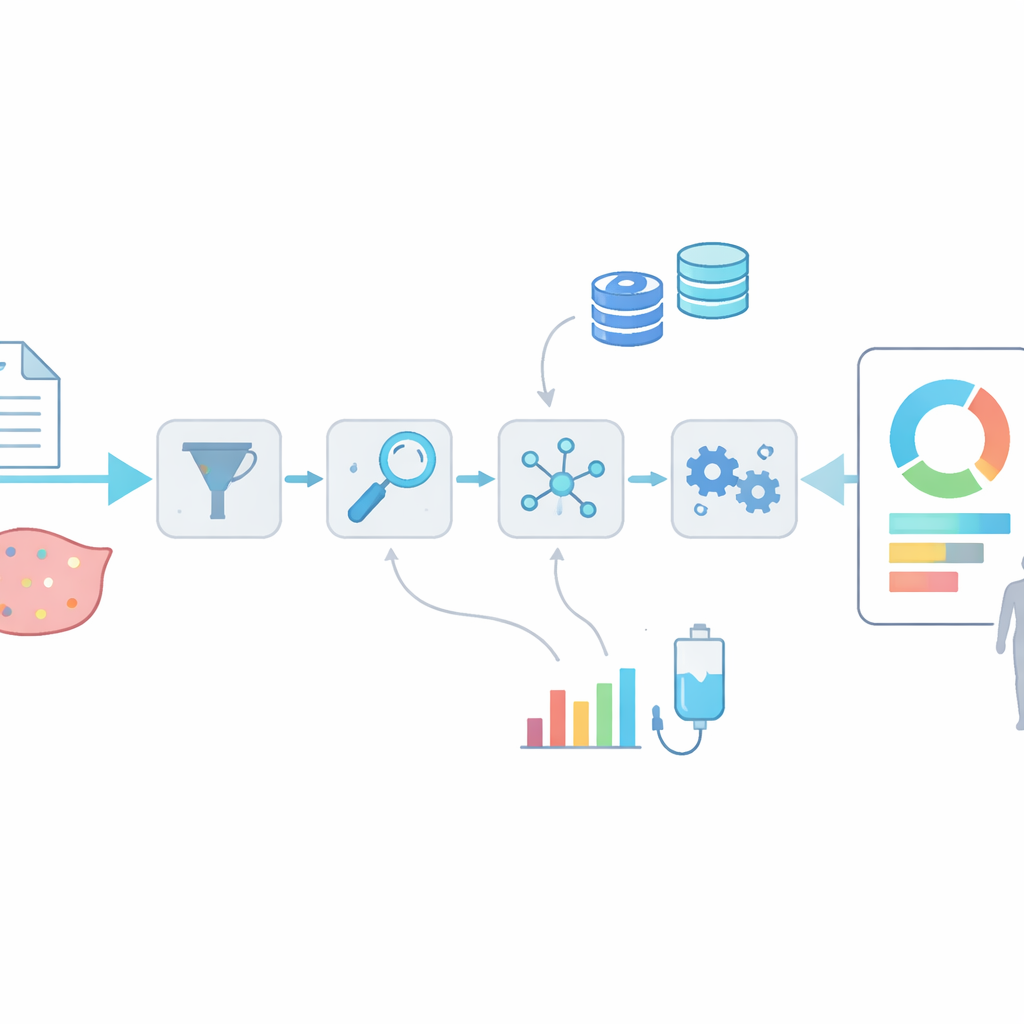
Per qualsiasi cambiamento del DNA, OncoRisk può assemblare una pagina dettagliata incentrata sulla variante. Dietro le quinte esegue strumenti di annotazione consolidati, quindi integra classificazioni su quanto una mutazione sia dannosa, quali farmaci può influenzare e se esistono trial clinici rilevanti. Il sistema mappa la mutazione sugli alberi familiari del cancro e può mostrare strutture proteiche 3D che evidenziano dove un farmaco e una proteina mutata si incontrano fisicamente — o non si incontrano — all’interno della cellula. Contemporaneamente, OncoRisk controlla ampie coorti di pazienti per riportare quanto sia comune la mutazione tra i tipi di cancro e quanto sia presente in un dato campione tumorale. Questa combinazione di viste strutturali, evidenze cliniche e dati di frequenza del mondo reale aiuta gli utenti a valutare quali mutazioni probabilmente contino di più.
Report automatici per singoli pazienti e intere coorti
Oltre alle singole varianti, OncoRisk offre una pipeline semi-automatica che trasforma un intero file di DNA tumorale in un report leggibile dall’uomo. Gli utenti caricano un file variante standard, dopodiché il sistema filtra le alterazioni di alta qualità, le annota e integra evidenze di supporto da più banche dati. Raggruppa quindi le mutazioni in livelli (tier) basati sulla forza e sull’azione delle evidenze, producendo un PDF strutturato e un file di dati esportabile che mettono in evidenza potenziali bersagli farmacologici e opzioni di trial clinici. Nei test su sei campioni tumorali reali, il sistema ha rapidamente evidenziato mutazioni e terapie note come driver del cancro, anche quando queste erano originariamente descritte in altri tipi tumorali. Un modulo complementare, chiamato server-maftools, permette ai ricercatori di caricare centinaia o migliaia di campioni contemporaneamente per visualizzare schemi di mutazione, confrontare sottotipi tumorali e collegare particolari cambiamenti del DNA alla sopravvivenza dei pazienti o allo stadio del tumore.
Cosa significa questo per la cura e la ricerca del cancro
OncoRisk non è un dispositivo diagnostico autonomo e non sostituisce linee guida esperte né il giudizio medico. Agisce invece come un assistente potente che raccoglie evidenze disperse, le organizza in modo coerente e rende molto più semplici da vedere i collegamenti tra cambiamenti del DNA, tipi di cancro, farmaci e risultati clinici. Unendo conoscenze curate da esperti con dati di pazienti del mondo reale, la piattaforma punta ad accorciare il percorso dal sequenziamento di un tumore al suggerimento delle domande, dei trial e delle opzioni di trattamento più rilevanti. Per i pazienti, questo potrebbe tradursi in spiegazioni più rapide e chiare su cosa significa il DNA del loro tumore; per i ricercatori, offre un unico ambiente flessibile per esplorare paesaggi mutazionali e testare nuove idee attraverso molte coorti.
Citazione: Song, X., Green, E., Liao, X. et al. OncoRisk: a state-of-the-art web server for bridging the oncogenic databases and pan-cancer cohorts to the translational oncology. Commun Biol 9, 519 (2026). https://doi.org/10.1038/s42003-026-10005-5
Parole chiave: oncologia di precisione, genomica del cancro, interpretazione delle varianti, piattaforma bioinformatica, coorti pan-cancro