Clear Sky Science · fr
OncoRisk : un serveur web de pointe pour relier les bases de données oncologiques et les cohortes pan-cancer à l’oncologie translationnelle
Transformer les données ADN en réponses claires sur le cancer
Le traitement du cancer repose de plus en plus sur l’analyse de l’ADN de la tumeur d’un patient, mais le flot de données génétiques peut submerger même les spécialistes. Différentes bases de données conservent des fragments du puzzle, de larges cohortes de patients reflètent des schémas réels, et les cliniciens doivent convertir l’ensemble en décisions sur les traitements et le pronostic. Cet article présente OncoRisk, une plateforme web gratuite conçue pour rassembler ces ressources dispersées afin que médecins et chercheurs puissent passer plus rapidement des données ADN brutes à des informations pratiques pour les personnes atteintes de cancer.
Pourquoi l’ADN tumoral est si difficile à interpréter
Chaque tumeur porte un mélange unique de modifications de l’ADN. Certaines altérations stimulent activement la croissance tumorale, d’autres influencent l’efficacité d’un médicament, et beaucoup sont simplement du bruit de fond sans conséquence. Des bases de données expertes existantes comme ClinVar, CIViC et OncoKB captent chacune une partie de ce savoir, tandis que d’immenses projets tels que The Cancer Genome Atlas et AACR Project GENIE ont profillé des centaines de milliers de patients. Pourtant, ces ressources sont éparses, utilisent des formats différents et nécessitent souvent des compétences en programmation ou des vérifications manuelles sur de nombreux sites. Cette fragmentation ralentit la recherche et la prise de décision clinique, en particulier lorsqu’une tumeur individuelle peut contenir des milliers de modifications à examiner.
Un hub web unique pour les connaissances sur les variants cancéreux
OncoRisk a été développé pour servir de hub unifié dans ce paysage complexe. La plateforme intègre plus de dix bases de connaissances en oncologie et sept grandes cohortes pan-cancer au sein d’une interface web unique. Les utilisateurs peuvent rechercher un gène, une mutation spécifique, un type de cancer ou une thérapie et voir immédiatement comment ces éléments se connectent. Une fonction de « recherche rapide » prend en charge des requêtes flexibles utilisant des noms de gènes courants, des codes techniques de mutation ou même des termes de maladie généraux. Pour une exploration plus approfondie, une vue réseau interactive montre comment un médicament, une mutation et un type de cancer sont liés par des preuves partagées, tandis qu’un « arbre généalogique » des cancers situe chaque maladie dans des relations tissulaires et de sous-types plus larges.
D’une seule mutation aux structures 3D et aux patients réels
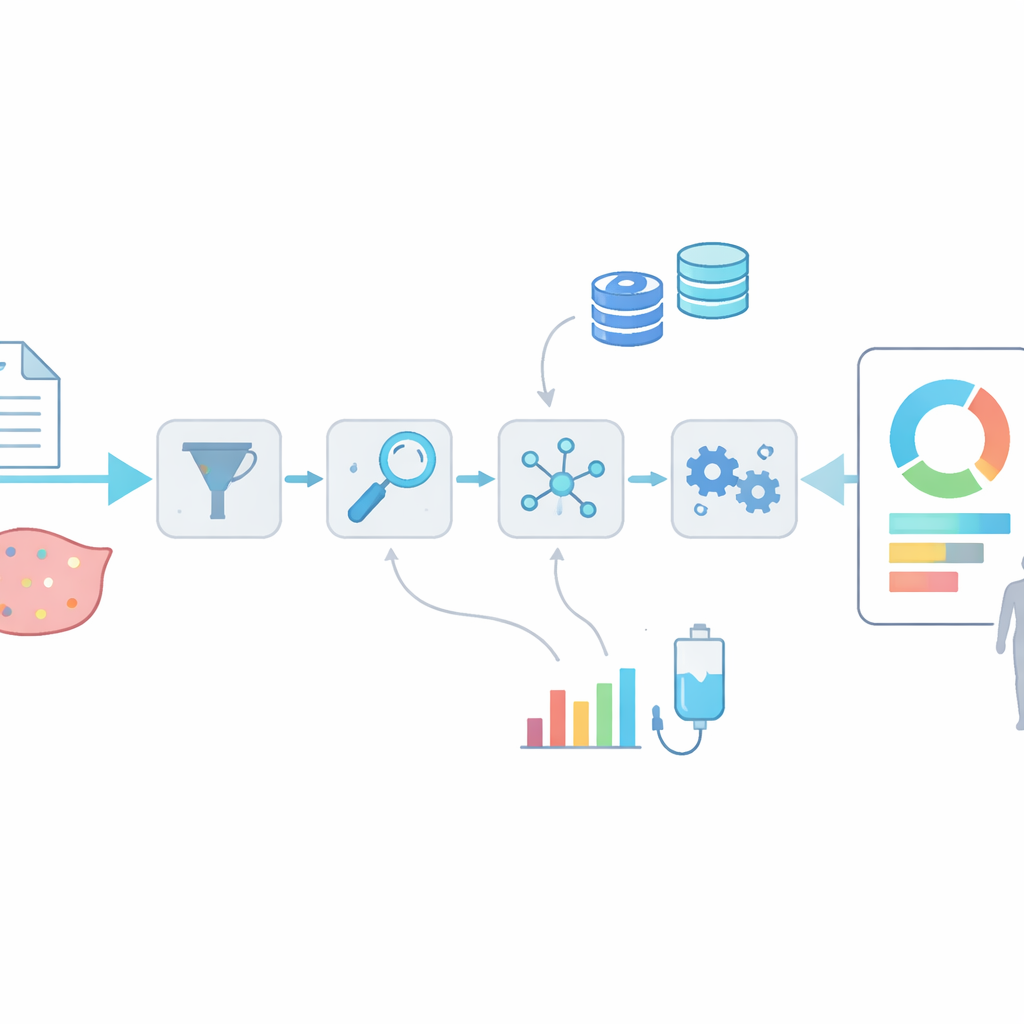
Pour toute modification de l’ADN, OncoRisk peut assembler une page détaillée centrée sur le variant. En coulisses, il exécute des outils d’annotation établis, puis agrège les classifications de la nocivité d’une mutation, les médicaments qu’elle peut affecter et l’existence d’essais cliniques pertinents. Le système cartographie la mutation sur les arbres généalogiques des cancers et peut afficher des structures protéiques 3D montrant où un médicament et une protéine mutée se rencontrent — ou ne se rencontrent pas — physiquement dans la cellule. Parallèlement, OncoRisk interroge de larges cohortes de patients pour indiquer la prévalence de la mutation selon les types de cancer et son importance dans un échantillon tumoral donné. Cette combinaison de vues structurales, de preuves cliniques et de données de fréquence en conditions réelles aide les utilisateurs à évaluer quelles mutations sont susceptibles d’avoir le plus d’impact.
Rapports automatisés pour patients individuels et cohortes entières
Au-delà des variants isolés, OncoRisk propose une chaîne semi-automatisée qui transforme un fichier ADN tumoral complet en un rapport lisible par un humain. Les utilisateurs téléversent un fichier de variants standard ; le système filtre alors les modifications de haute qualité, les annote et regroupe les preuves issues de plusieurs bases. Il classe ensuite les mutations en niveaux (tiers) selon la force et l’actionnabilité des preuves, produisant un PDF structuré et un fichier de données exportable qui mettent en évidence des cibles médicamenteuses potentielles et des options d’essais cliniques. Dans des tests sur six échantillons tumoraux réels, le système a rapidement mis en évidence des mutations et des thérapies connues comme moteurs du cancer, même lorsqu’elles avaient été décrites initialement dans d’autres types de cancer. Un module compagnon, nommé server-maftools, permet aux chercheurs de charger des centaines ou des milliers d’échantillons à la fois pour visualiser les schémas de mutations, comparer des sous-types de cancer et relier des modifications spécifiques aux survies des patients ou au stade tumoral.
Ce que cela signifie pour les soins et la recherche en cancérologie
OncoRisk n’est pas un dispositif diagnostique autonome et ne remplace pas les lignes directrices d’experts ni le jugement médical. Il agit plutôt comme un assistant puissant qui rassemble des preuves dispersées, les organise de façon cohérente et rend les liens entre modifications de l’ADN, types de cancer, médicaments et résultats beaucoup plus visibles. En unissant des connaissances expertes curatées à des données de patients en conditions réelles, la plateforme vise à raccourcir le chemin entre le séquençage d’une tumeur et la suggestion des questions, essais et options de traitement les plus pertinents. Pour les patients, cela peut se traduire par des explications plus rapides et plus claires de ce que signifie l’ADN de leur tumeur ; pour les chercheurs, cela offre un environnement unique et flexible pour explorer les paysages mutationnels et tester de nouvelles idées à travers de nombreuses cohortes.
Citation: Song, X., Green, E., Liao, X. et al. OncoRisk: a state-of-the-art web server for bridging the oncogenic databases and pan-cancer cohorts to the translational oncology. Commun Biol 9, 519 (2026). https://doi.org/10.1038/s42003-026-10005-5
Mots-clés: oncologie de précision, génomique du cancer, interprétation des variants, plateforme bioinformatique, cohortes pan-cancer