Clear Sky Science · it
Stima dell’assestamento indotto da liquefazione delle fondazioni superficiali mediante apprendimento automatico con dati sbilanciati
Perché il terreno che trema è importante per gli edifici di tutti i giorni
Quando un forte terremoto colpisce, un terreno che sembra solido può temporaneamente comportarsi come un liquido, causando affondamenti, inclinazioni o crepe negli edifici. Questo fenomeno, chiamato liquefazione, ha danneggiato abitazioni e infrastrutture in molti terremoti recenti, dalla Turchia al Giappone. Gli ingegneri sanno che anche pochi decine di centimetri di assestamento differenziale possono rendere un edificio non sicuro o inutilizzabile. Tuttavia prevedere quanto affonderà un edificio specifico, basandosi su dati di sito limitati, resta difficile. Questo studio esplora come gli strumenti moderni di apprendimento automatico possano trasformare storie di casi frammentarie tratte da terremoti reali in un metodo pratico per anticipare i danni correlati alla liquefazione e guidare progettazioni più sicure, decisioni assicurative e ispezioni post-sisma. 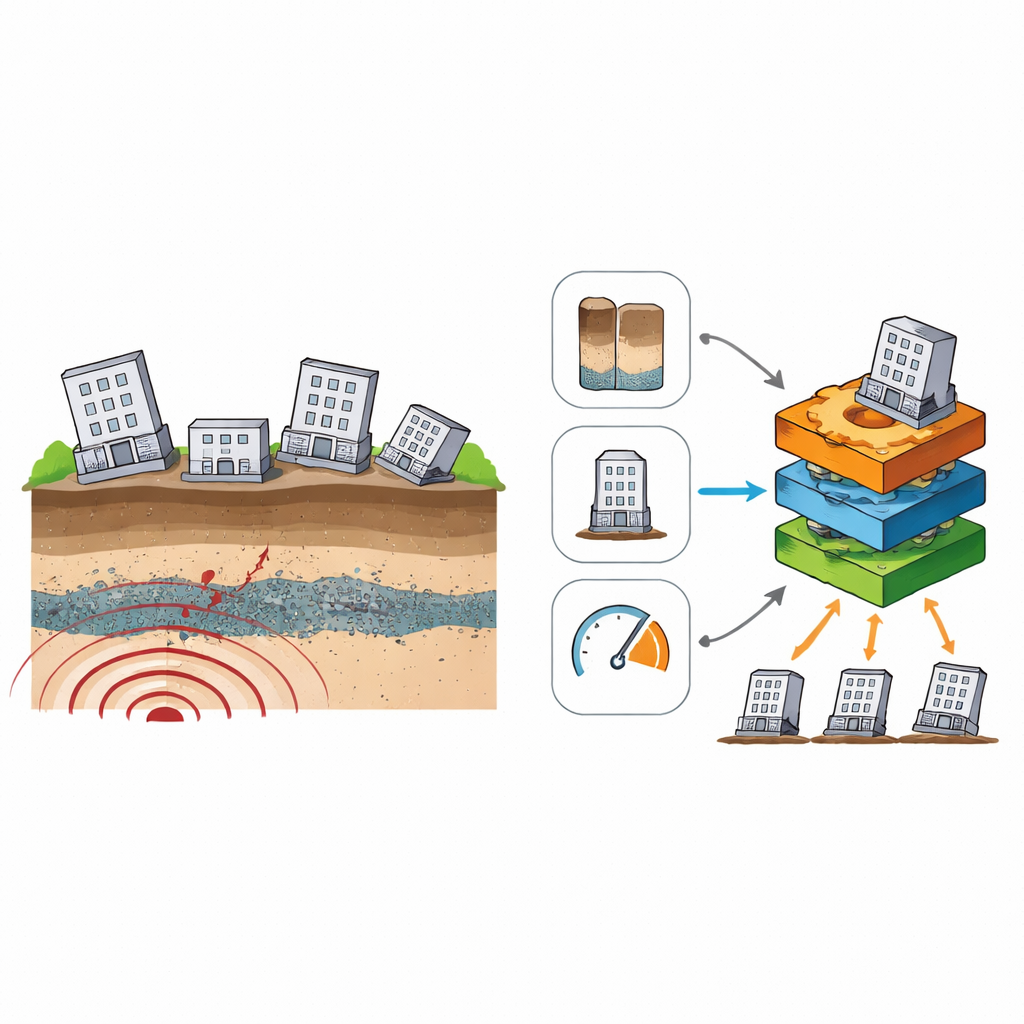
Da resoconti sparsi a un database sismico globale
I ricercatori hanno iniziato assemblando un database mondiale di 206 edifici che hanno subito cedimenti del terreno dovuti a liquefazione durante terremoti passati. Per ogni caso hanno raccolto informazioni semplici che spesso sono disponibili nella pratica: l’intensità delle scosse nel sito, l’altezza e la larghezza complessiva dell’edificio, la pressione che l’edificio esercita sulla fondazione e le proprietà chiave degli strati di terreno sottostanti—in particolare a quale profondità si trova il primo strato liquefacibile rispetto alla superficie e quanto è spesso. Invece di cercare di calcolare un assestamento esatto in centimetri, hanno raggruppato gli esiti in quattro livelli di danno, dall’assenza di cedimenti visibili fino ad affondamenti e inclinazioni estese. Questo “indice di cedimento del terreno” trasforma misurazioni disordinate del mondo reale in categorie chiare utilizzabili per addestrare e testare modelli di apprendimento automatico.
Insegnare ai computer a riconoscere pattern pericolosi in dati sbilanciati
I registri sismici reali sono tutt’altro che ordinati: alcuni tipi di danno sono comuni mentre altri sono rari, e le variabili in ingresso possono contenere valori anomali e rumore. In questo set di dati i casi di danno severo erano molto più frequenti di quelli moderati, creando un forte sbilanciamento che può indurre in errore molti algoritmi facendoli trascurare la classe più rara. Per affrontare ciò, gli autori hanno combinato sistematicamente diverse strategie. Hanno pulito i dati con metodi di filtraggio degli outlier, quindi hanno esplorato due approcci complementari per gestire lo sbilanciamento: il copia-incolla artificiale dei casi di minoranza (oversampling casuale) e l’assegnare agli algoritmi un costo maggiore per gli errori sulle classi rare (apprendimento sensibile al costo). Per evitare risultati eccessivamente ottimistici, tutti questi passaggi sono stati inseriti in un rigoroso flusso di lavoro “senza perdite” (leakage-free), in cui i dati di test sono rimasti completamente nascosti durante l’addestramento, la messa a punto e il risampling dei modelli.
Quali fattori e quali modelli catturano meglio il rischio di assestamento?
Diversi modelli ampiamente usati sono stati messi alla prova, inclusi foreste casuali (random forests), metodi di gradient boosting, una rete neurale artificiale e un ensemble che media le previsioni di più modelli. Poiché l’accuratezza complessiva può nascondere scarse prestazioni sulle classi rare ma importanti, il gruppo ha posto enfasi sul recall—quante delle vere situazioni severe il modello individua correttamente—come metrica chiave. Il Gradient Boosting e un ensemble di modelli basati su alberi sono emersi come le opzioni più affidabili, particolarmente se combinati con oversampling casuale, un trattamento accurato degli outlier e soglie decisionali ben tarate. Per capire cosa i modelli “stessero guardando”, gli autori hanno usato SHAP, uno strumento che scompone ogni previsione nelle contribuzioni delle singole caratteristiche. Questa analisi ha mostrato che la profondità del primo strato liquefacibile era il fattore singolo più influente, seguita dall’intensità delle scosse e dalla geometria di base della fondazione, come la larghezza dell’edificio. In termini semplici, strati poco profondi e facilmente liquefacibili sotto fondazioni strette sono risultati costantemente associati ai danni più gravi. 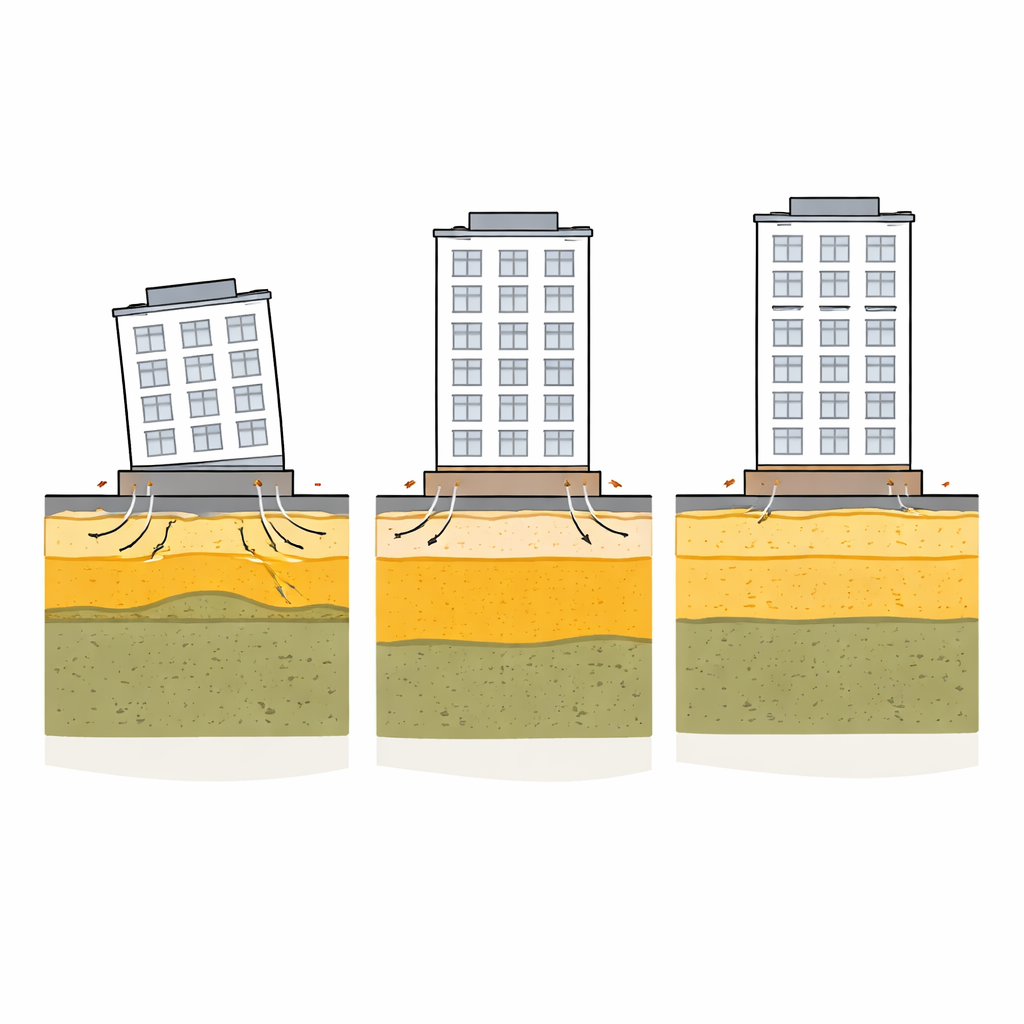
Testare l’approccio su studi di caso sismici reali
Per verificare se i loro metodi funzionassero al di fuori del campione di addestramento, i ricercatori hanno applicato i modelli finali a quattro studi di caso dettagliati tratti da terremoti noti, inclusi l’evento di Loma Prieta del 1989 in California, il terremoto di Kocaeli del 1999 in Turchia, la sequenza di Kumamoto del 2016 in Giappone e il terremoto di Kahramanmaraş del 2023 in Turchia. In questi esempi, gli unici input erano stime semplici dell’intensità delle scosse, dimensioni e carichi degli edifici e la profondità e spessore degli strati liquefacibili ricavati da prove in sito. I modelli hanno in generale rispecchiato la gravità osservata degli assestamenti, identificando correttamente sia danni lievi sia danni estesi. In un caso il modello ha scelto intenzionalmente un errore prudente prevedendo una classe di danno superiore a quella riportata. Gli autori sostengono che in contesti ad alto rischio come la resilienza sismica, tali previsioni conservative siano preferibili rispetto al rischio di non individuare edifici gravemente danneggiati.
Un aiuto guidato dai dati per città più sicure su terreni soffici
Questo lavoro non sostituisce le formule tradizionali basate sulla fisica per l’assestamento, che restano essenziali quando sono disponibili risultati dettagliati delle prove geotecniche. Offre invece uno strumento complementare: un metodo trasparente e guidato dai dati per classificare gli edifici in ampie categorie di rischio usando un piccolo insieme di parametri raccolti di routine. Gestendo con attenzione dati sbilanciati, evitando bias nascosti nella valutazione e rivelando quali caratteristiche del terreno e dell’edificio contano di più, il quadro di apprendimento automatico proposto fornisce a ingegneri, pianificatori e assicuratori un ausilio pratico di allerta precoce. Nelle regioni costruite su terreni soffici e sature d’acqua, può aiutare a dare priorità agli edifici più probabili a subire pericolosi affondamenti e inclinazioni quando colpirà il prossimo grande terremoto.
Citazione: Sargin, S., Korkmaz, G., Yildirim, A.K. et al. Estimation of liquefaction-induced settlement of shallow foundation by machine learning with imbalanced data. Sci Rep 16, 11198 (2026). https://doi.org/10.1038/s41598-026-41969-3
Parole chiave: liquefazione del suolo, ingegneria sismica, apprendimento automatico, assestamento degli edifici, rischio sismico