Clear Sky Science · de
Abschätzung der durch Verflüssigung verursachten Setzungen von Flachgründungen mit maschinellem Lernen bei unausgewogenen Daten
Warum sich bewegender Boden für alltägliche Gebäude wichtig ist
Wenn ein starkes Erdbeben eintrifft, kann sich fest erscheinender Boden kurzzeitig wie eine Flüssigkeit verhalten und dazu führen, dass Gebäude einsinken, sich neigen oder Risse bekommen. Dieses Phänomen, Verflüssigung genannt, hat in vielen jüngeren Erdbeben von der Türkei bis Japan Wohnhäuser und Infrastrukturen beschädigt. Ingenieure wissen, dass bereits einige zehn Zentimeter ungleichmäßiger Setzung ein Gebäude unsicher oder unbenutzbar machen können. Dennoch bleibt es schwierig, vorherzusagen, wie stark ein konkretes Gebäude auf Basis begrenzter Standortdaten einsinken wird. Diese Studie untersucht, wie moderne Methoden des maschinellen Lernens verstreute Fallberichte aus realen Erdbeben in ein praktisches Werkzeug verwandeln können, um verflüssigungsbedingte Schäden besser vorherzusehen und sicherere Entwürfe, Versicherungsentscheidungen und Inspektionen nach Katastrophen zu unterstützen. 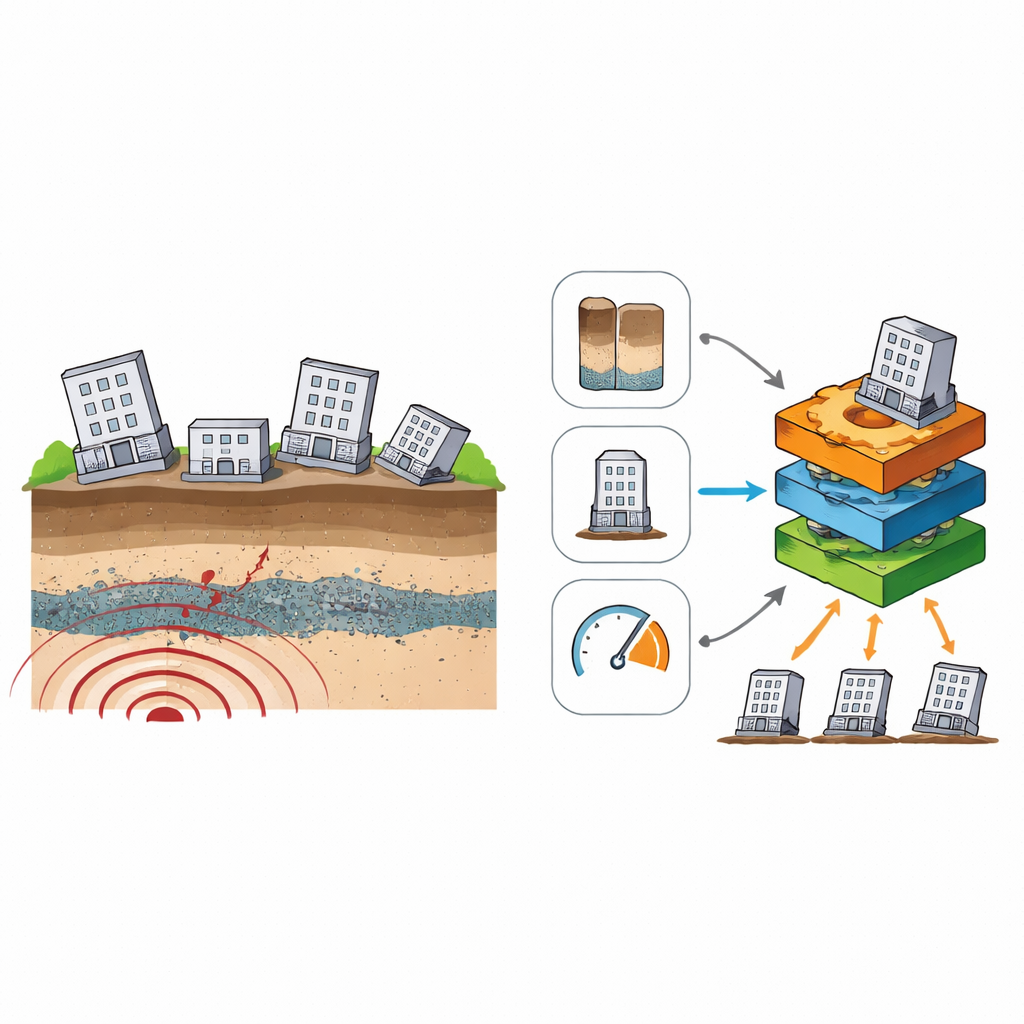
Von verstreuten Fallberichten zu einem globalen Erdbebendatensatz
Die Forschenden begannen damit, eine weltweite Datenbank mit 206 Gebäuden zusammenzustellen, die in früheren Erdbeben Bodenversagen durch Verflüssigung erlitten hatten. Für jeden Fall sammelten sie einfache Informationen, die in der Praxis häufig verfügbar sind: die Intensität der Erschütterungen am Standort, die Gesamthöhe und -breite des Gebäudes, den auf die Gründung wirkenden Druck sowie wesentliche Eigenschaften der darunter liegenden Bodenschichten – insbesondere die Tiefe der ersten verflüssigbaren Schicht unter der Oberfläche und deren Mächtigkeit. Statt zu versuchen, eine genaue Setzung in Zentimetern zu berechnen, gruppierten sie die Ergebnisse in vier Schadensstufen, von keiner sichtbaren Setzung bis zu ausgeprägtem Einsinken und Neigen. Dieser „Ground Failure Index“ verwandelt unordentliche Messungen aus der Praxis in klare Kategorien, die zur Ausbildung und Prüfung von Modellen des maschinellen Lernens verwendet werden können.
Computern beibringen, gefährliche Muster in unausgewogenen Daten zu erkennen
Reale Erdbebenaufzeichnungen sind alles andere als ordentlich: Manche Schadensarten sind häufig, andere selten, und die Eingangsvariablen können Ausreißer und Rauschen enthalten. In diesem Datensatz waren schwere Schäden deutlich häufiger als mittlere, was ein starkes Ungleichgewicht erzeugt, das viele Algorithmen dazu verleiten kann, die seltenere Klasse zu übersehen. Um dem zu begegnen, kombinierten die Autorinnen und Autoren systematisch mehrere Strategien. Sie bereinigten die Daten mit Methoden zur Filterung von Ausreißern und untersuchten dann zwei komplementäre Ansätze zum Umgang mit Ungleichgewicht: das künstliche Kopieren von Minderheitsfällen (random oversampling) und das Vorgehen, bei dem Algorithmen Fehler bei seltenen Klassen als kostspieliger behandeln (cost-sensitive learning). Um übermäßig optimistische Ergebnisse zu vermeiden, wurden all diese Schritte in einen strengen, „leakage-freien“ Arbeitsablauf eingebettet, bei dem die Testdaten während Training, Abstimmung und Resampling völlig unberührt blieben.
Welche Faktoren und Modelle erfassen das Setzungsrisiko am besten?
Mehrere weit verbreitete Modelle wurden getestet, darunter Random Forests, Gradient-Boosting-Verfahren, ein künstliches neuronales Netzwerk und ein Ensemble, das die Vorhersagen mehrerer Modelle mittelt. Weil die Gesamtgenauigkeit die schlechte Leistung bei seltenen, aber wichtigen Schadensstufen verschleiern kann, legte das Team besonderen Wert auf Recall – also darauf, wie viele der tatsächlich schweren Fälle das Modell korrekt erkennt – als Schlüsselkennzahl. Gradient Boosting und ein Ensemble baumbasierter Modelle erwiesen sich als die zuverlässigsten Optionen, insbesondere in Kombination mit random oversampling, sorgfältiger Ausreißerbehandlung und fein abgestimmten Entscheidungsgrenzwerten. Um zu verstehen, worauf die Modelle „achten“, verwendeten die Autorinnen und Autoren SHAP, ein Werkzeug, das jede Vorhersage in Beiträge einzelner Merkmale zerlegt. Diese Analyse zeigte, dass die Tiefe bis zur ersten verflüssigbaren Schicht der einflussreichste Faktor war, gefolgt von der Erschütterungsintensität und grundlegender Gründungsgeometrie wie der Gebäudebreite. In einfachen Worten: Flache, leicht verflüssigbare Schichten unter schmalen Fundamenten standen beständig mit den schwersten Schäden in Zusammenhang. 
Prüfung des Ansatzes an realen Erdbeben-Fallstudien
Um zu prüfen, ob ihre Methoden außerhalb der Trainingsstichprobe funktionieren, wandten die Forschenden die finalen Modelle auf vier detaillierte Fallstudien bekannter Erdbeben an, darunter das Loma-Prieta-Ereignis 1989 in Kalifornien, das Erdbeben von Kocaeli 1999 in der Türkei, die Kumamoto-Sequenz 2016 in Japan und das Erdbeben von Kahramanmaraş 2023 in der Türkei. In diesen Beispielen waren die einzigen Eingaben einfache Schätzungen der Erschütterungsintensität, Gebäudedimensionen und -lasten sowie die Tiefe und Mächtigkeit verflüssigbarer Schichten aus Felduntersuchungen. Die Modelle stimmten im Allgemeinen mit dem beobachteten Schweregrad der Setzung überein und identifizierten sowohl geringe als auch ausgeprägte Schadensstufen korrekt. In einem Fall lag das Modell bewusst auf der sicheren Seite, indem es eine höhere Schadensklasse prognostizierte als berichtet. Die Autorinnen und Autoren argumentieren, dass in risikoreichen Situationen wie der Erdbebenresilienz solche konservativen Vorhersagen dem Verfehlen schwer beschädigter Gebäude vorzuziehen sind.
Ein datengetriebenes Hilfsmittel für sicherere Städte auf weichem Untergrund
Diese Arbeit ersetzt nicht die traditionellen, physikbasierten Formeln zur Setzungsberechnung, die weiterhin unverzichtbar sind, wenn detaillierte Bodentestergebnisse vorliegen. Stattdessen bietet sie ein komplementäres Werkzeug: einen transparenten, datengetriebenen Weg, Gebäude mit einer kleinen Anzahl routinemäßig erfasster Parameter in grobe Risikokategorien einzuordnen. Durch die sorgfältige Behandlung unausgewogener Daten, das Vermeiden versteckter Bewertungsbiases und das Aufzeigen, welche Boden- und Gebäudeeigenschaften am wichtigsten sind, liefert das vorgeschlagene Framework des maschinellen Lernens Planern, Ingenieuren und Versicherern ein praxisnahes Frühwarnhilfsmittel. In Regionen, die auf weichem, wassergesättigtem Untergrund gebaut sind, kann es helfen zu priorisieren, welche Gebäude am ehesten gefährliches Einsinken und Neigen bei einem nächsten größeren Erdbeben erleiden werden.
Zitation: Sargin, S., Korkmaz, G., Yildirim, A.K. et al. Estimation of liquefaction-induced settlement of shallow foundation by machine learning with imbalanced data. Sci Rep 16, 11198 (2026). https://doi.org/10.1038/s41598-026-41969-3
Schlüsselwörter: Bodenverflüssigung, Erdbebeningenieurwesen, maschinelles Lernen, Gebäudesetzung, seismisches Risiko