Clear Sky Science · it
Integrazione di convoluzione multi-scala e meccanismi di attenzione in HybridHAR per un riconoscimento delle attività umane ad alte prestazioni
Perché insegnare ai computer i movimenti quotidiani è importante
Ogni giorno i nostri telefoni, orologi e altri dispositivi registrano discretamente come ci muoviamo — che stiamo camminando, salendo le scale o riposando sul divano. Trasformare questi segnali di movimento grezzi in una comprensione affidabile delle attività umane potrebbe rivoluzionare il monitoraggio della salute, l’assistenza agli anziani, la riabilitazione e le abitazioni intelligenti. Questo articolo presenta HybridHAR, un nuovo modello informatico progettato per leggere quei segnali in modo più accurato ed efficiente, avvicinandoci a dispositivi indossabili in grado di comprendere in tempo reale cosa stiamo facendo.
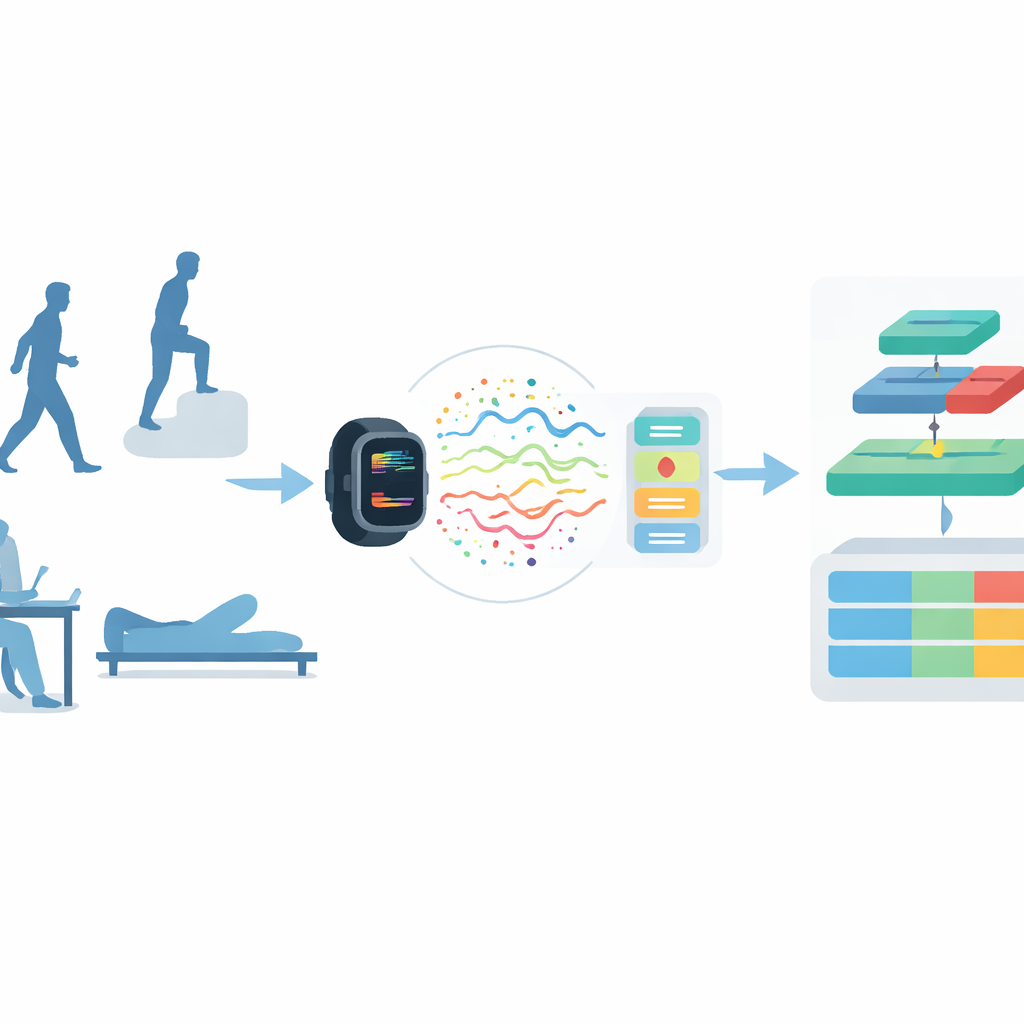
Capire l’attività dai sensori di movimento
Il riconoscimento delle attività umane è il compito di determinare cosa sta facendo una persona basandosi su sensori come accelerometri e giroscopi presenti in smartphone e dispositivi indossabili. I sistemi precedenti si basavano su esperti che costruivano manualmente caratteristiche da questi segnali e le alimentavano in algoritmi di machine learning tradizionali. Quell’approccio funzionava in ambienti di laboratorio controllati ma spesso falliva nel mondo reale, più disordinato e rumoroso. L’apprendimento profondo ha migliorato la situazione scoprendo automaticamente pattern nei dati, tuttavia le architetture comuni perdono ancora dettagli importanti che si sviluppano su scale temporali diverse e possono perdere informazione man mano che le reti diventano più profonde.
Perché i modelli profondi esistenti faticano ancora
I movimenti umani avvengono simultaneamente su molte scale temporali: un passo rapido, una breve camminata attraverso la stanza o un lungo periodo seduti. Molti modelli di deep learning si concentrano o su frammenti brevi o su intervalli più lunghi, ma non entrambi in egual misura. Man mano che le reti aggiungono più strati per catturare pattern complessi possono incontrare un indebolimento dei segnali di apprendimento, facendo sì che gli strati iniziali smettano di migliorare. Alcuni modelli poi non forniscono guida agli strati interni, perciò non imparano i mattoni a livello medio più utili per riconoscere attività che appaiono simili nei segnali grezzi, come sedersi rispetto a stare in piedi.
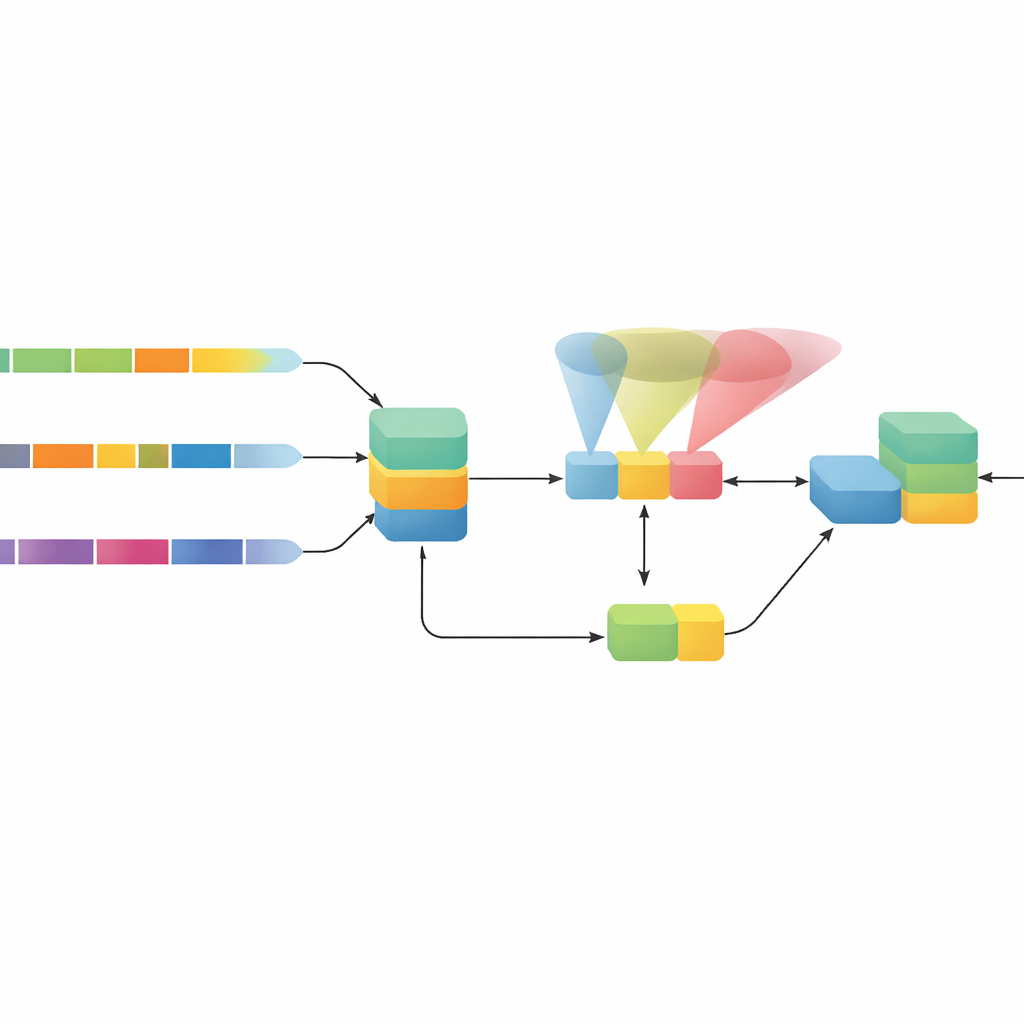
Un progetto ibrido che osserva il movimento in più modi
Gli autori propongono HybridHAR, un modello progettato con cura che affronta queste debolezze con tre idee principali che agiscono in sinergia. Primo, invece di usare un’unica finestra temporale, passa lo stesso segnale del sensore attraverso tre percorsi paralleli che guardano ciascuno a scale temporali differenti — da segmenti molto brevi a intervalli più lunghi. Questi percorsi fungono da tre lenti distinte, catturando i dettagli fini dei gesti rapidi così come le tendenze più lente di postura e movimento. I loro output vengono poi combinati in una rappresentazione ricca che preserva informazioni da tutte queste scale.
Attenzione e guida dell’apprendimento nelle parti profonde del modello
Secondo, HybridHAR aggiunge un modulo di attenzione speciale sopra questa rappresentazione combinata. Questo meccanismo impara a evidenziare le parti più significative del segnale — per esempio le sottili differenze di movimento che separano il salire le scale dal scendere — mantenendo al contempo un percorso di scorciatoia che preserva l’informazione originale. Questa scorciatoia "residua" aiuta i segnali di apprendimento a fluire agevolmente attraverso la rete, prevenendo che l’informazione venga diluita nei livelli più profondi. Terzo, al modello viene fornito un classificatore ausiliario che sfrutta caratteristiche intermedie prima che l’attenzione venga applicata. Durante l’addestramento anche questo output ausiliario viene valutato, costringendo dolcemente gli strati precoci a imparare caratteristiche già sufficienti per formulare ipotesi sull’attività, il che stabilizza e accelera l’apprendimento.
Quanto bene funziona il nuovo approccio
Per testare HybridHAR i ricercatori hanno usato un dataset pubblico ampiamente adottato in cui volontari indossavano uno smartphone mentre eseguivano sei attività di base: tre tipi di camminata più seduto, in piedi e sdraiato. Su questo benchmark HybridHAR ha raggiunto circa il 99% di accuratezza sui dati di validazione non usati per l’addestramento e il 96% su un set di test non visto, superando diverse alternative robuste, incluse reti convoluzionali classiche, reti ricorrenti, modelli ibridi e approcci basati su reinforcement learning. Si è mostrato particolarmente efficace nel distinguere attività di camminata simili riducendo gli errori tra coppie facilmente confondibili come salire e scendere le scale. Il team ha anche dimostrato che ciascuno dei tre ingredienti — i percorsi multi-scala, l’attenzione e la supervisione profonda — migliorava in modo misurabile i risultati, e che il modello completo forniva prestazioni migliori rispetto a qualsiasi variante a cui mancasse uno di essi.
Perché questo conta per i dispositivi reali
Nonostante l’elevata accuratezza, HybridHAR rimane compatto e veloce, con molti meno parametri da regolare rispetto a molti modelli concorrenti e la capacità di elaborare centinaia di finestre di attività al secondo usando circa un megabyte di memoria. Si è anche generalizzato bene su un secondo dataset più complesso con più attività e configurazioni di sensori più ricche, dove ha ottenuto risultati ancora migliori. Per i non esperti, il messaggio chiave è che questo progetto offre un modello pratico per trasformare segnali indossabili rumorosi in descrizioni affidabili e dettagliate di ciò che le persone stanno facendo. Modelli di questo tipo potrebbero rendere i futuri monitor della salute, le case intelligenti e i sistemi di sicurezza più affidabili e più facili da eseguire su dispositivi di uso quotidiano.
Citazione: Huo, Y., Wei, C., Xu, Z. et al. Integrating multi-scale convolution and attention mechanisms in HybridHAR for high-performance human activity recognition. Sci Rep 16, 10143 (2026). https://doi.org/10.1038/s41598-026-40904-w
Parole chiave: riconoscimento delle attività umane, sensori indossabili, apprendimento profondo, meccanismi di attenzione, monitoraggio della salute