Clear Sky Science · fr
Intégration de convolutions multi‑échelles et de mécanismes d'attention dans HybridHAR pour une reconnaissance d'activité humaine haute performance
Pourquoi apprendre aux ordinateurs nos mouvements quotidiens importe
Chaque jour, nos téléphones, montres et autres appareils enregistrent discrètement nos déplacements — que nous marchions, montions des escaliers ou restions affalés sur le canapé. Transformer ces signaux de mouvement bruts en une compréhension fiable des activités humaines pourrait révolutionner la surveillance de la santé, la prise en charge des personnes âgées, la rééducation et les maisons intelligentes. Cet article présente HybridHAR, un nouveau modèle conçu pour interpréter ces signaux avec plus de précision et d'efficacité, nous rapprochant d'appareils portables capables de comprendre en temps réel ce que nous faisons.
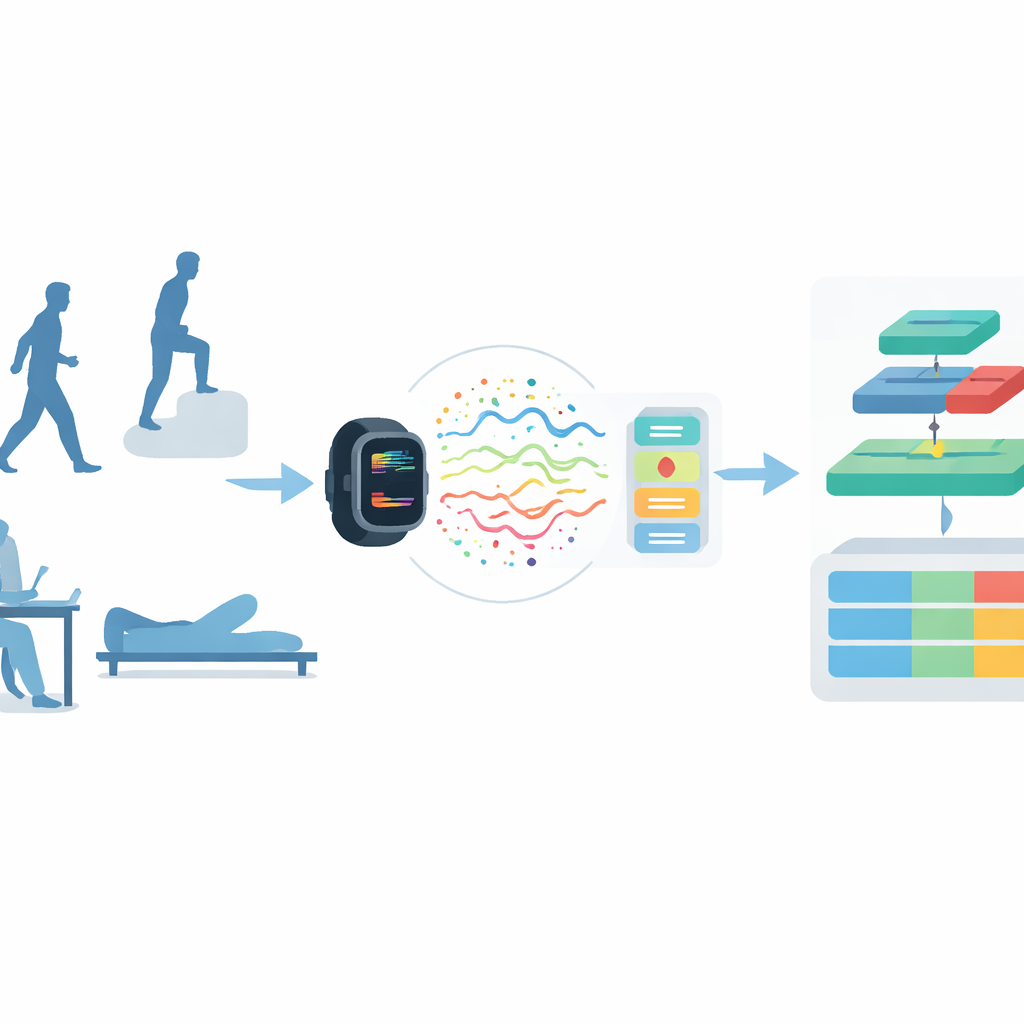
Comprendre l'activité à partir des capteurs de mouvement
La reconnaissance d'activité humaine consiste à déterminer ce qu'une personne fait à partir de capteurs tels que les accéléromètres et gyroscopes présents dans les smartphones et objets portables. Les systèmes antérieurs reposaient sur des experts qui extrayaient manuellement des caractéristiques de ces signaux, ensuite traitées par des algorithmes d'apprentissage automatique traditionnels. Cette approche fonctionnait en laboratoire contrôlé mais échouait souvent dans le monde réel, plus chaotique, où les mouvements sont plus variés et bruités. L'apprentissage profond a amélioré la situation en découvrant automatiquement des motifs dans les données, mais les architectures courantes passent encore à côté de détails importants qui se manifestent à différentes échelles temporelles et peuvent perdre de l'information à mesure que les réseaux s'approfondissent.
Pourquoi les modèles profonds actuels peinent encore
Les mouvements humains se déroulent simultanément sur de nombreuses échelles de temps : un pas rapide, une courte traversée de pièce ou une longue période assise. Beaucoup de modèles d'apprentissage profond se concentrent soit sur de courts fragments, soit sur des plages plus longues, mais pas les deux à la fois. En ajoutant des couches pour capturer des motifs complexes, les réseaux peuvent subir un affaiblissement des signaux d'apprentissage, empêchant les premières couches de progresser. Certains modèles manquent aussi de guidage pour leurs couches internes, qui n'apprennent donc pas forcément des blocs intermédiaires utiles pour distinguer des activités qui se ressemblent au niveau des signaux bruts, comme s'asseoir et se tenir debout.
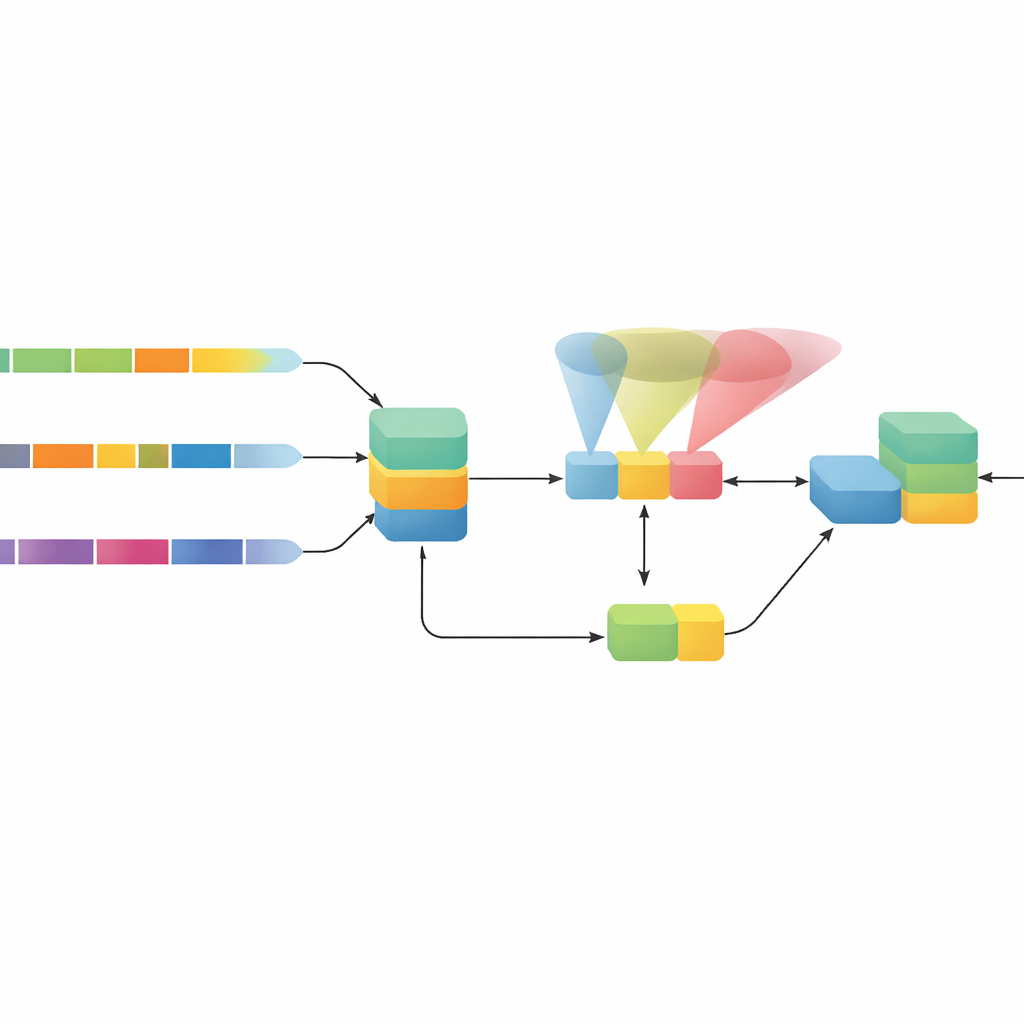
Une architecture hybride qui analyse le mouvement sous plusieurs angles
Les auteurs proposent HybridHAR, un modèle conçu pour corriger ces faiblesses en combinant trois idées principales. D'abord, au lieu d'utiliser une seule fenêtre temporelle, il fait passer le même signal capteur à travers trois voies de traitement parallèles, chacune observant des échelles temporelles différentes — des segments très courts à des segments plus longs. Ces voies agissent comme trois jeux de lentilles, capturant à la fois les détails fins des gestes rapides et les tendances plus lentes de la posture et du déplacement. Leurs sorties sont ensuite fusionnées en une représentation riche qui préserve l'information provenant de toutes ces échelles.
Attirer l'attention et guider l'apprentissage au cœur du modèle
Ensuite, HybridHAR ajoute un module d'attention spécialisé au sommet de cette représentation fusionnée. Ce mécanisme apprend à mettre en valeur les parties les plus informatives du signal — par exemple, les différences subtiles de mouvement qui distinguent la montée d'escaliers de la descente — tout en conservant un chemin de raccourci qui préserve l'information originale. Ce raccourci « résiduel » facilite la circulation des signaux d'apprentissage à travers le réseau, empêchant l'information d'être diluée dans les couches profondes. Enfin, le modèle reçoit un classifieur auxiliaire qui exploite des caractéristiques intermédiaires avant application de l'attention. Pendant l'entraînement, cette sortie supplémentaire est également évaluée, contraignant doucement les couches précoces à apprendre des représentations déjà suffisamment bonnes pour deviner l'activité, ce qui stabilise et accélère l'apprentissage.
Performances de la nouvelle approche
Pour évaluer HybridHAR, les chercheurs ont utilisé un jeu de données public largement adopté où des volontaires portaient un smartphone en réalisant six activités de base : trois types de marche ainsi que s'asseoir, se tenir debout et être allongé. Sur ce benchmark, HybridHAR a atteint environ 99 % de précision sur les données de validation retenues et 96 % sur un jeu de test inédit, surpassant plusieurs alternatives robustes, y compris des réseaux convolutionnels classiques, des réseaux récurrents, des modèles hybrides et des approches reposant sur l'apprentissage par renforcement. Il s'est montré particulièrement performant pour distinguer des activités de marche proches et a réduit les confusions entre paires souvent problématiques comme monter et descendre des escaliers. L'équipe a aussi démontré que chacun des trois ingrédients — voies multi‑échelles, attention et supervision profonde — améliorait les résultats de manière mesurable, et que le modèle complet dépassait toute variante privée de l'un d'eux.
Pourquoi c'est important pour les appareils du monde réel
Malgré sa haute précision, HybridHAR reste compact et rapide, avec bien moins d'hyperparamètres que de nombreux modèles concurrents et la capacité de traiter des centaines de fenêtres d'activité par seconde tout en consommant environ un mégaoctet de mémoire. Il s'est également bien généralisé à un second jeu de données plus complexe, avec davantage d'activités et des capteurs plus riches, où ses performances étaient encore meilleures. Pour les non‑spécialistes, l'essentiel est que cette architecture offre une feuille de route pratique pour transformer des signaux portables bruyants en descriptions fines et fiables des activités humaines. De tels modèles pourraient rendre les futurs moniteurs de santé, maisons intelligentes et systèmes de sécurité à la fois plus fiables et plus faciles à exécuter sur des appareils du quotidien.
Citation: Huo, Y., Wei, C., Xu, Z. et al. Integrating multi-scale convolution and attention mechanisms in HybridHAR for high-performance human activity recognition. Sci Rep 16, 10143 (2026). https://doi.org/10.1038/s41598-026-40904-w
Mots-clés: reconnaissance d'activité humaine, capteurs portables, apprentissage profond, mécanismes d'attention, surveillance de la santé