Clear Sky Science · it
Un framework di deep learning basato su switching per raccomandazioni e‑commerce personalizzate e adattive
Perché suggerimenti online più intelligenti contano
Ogni volta che fai acquisti online, dietro le quinte un algoritmo prova a indovinare cosa potresti voler vedere dopo. Tuttavia le persone usano i siti di shopping in modi molto diversi: alcuni sono appena arrivati, altri navigano per curiosità e altri ancora sono clienti abituali. Questo articolo presenta un nuovo framework di raccomandazione che si adatta in tempo reale a queste differenze, con l’obiettivo di rendere i suggerimenti di prodotto più precisi, equi e utili per tutti — dai visitatori alle prime armi agli acquirenti più assidui.
Tre tipi di acquirenti, non uno solo
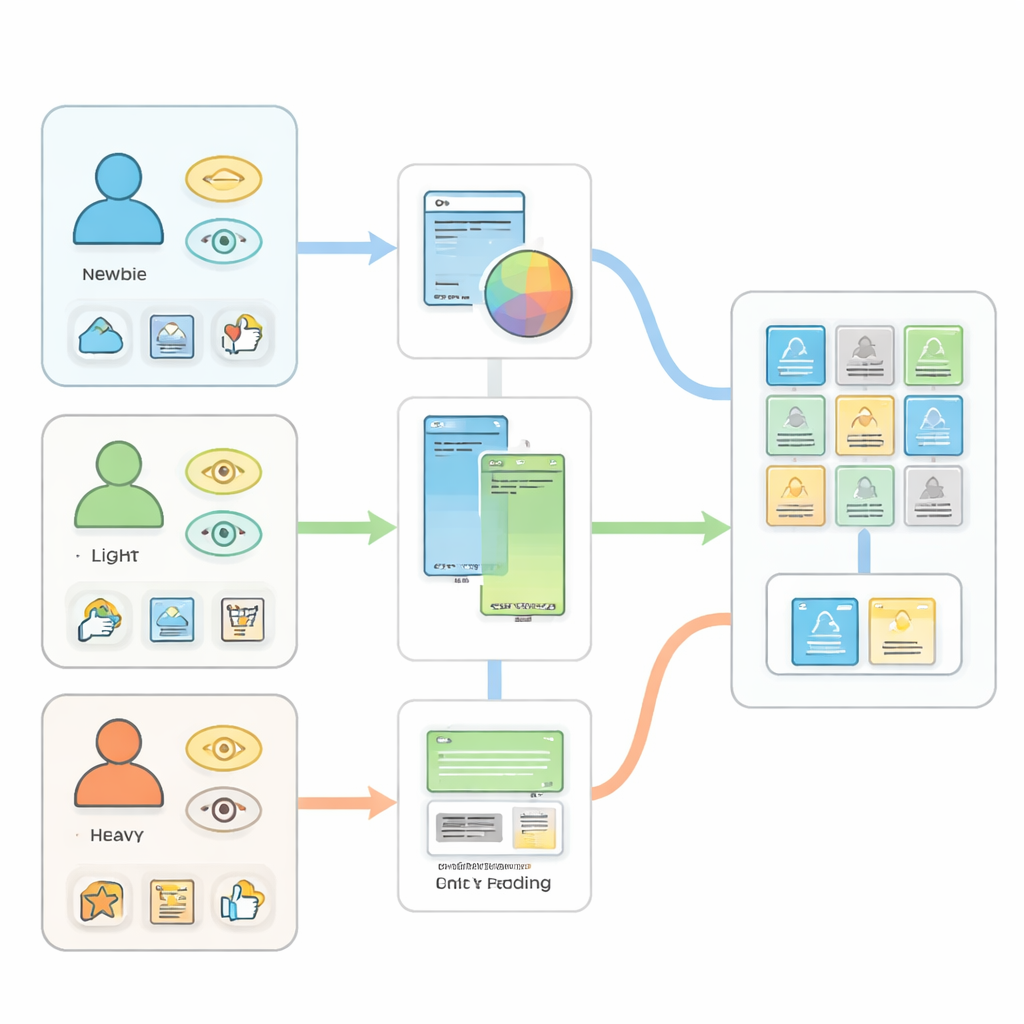
Gli autori iniziano sostenendo che trattare tutti gli utenti allo stesso modo porta a raccomandazioni deboli. Suddividono gli acquirenti in tre gruppi ampi basati sul livello di interazione con il sito. I “novizi” hanno quasi nessuna storia, forse solo qualche ricerca o clic. Gli “utenti leggeri” hanno fatto un numero limitato di visite o acquisti. Gli “utenti intensi” lasciano una lunga traccia di visualizzazioni, clic, aggiunte al carrello, valutazioni e ordini. Ciascun gruppo genera tipi e quantità di dati diversi, perciò un algoritmo unico fatica a servirli tutti in modo altrettanto efficace.
Aiutare i nuovi visitatori con immagini e descrizioni
Per gli utenti appena arrivati, il trucco abituale — cercare schemi nel loro comportamento passato — semplicemente non funziona perché non esiste una storia. Il sistema proposto affronta questo problema del “cold start” facendo leva sui prodotti stessi. Usa una rete neurale che impara sia dalle immagini dei prodotti sia dai loro dettagli scritti, come titolo, marca, categoria e prezzo. Queste diverse informazioni vengono combinate in una rappresentazione numerica condivisa, così che prodotti con aspetto e descrizioni simili risultino vicini in questo spazio astratto. Quando un nuovo visitatore digita una semplice query o clicca alcuni elementi, il sistema mappa queste azioni nello stesso spazio e restituisce prodotti vicini, indovinando il gusto più dall’aspetto e dal testo che dalle abitudini a lungo termine.
Servire gli acquirenti occasionali con matching leggero
Gli utenti leggeri forniscono alcuni indizi diretti — come un piccolo numero di visualizzazioni o acquisti passati — ma comunque non abbastanza per metodi molto complessi. Per questo gruppo, il framework utilizza un modello "two‑tower" snello. Una torre riassume chi è l’utente e cosa ha fatto finora; l’altra riassume le caratteristiche dei prodotti. Durante l’addestramento, il sistema impara ad avvicinare la rappresentazione dell’utente agli oggetti con cui ha interagito e ad allontanarla dagli altri. Questo design permette di scandagliare rapidamente grandi cataloghi per selezionare una rosa ristretta di elementi promettenti. I test mostrano che, dopo l’addestramento, la probabilità che l’elemento corretto compaia tra le prime 10 proposte circa raddoppia e la qualità del ranking migliora sostanzialmente rispetto a una versione non addestrata.
Potenziare gli utenti intensi con molti segnali insieme
Gli utenti intensi lasciano tracce ricche: cosa visualizzano, cosa comprano, come valutano gli articoli e altro ancora. Invece di concentrarsi su un solo di questi comportamenti, gli autori costruiscono un modello multi‑task che impara a gestire più obiettivi contemporaneamente. Un nucleo condiviso rappresenta sia utenti sia prodotti; sopra questo, un ramo predice le valutazioni mentre un altro predice quali articoli un utente è probabile che scelga dopo. Addestrare entrambi i compiti insieme permette a segnali abbondanti ma rumorosi, come le visualizzazioni dei prodotti, di rafforzare l’apprendimento per segnali più rari ma più informativi come le valutazioni. Gli esperimenti mostrano che i modelli ottimizzati solo per le valutazioni o solo per il recupero funzionano bene sul loro singolo obiettivo ma male sull’altro, mentre il modello congiunto raggiunge un equilibrio complessivo migliore.
Accendere lo strumento giusto al momento giusto
L’idea chiave che lega insieme queste parti è un meccanismo di switching che sceglie il modello più adatto in base al livello di coinvolgimento attuale di ciascuna persona. Man mano che qualcuno passa da visitatore nuovo a acquirente occasionale a cliente frequente, il sistema monitora i cambiamenti di attività e instrada automaticamente i loro dati attraverso il modulo più idoneo. Su tutti e tre i gruppi, questo design adattivo riduce gli errori di previsione, aumenta i tassi di successo e sfrutta meglio i numerosi segnali deboli che le piattaforme moderne raccolgono. In termini pratici, significa che la tua lista “Consigliati per te” può restare rilevante sia che tu sia appena arrivato sia che faccia acquisti sul sito da anni, senza che le esigenze di un gruppo sovrastino quelle di un altro.
Citazione: Saini, K., Singh, A., Diwakar, M. et al. A switching-based deep learning framework for personalized and adaptive E-commerce recommendations. Sci Rep 16, 10382 (2026). https://doi.org/10.1038/s41598-026-40024-5
Parole chiave: raccomandazioni e‑commerce, shopping personalizzato, deep learning, comportamento dell'utente, sistemi di raccomandazione