Clear Sky Science · de
Ein auf Umschaltung basierendes Deep‑Learning‑Framework für personalisierte und adaptive E‑Commerce‑Empfehlungen
Warum schlauere Online‑Vorschläge wichtig sind
Jedes Mal, wenn Sie online einkaufen, rät im Hintergrund ein Algorithmus, was Sie als Nächstes sehen möchten. Nutzer verwenden Shopping‑Seiten jedoch sehr unterschiedlich: manche sind gerade erst angekommen, andere stöbern gelegentlich, und wieder andere sind treue Stammkunden. Dieser Beitrag stellt ein neues Empfehlungs‑Framework vor, das sich in Echtzeit an diese Unterschiede anpasst und darauf abzielt, Produktempfehlungen genauer, fairer und nützlicher für alle zu machen – vom Erstbesucher bis zum Vielkäufer.
Drei Arten von Einkaufsverhalten, nicht nur eine
Die Autoren argumentieren zunächst, dass die Gleichbehandlung aller Nutzer zu schwachen Empfehlungen führt. Sie teilen Käufer in drei grobe Gruppen ein, basierend darauf, wie stark sie mit der Seite interagieren. „Neulinge“ haben so gut wie keine Historie, vielleicht nur ein paar Suchen oder Klicks. „Gelegenheitsnutzer“ haben ein paar Besuche oder Käufe getätigt. „Stammkunden“ hinterlassen eine lange Spur aus Ansichten, Klicks, Warenkorb‑Hinzufügungen, Bewertungen und Bestellungen. Jede Gruppe erzeugt unterschiedliche Arten und Mengen an Daten, sodass ein Einheitsalgorithmus Schwierigkeiten hat, allen gleichermaßen gut zu dienen.
Neuen Besuchern mit Bildern und Beschreibungen helfen
Bei völlig neuen Nutzern funktioniert der übliche Trick – in deren Vergangenheit nach Mustern zu suchen – schlicht nicht, weil keine solche Historie existiert. Das vorgeschlagene System begegnet diesem „Cold‑Start“‑Problem, indem es sich auf die Produkte selbst stützt. Es nutzt ein neuronales Netzwerk, das sowohl aus Produktbildern als auch aus schriftlichen Details lernt, etwa Titel, Marke, Kategorie und Preis. Diese verschiedenen Informationsbausteine werden zu einer gemeinsamen numerischen Repräsentation kombiniert, sodass Produkte mit ähnlichem Aussehen und ähnlichen Beschreibungen in diesem abstrakten Raum nahe beieinander liegen. Wenn ein neuer Besucher eine einfache Suche eingibt oder ein paar Artikel anklickt, bildet das System diese Aktionen in denselben Raum ab und liefert nahegelegene Produkte zurück – es schätzt Geschmack also eher aus Bild und Text als aus langfristigen Gewohnheiten.
Gelegenheitskäufer mit leichtgewichtiger Zuordnung bedienen
Gelegenheitsnutzer liefern einige direkte Hinweise – etwa eine kleine Anzahl von Ansichten oder vergangenen Käufen – aber noch nicht genug für sehr komplexe Methoden. Für diese Gruppe verwendet das Framework ein schlankes „Two‑Tower“‑Modell. Ein Turm fasst zusammen, wer der Nutzer ist und was er bisher getan hat; der andere fasst Produkteigenschaften zusammen. Während des Trainings lernt das System, die Repräsentation des Nutzers näher an die mit ihm interagierten Artikel heranzuziehen und von anderen wegzudrücken. Dieses Design ermöglicht sehr schnelles Durchsuchen großer Kataloge, um eine Kurzliste vielversprechender Artikel zu erstellen. Tests zeigen, dass nach dem Training die Wahrscheinlichkeit, dass das richtige Produkt unter den Top‑10‑Vorschlägen erscheint, sich etwa verdoppelt und die Ranking‑Qualität gegenüber einer untrainierten Version deutlich verbessert.
Stammkunden mit vielen Signalen gleichzeitig versorgen
Stammnutzer hinterlassen reichhaltige Spuren: was sie ansehen, was sie kaufen, wie sie Artikel bewerten und mehr. Anstatt sich nur auf eines dieser Verhaltensmuster zu konzentrieren, bauen die Autoren ein Multi‑Task‑Modell, das lernt, mehrere Ziele gleichzeitig zu verfolgen. Ein gemeinsamer Kern repräsentiert sowohl Nutzer als auch Produkte; darauf aufbauend sagt ein Zweig Bewertungen voraus, während ein anderer vorhersagt, welche Artikel ein Nutzer als Nächstes wählen wird. Das gleichzeitige Training beider Aufgaben erlaubt es, häufige aber laute Signale wie Produktansichten das Lernen für seltenere, aber informativeren Signale wie Bewertungen zu stärken. Experimente zeigen, dass Modelle, die ausschließlich auf Bewertungen oder ausschließlich auf Retrieval abgestimmt sind, zwar in ihrem Einzelziel gut abschneiden, jedoch beim jeweils anderen Ziel schlecht performen, während das gemeinsame Modell insgesamt eine bessere Balance findet.
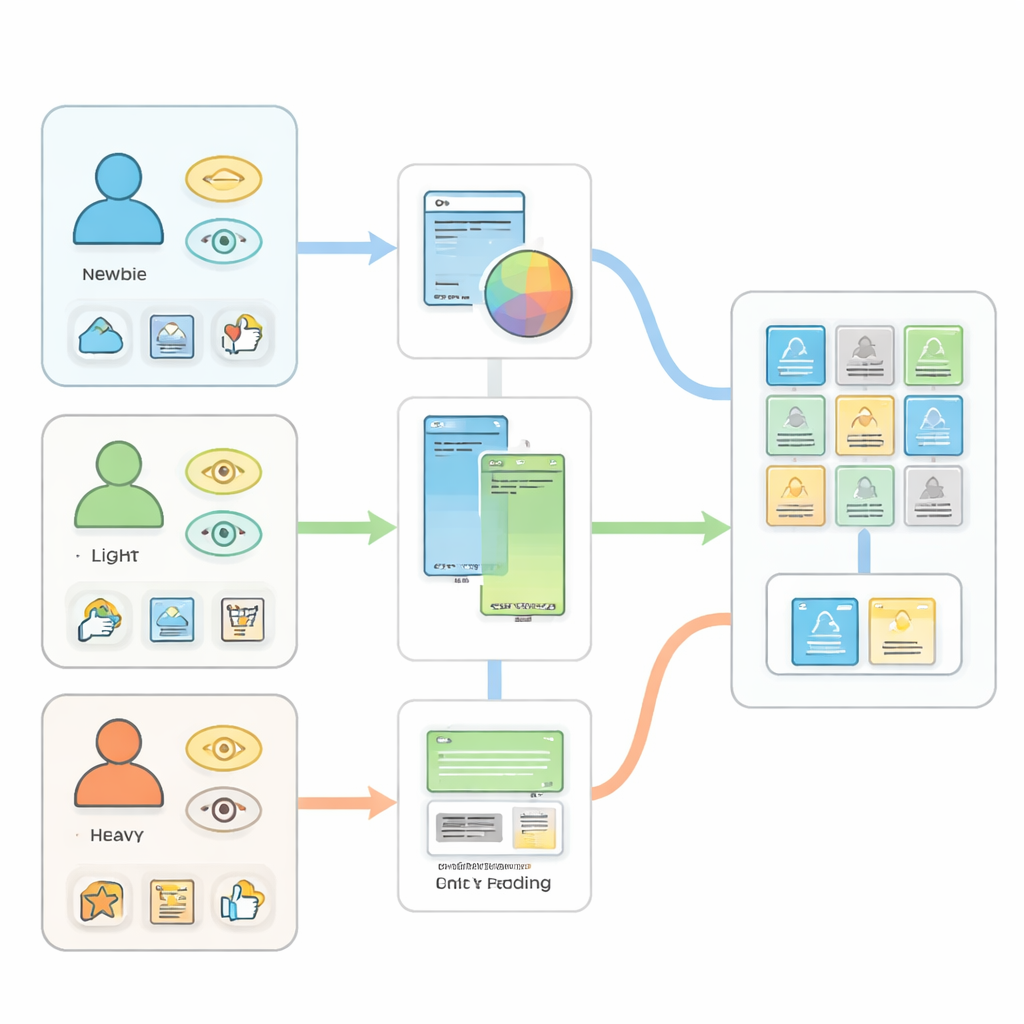
Das richtige Werkzeug zur richtigen Zeit einschalten
Die zentrale Idee, die diese Teile verbindet, ist ein Umschaltmechanismus, der basierend auf dem aktuellen Engagement‑Level jeder Person das passende Modell auswählt. Wenn jemand vom neuen Besucher zum Gelegenheitskäufer und schließlich zum Stammkunden übergeht, verfolgt das System Veränderungen in der Aktivität und leitet die Daten automatisch durch das am besten geeignete Modul. Über alle drei Gruppen hinweg reduziert dieses adaptive Design Vorhersagefehler, erhöht Trefferquoten und nutzt die vielen schwachen Signale, die moderne Plattformen sammeln, besser aus. Einfach gesagt bedeutet das: Ihre „Für Sie empfohlen“‑Liste kann relevant bleiben, unabhängig davon, ob Sie gerade erst angekommen sind oder seit Jahren auf der Seite einkaufen, ohne dass die Bedürfnisse einer Gruppe die einer anderen überlagern.
Zitation: Saini, K., Singh, A., Diwakar, M. et al. A switching-based deep learning framework for personalized and adaptive E-commerce recommendations. Sci Rep 16, 10382 (2026). https://doi.org/10.1038/s41598-026-40024-5
Schlüsselwörter: E‑Commerce‑Empfehlung, personalisierte Einkäufe, Deep Learning, Nutzerverhalten, Empfehlungssysteme