Clear Sky Science · fr
Un cadre d’apprentissage profond basé sur un commutateur pour des recommandations e‑commerce personnalisées et adaptatives
Pourquoi des suggestions en ligne plus intelligentes comptent
Chaque fois que vous faites des achats en ligne, en coulisses un algorithme tente de deviner ce que vous voudriez voir ensuite. Pourtant, les internautes n’utilisent pas les sites de vente de la même façon : certains viennent d’arriver, d’autres parcourent les pages de manière occasionnelle, et d’autres encore sont des clients réguliers assidus. Cet article présente un nouveau cadre de recommandation qui s’adapte en temps réel à ces différences, visant à rendre les suggestions de produits plus précises, plus équitables et plus utiles pour tous — des visiteurs occasionnels aux acheteurs intensifs.
Trois types d’acheteurs, pas un seul
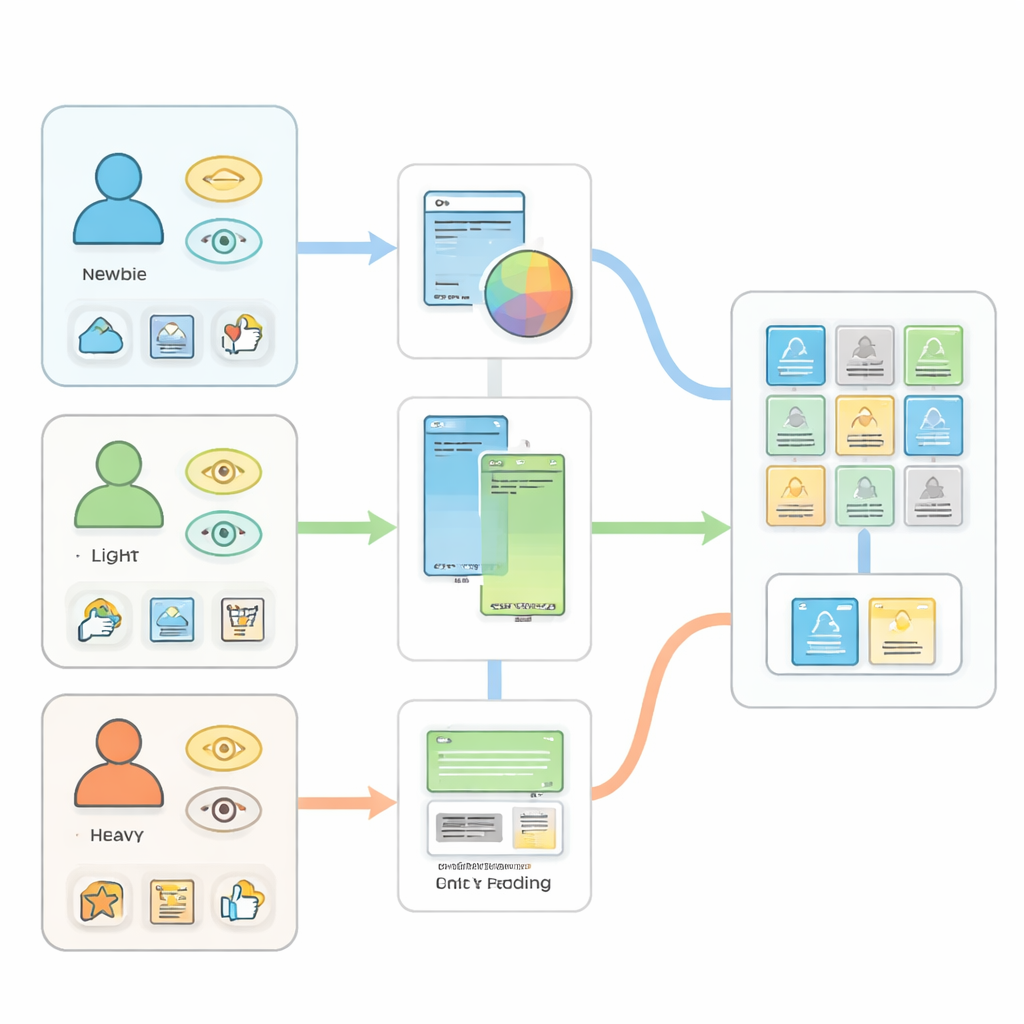
Les auteurs commencent par soutenir que traiter tous les utilisateurs de la même façon conduit à des recommandations médiocres. Ils divisent les acheteurs en trois grandes catégories selon le degré d’interaction avec le site. Les « nouveaux » n’ont presque aucun historique, peut‑être juste quelques recherches ou clics. Les « utilisateurs légers » ont fait quelques visites ou achats. Les « utilisateurs intensifs » ont un long historique de vues, de clics, d’ajouts au panier, d’évaluations et de commandes. Chaque groupe génère des types et des volumes de données différents, de sorte qu’un algorithme unique peine à bien les servir tous.
Aider les nouveaux visiteurs avec images et descriptions
Pour les utilisateurs tout juste arrivés, l’astuce habituelle — chercher des motifs dans leur comportement passé — ne fonctionne pas car il n’existe pas d’historique. Le système proposé s’attaque à ce problème de « cold start » en s’appuyant sur les produits eux‑mêmes. Il utilise un réseau neuronal qui apprend à partir des images des produits et de leurs descriptions écrites, comme le titre, la marque, la catégorie et le prix. Ces différents éléments d’information sont combinés en une représentation numérique partagée, de sorte que des produits ayant un aspect et des descriptions similaires se retrouvent proches dans cet espace abstrait. Lorsqu’un nouveau visiteur tape une requête simple ou clique sur quelques articles, le système projette ces actions dans le même espace et renvoie des produits à proximité, devinant ainsi les goûts à partir de l’apparence et du texte plutôt que d’habitudes à long terme.
Servir les acheteurs occasionnels avec un appariement léger
Les utilisateurs légers fournissent quelques indices directs — comme un petit nombre de vues ou d’achats passés — mais pas suffisamment pour des méthodes très complexes. Pour ce groupe, le cadre utilise un modèle « two‑tower » simplifié. Une tour résume qui est l’utilisateur et ce qu’il a fait jusqu’à présent ; l’autre résume les caractéristiques des produits. Pendant l’entraînement, le système apprend à rapprocher la représentation de l’utilisateur des articles avec lesquels il a interagi et à l’éloigner des autres. Cette conception permet un balayage très rapide à travers de larges catalogues pour constituer une liste restreinte d’articles prometteurs. Les tests montrent qu’après apprentissage, la probabilité que l’article correct figure parmi les 10 premières suggestions double à peu près, et la qualité du classement s’améliore sensiblement par rapport à une version non entraînée.
Alimenter les utilisateurs intensifs avec de nombreux signaux simultanés
Les utilisateurs intensifs laissent des traces riches : ce qu’ils voient, ce qu’ils achètent, comment ils évaluent les articles, et plus encore. Plutôt que de se concentrer sur un seul de ces comportements, les auteurs construisent un modèle multi‑tâches qui apprend à gérer plusieurs objectifs en même temps. Un noyau partagé représente à la fois les utilisateurs et les produits ; au‑dessus de celui‑ci, une branche prédit les évaluations tandis qu’une autre prédit quels articles un utilisateur est susceptible de choisir ensuite. En entraînant les deux tâches conjointement, les signaux abondants mais bruités comme les vues de produit peuvent renforcer l’apprentissage pour des signaux plus rares mais plus informatifs comme les évaluations. Les expériences montrent que des modèles réglés uniquement pour les évaluations ou uniquement pour la recherche d’articles obtiennent de bonnes performances sur leur objectif unique mais échouent sur l’autre, tandis que le modèle conjoint trouve un meilleur compromis global.
Activer le bon outil au bon moment
L’idée clé qui relie ces parties est un mécanisme de commutation qui choisit le modèle approprié en fonction du niveau d’engagement actuel de chaque personne. Lorsque quelqu’un passe de visiteur nouveau à acheteur occasionnel puis à client fréquent, le système suit les changements d’activité et dirige automatiquement ses données vers le module le plus adapté. À travers les trois groupes, ce dispositif adaptatif réduit les erreurs de prédiction, augmente les taux de réussite et met mieux à profit les nombreux signaux faibles que collectent les plateformes modernes. Concrètement, cela signifie que votre liste « Recommandé pour vous » peut rester pertinente que vous veniez d’arriver ou que vous fassiez des achats sur le site depuis des années, sans que les besoins d’un groupe n’écrasent ceux d’un autre.
Citation: Saini, K., Singh, A., Diwakar, M. et al. A switching-based deep learning framework for personalized and adaptive E-commerce recommendations. Sci Rep 16, 10382 (2026). https://doi.org/10.1038/s41598-026-40024-5
Mots-clés: recommandation e‑commerce, shopping personnalisé, apprentissage profond, comportement utilisateur, systèmes de recommandation