Clear Sky Science · it
Studio sulla creazione di un database per le patologie interventistiche cardiovascolari e sulla predizione del rischio di mortalità postoperatoria
Perché questo è importante per pazienti e famiglie
Le procedure cardiovascolari possono salvare vite, ma comportano anche rischi concreti, soprattutto per i pazienti più anziani o con comorbilità. Una delle domande principali dopo un intervento è: “Quali sono le probabilità che io o una persona cara possiamo morire nei mesi successivi all’operazione?” Questo studio mostra come dati ospedalieri accuratamente organizzati e un moderno modello di intelligenza artificiale (IA) possano aiutare i medici a stimare quel rischio con maggiore precisione, così da monitorare più attentamente i pazienti vulnerabili e intervenire prima quando emergono segnali di allarme.
Da cartelle sparse a una storia completa del paziente
Tradizionalmente, le informazioni sui pazienti cardiaci sono disperse in molti sistemi ospedalieri: referti di laboratorio in un luogo, immagini in un altro, e note di follow-up altrove. Gran parte è scritta in testo libero e non standardizzata, il che rende difficile per i computer e persino per i medici avere una visione d’insieme. I ricercatori hanno affrontato questo problema costruendo un database dedicato alle procedure interventistiche cardiovascolari in un grande ospedale della provincia di Zhejiang, in Cina. In un anno hanno raccolto dati dettagliati e strutturati da 728 pazienti sottoposti a procedure cardiache minimamente invasive, concentrandosi infine su 638 casi con informazioni complete dall’ammissione fino a sei mesi dopo l’intervento. Questa visione “full-cycle” cattura chi sono i pazienti, cosa accade prima e durante la procedura e come si recuperano dopo.
Cosa contiene il database del rischio cardiaco
Il database integra informazioni provenienti da più sistemi ospedalieri, come cartelle cliniche elettroniche, sistemi di laboratorio, piattaforme di imaging e ambulatori di follow-up. Il team ha raggruppato i dati in quattro blocchi principali: dettagli di base del paziente e anamnesi; esami e indagini preoperatorie; ciò che è effettivamente accaduto durante la procedura; e indicatori di follow-up come segni vitali, esami del sangue e punteggi di autonomia nelle attività quotidiane. Hanno quindi pulito i dati—rimuovendo campi con troppi valori mancanti, colmando piccole lacune in modo sensato e convertendo categorie testuali (per esempio fumatore o non fumatore, emorragia o non emorragia) in codici numerici analizzabili dai computer. Hanno inoltre sintetizzato più patologie pregresse in un unico punteggio di comorbidità, per rappresentare più agevolmente il carico complessivo di malattia di ciascun paziente.
Addestrare un modello IA a riconoscere segnali di allarme precoci
Con i dati ordinati, i ricercatori si sono posti una domanda mirata: basandosi su tutte queste informazioni, possiamo prevedere chi morirà entro sei mesi dall’intervento? Solo 41 dei 638 pazienti sono deceduti in quel periodo, il che rende il problema di predizione particolarmente difficile—ci sono molti più sopravvissuti che decessi, e molti modelli tendono a trascurare i casi rari ma critici ad alto rischio. Il team ha prima applicato un metodo di selezione delle caratteristiche per scegliere 30 delle variabili più informative lungo l’intero percorso del paziente. Tra queste figurano fattori come età, indice di massa corporea, carico di comorbilità, alcuni risultati di esami del sangue, dettagli dell’operazione come la durata dell’impiego degli strumenti, e misure di follow-up come funzionalità renale e epatica e capacità nelle attività quotidiane.
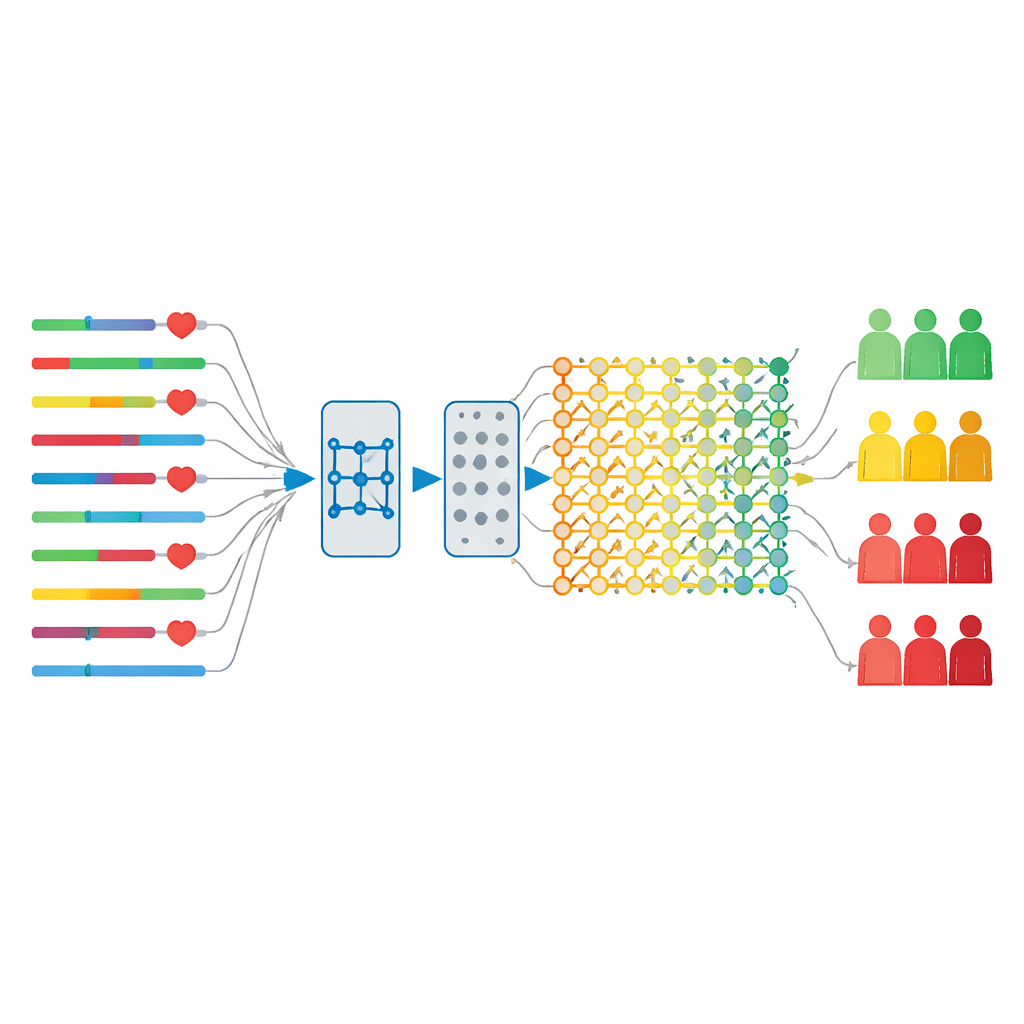
Un motore IA ibrido progettato per velocità e accuratezza
Per analizzare questi dati temporali, i ricercatori hanno progettato un modello ibrido che combina due tecniche di IA. La prima, nota come rete a memoria a lungo termine (LSTM), è efficace nel tracciare pattern nel tempo—ad esempio come variano nel tempo i valori di laboratorio prima e dopo l’intervento—ma può diventare lenta e incline all’overfitting se usata da sola. La seconda, chiamata sistema di apprendimento broad, costruisce rapidamente connessioni tra le caratteristiche senza il pesante aggiustamento dei pesi tipico delle reti profonde. Nel loro progetto, i dati del ciclo vitale del paziente passano prima attraverso la componente sensibile al tempo del modello, poi attraverso uno stadio di regolarizzazione per ridurre l’overfitting, e infine nello strato broad learning che calcola rapidamente la predizione finale. Questa struttura conserva i punti di forza del deep learning riducendone i limiti.
Cosa significano i risultati per la pratica clinica
Confrontando il loro modello ibrido con tre approcci neurali comuni, il nuovo design ha mostrato prestazioni nettamente migliori. Ha classificato correttamente i pazienti in circa l’87% dei casi e, cosa importante, ha identificato oltre il 93% di coloro che effettivamente sono deceduti entro sei mesi—un vantaggio chiave quando l’obiettivo è non perdere i soggetti ad alto rischio. In termini pratici, questo significa che organizzando i dati ospedalieri in un database dedicato alle procedure cardiache e analizzandoli con un modello IA su misura, i medici possono ottenere un avviso precoce più affidabile su quali pazienti necessitano di maggiore attenzione dopo l’intervento. Sebbene lo studio provenga da un singolo ospedale e debba ancora essere testato in altri centri, indica una direzione in cui un uso più intelligente dei dati e strumenti predittivi specializzati possono rendere le procedure cardiache più sicure e il recupero più protetto.
Citazione: Qi, P., Hu, C., Li, Y. et al. Study on establishment of cardiovascular interventional disease database and prediction of postoperative mortality risk. Sci Rep 16, 12493 (2026). https://doi.org/10.1038/s41598-026-39788-7
Parole chiave: intervento cardiovascolare, rischio postoperatorio, predizione della mortalità, database medici, intelligenza artificiale in sanità