Clear Sky Science · fr
Étude sur la mise en place d’une base de données des interventions cardiovasculaires et la prédiction du risque de mortalité postopératoire
Pourquoi cela compte pour les patients et leurs proches
Les procédures cardiovasculaires peuvent sauver des vies, mais elles comportent aussi des risques réels, en particulier pour les patients âgés ou fragiles. L’une des questions majeures après une intervention est : « Quelles sont les chances que moi ou un proche décède dans les mois qui suivent l’opération ? » Cette étude montre comment des données hospitalières bien organisées et un modèle d’intelligence artificielle (IA) moderne peuvent aider les médecins à estimer ce risque avec plus de précision, afin de surveiller de près les patients vulnérables et d’intervenir plus tôt lorsque des signes de complication apparaissent.
De dossiers éclatés à une histoire complète du patient
Traditionnellement, les informations sur les patients cardiaques sont dispersées dans de nombreux systèmes hospitaliers — résultats de laboratoire ici, imagerie là, comptes rendus de suivi ailleurs. Une grande partie est rédigée en texte libre et non standardisée, ce qui rend difficile pour les ordinateurs et même pour les cliniciens de voir l’ensemble du tableau. Les chercheurs ont abordé ce problème en construisant une base de données dédiée aux interventions cardiovasculaires dans un grand hôpital de la province du Zhejiang, en Chine. Sur un an, ils ont recueilli des données détaillées et structurées de 728 patients ayant subi des procédures cardiaques peu invasives, pour finalement se concentrer sur 638 cas disposant d’informations complètes depuis l’admission jusqu’à six mois après l’intervention. Cette vue « cycle complet » retrace qui sont les patients, ce qui se passe avant et pendant l’intervention, et comment ils récupèrent ensuite.
Ce qui alimente la base de données de risque cardiaque
La base de données agrège des informations provenant de plusieurs systèmes hospitaliers, tels que le dossier médical électronique, les systèmes de laboratoire, les plateformes d’imagerie et les cliniques de suivi. L’équipe a regroupé les données en quatre blocs principaux : informations de base et antécédents médicaux ; examens et imageries réalisés avant l’opération ; déroulé de l’intervention ; et indicateurs de suivi comme les constantes, les analyses sanguines et les scores d’autonomie. Ils ont ensuite nettoyé les données — supprimant les champs trop incomplets, comblant les petites lacunes de manière raisonnée et convertissant des catégories textuelles (par exemple fumeur ou non, saignement ou non) en codes numériques exploitables par des ordinateurs. Ils ont aussi résumé les maladies existantes en un score unique de comorbidité, afin de mieux refléter le fardeau global de chaque patient.
Apprendre à un modèle d’IA à repérer tôt les signes d’alerte
Avec les données organisées, les chercheurs ont posé une question précise : à partir de toutes ces informations, peut-on prédire qui décédera dans les six mois suivant l’intervention ? Seuls 41 des 638 patients sont décédés dans cette période, ce qui rend la tâche particulièrement délicate — il y a beaucoup plus de survivants que de décès, et de nombreux modèles ont tendance à négliger ces cas rares mais cruciaux à haut risque. L’équipe a d’abord utilisé une méthode de sélection de variables pour retenir 30 des paramètres les plus informatifs couvrant le parcours complet du patient. Ceux-ci incluaient des facteurs tels que l’âge, l’indice de masse corporelle, la charge de comorbidité, certains résultats sanguins, des détails opératoires comme la durée d’utilisation des instruments, et des mesures de suivi comme la fonction rénale et hépatique ou le niveau d’autonomie.
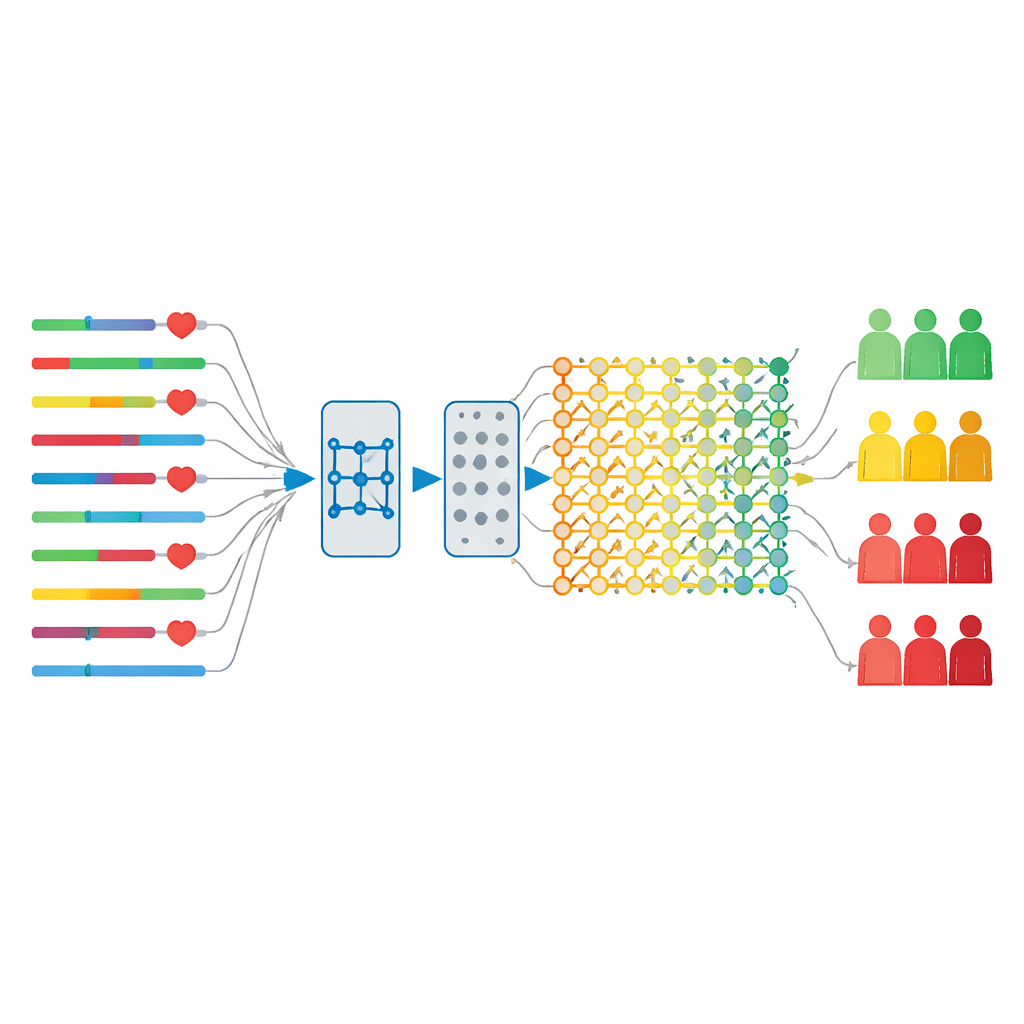
Un moteur d’IA hybride conçu pour la rapidité et la précision
Pour analyser ces données temporelles, les chercheurs ont conçu un modèle hybride combinant deux techniques d’IA. La première, connue sous le nom de réseau à mémoire à long terme (LSTM), excelle à suivre des motifs au fil du temps — par exemple l’évolution des paramètres biologiques avant et après l’intervention — mais peut devenir lent et sujet au surapprentissage si utilisé seul. La seconde, appelée système d’apprentissage large (broad learning system), construit rapidement des connexions entre les caractéristiques sans le réglage lourd des poids typique des réseaux profonds. Dans leur architecture, les données du cycle de vie du patient passent d’abord par la partie sensible au temps du modèle, puis par une étape de régularisation pour réduire le surapprentissage, et enfin par la couche d’apprentissage large qui calcule rapidement la prédiction finale. Cette structure conserve les avantages de l’apprentissage profond tout en atténuant ses faiblesses.
Ce que les résultats impliquent pour la pratique clinique
Quand ils ont comparé leur modèle hybride à trois approches neuronales courantes, la nouvelle architecture s’est montrée la plus performante. Elle a correctement classé les patients dans environ 87 % des cas et, fait important, a identifié plus de 93 % de ceux qui sont effectivement décédés dans les six mois — un atout clé quand l’objectif est de ne pas manquer les individus à haut risque. En termes pratiques, cela signifie qu’en organisant les données hospitalières dans une base dédiée aux interventions cardiaques et en les analysant avec un modèle d’IA adapté, les médecins peuvent obtenir un signal d’alerte plus fiable sur les patients nécessitant une attention renforcée après l’intervention. Bien que l’étude provienne d’un seul établissement et doive encore être validée dans d’autres centres, elle ouvre la voie à un avenir où une utilisation plus intelligente des données et des outils de prédiction spécialisés contribuent à rendre les interventions cardiaques plus sûres et la convalescence plus sécurisée.
Citation: Qi, P., Hu, C., Li, Y. et al. Study on establishment of cardiovascular interventional disease database and prediction of postoperative mortality risk. Sci Rep 16, 12493 (2026). https://doi.org/10.1038/s41598-026-39788-7
Mots-clés: intervention cardiovasculaire, risque postopératoire, prédiction de mortalité, bases de données médicales, intelligence artificielle en santé