Clear Sky Science · de
Studie zum Aufbau einer Datenbank für kardiovaskuläre interventionelle Erkrankungen und zur Vorhersage des postoperativen Sterblichkeitsrisikos
Warum das für Patientinnen, Patienten und Familien wichtig ist
Kardiovaskuläre Eingriffe können Leben retten, bergen aber auch reale Risiken, insbesondere für ältere und schwer erkrankte Personen. Eine der wichtigsten Fragen nach einer Intervention lautet: „Wie groß ist die Wahrscheinlichkeit, dass ich oder ein Angehöriger in den Monaten nach der Operation sterben könnte?“ Diese Studie zeigt, wie sorgfältig strukturierte Krankenhausdaten und ein modernes KI‑Modell Ärzten helfen können, dieses Risiko genauer abzuschätzen, damit sie gefährdete Patienten enger überwachen und früher eingreifen können, wenn sich Komplikationen abzeichnen.
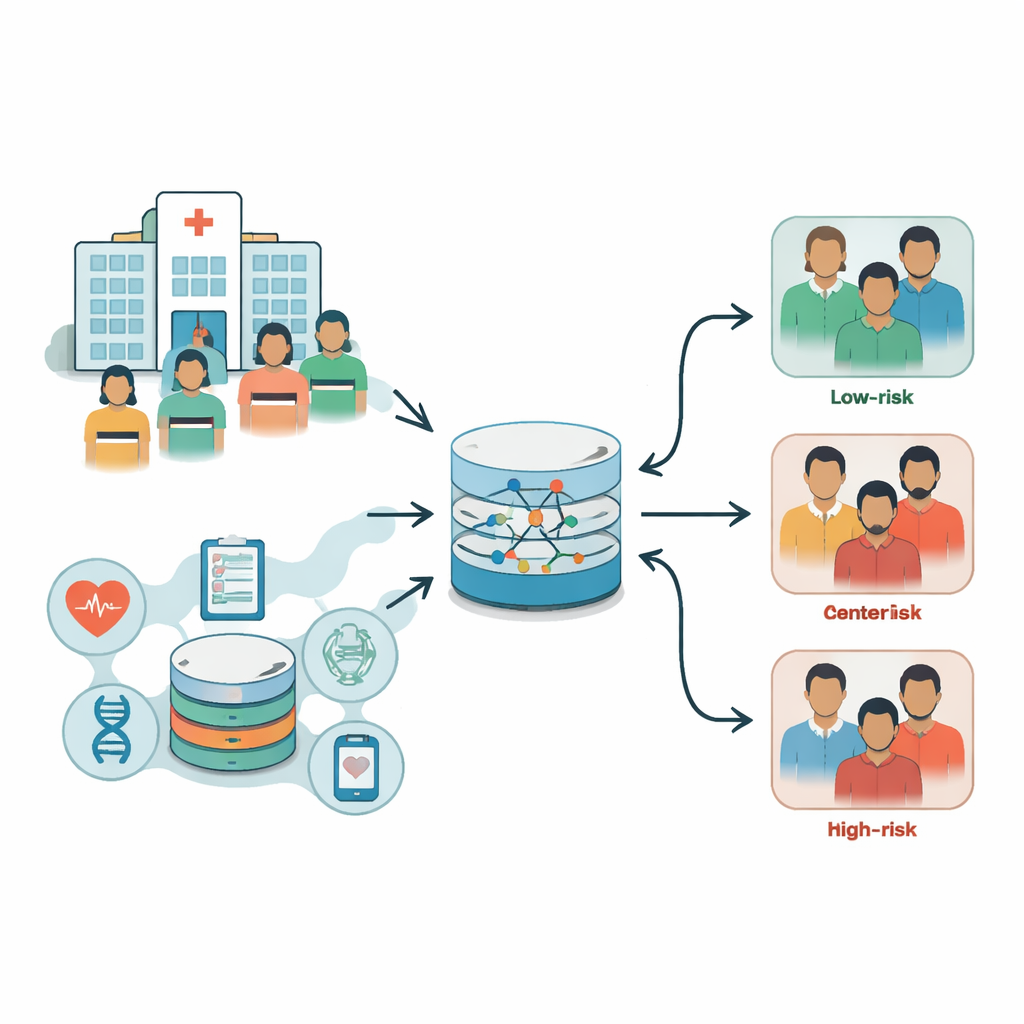
Von verstreuten Akten zur vollständigen Patientenakte
Traditionell sind Informationen zu Herzpatienten über viele Krankenhaus‑Systeme verteilt – Laborbefunde an einer Stelle, Bildgebung an einer anderen und Anschlussdokumentation woanders. Ein Großteil liegt als Freitext vor und ist nicht standardisiert, was es für Computer und sogar für Ärztinnen und Ärzte schwierig macht, das Gesamtbild zu erfassen. Die Forschenden sind diesem Problem begegnet, indem sie in einem großen Krankenhaus in der Provinz Zhejiang, China, eine eigene Datenbank speziell für kardiovaskuläre Interventionen aufgebaut haben. Innerhalb eines Jahres sammelten sie detaillierte, strukturierte Daten von 728 Patientinnen und Patienten, die minimalinvasive Herzverfahren durchlaufen hatten, und konzentrierten sich schließlich auf 638 Fälle mit vollständigen Informationen von der Aufnahme bis sechs Monate nach dem Eingriff. Diese „Full‑Cycle“-Sicht erfasst, wer die Patientinnen und Patienten sind, was vor und während des Eingriffs geschieht und wie sich ihre Erholung gestaltet.
Was in die Herzrisikodatenbank einfließt
Die Datenbank zieht Informationen aus mehreren Krankenhaus‑Systemen, etwa der elektronischen Patientenakte, Laborsystemen, Bildgebungslösungen und Nachsorge‑Ambulanzen. Das Team fasste die Daten in vier Hauptblöcke zusammen: Basisdaten und Krankengeschichte; Untersuchungen und Scans vor der Operation; das tatsächliche Procedere während des Eingriffs; und Nachsorge‑Indikatoren wie Vitalwerte, Blutwerte und Fähigkeiten zur Alltagsbewältigung. Anschließend bereinigten sie die Daten – entfernten Felder mit zu vielen fehlenden Werten, füllten kleine Lücken sinnvoll auf und wandelten Textkategorien (etwa Raucher/Nichtraucher, Blutung ja/nein) in numerische Codes um, die Computer analysieren können. Zudem fassten sie mehrere bestehende Erkrankungen zu einem einzigen Komorbiditätsindex zusammen, um die Gesamtbelastung durch Krankheiten pro Patient leichter abbilden zu können.
Ein KI‑Modell darin schulen, Frühwarnzeichen zu erkennen
Mit den geordneten Daten stellten die Forschenden eine konkrete Frage: Lässt sich auf Basis all dieser Informationen vorhersagen, wer innerhalb von sechs Monaten nach dem Eingriff sterben wird? Nur 41 der 638 Patientinnen und Patienten verstarben innerhalb dieses Zeitraums, was das Vorhersageproblem besonders schwierig macht – es gibt deutlich mehr Überlebende als Todesfälle, und viele Modelle neigen dazu, seltene, aber entscheidende Hochrisikofälle zu übersehen. Das Team nutzte zunächst ein Merkmalsauswahlverfahren, um 30 der informativsten Variablen über den gesamten Patientinnen‑ und Patientenverlauf hinweg auszuwählen. Dazu gehörten Faktoren wie Alter, Body‑Mass‑Index, Komorbiditätslast, bestimmte Blutwerte, Operationsdetails wie die Verweildauer von Instrumenten und Nachsorgekennzahlen wie Nieren‑ und Leberfunktion sowie Alltagsfähigkeiten.
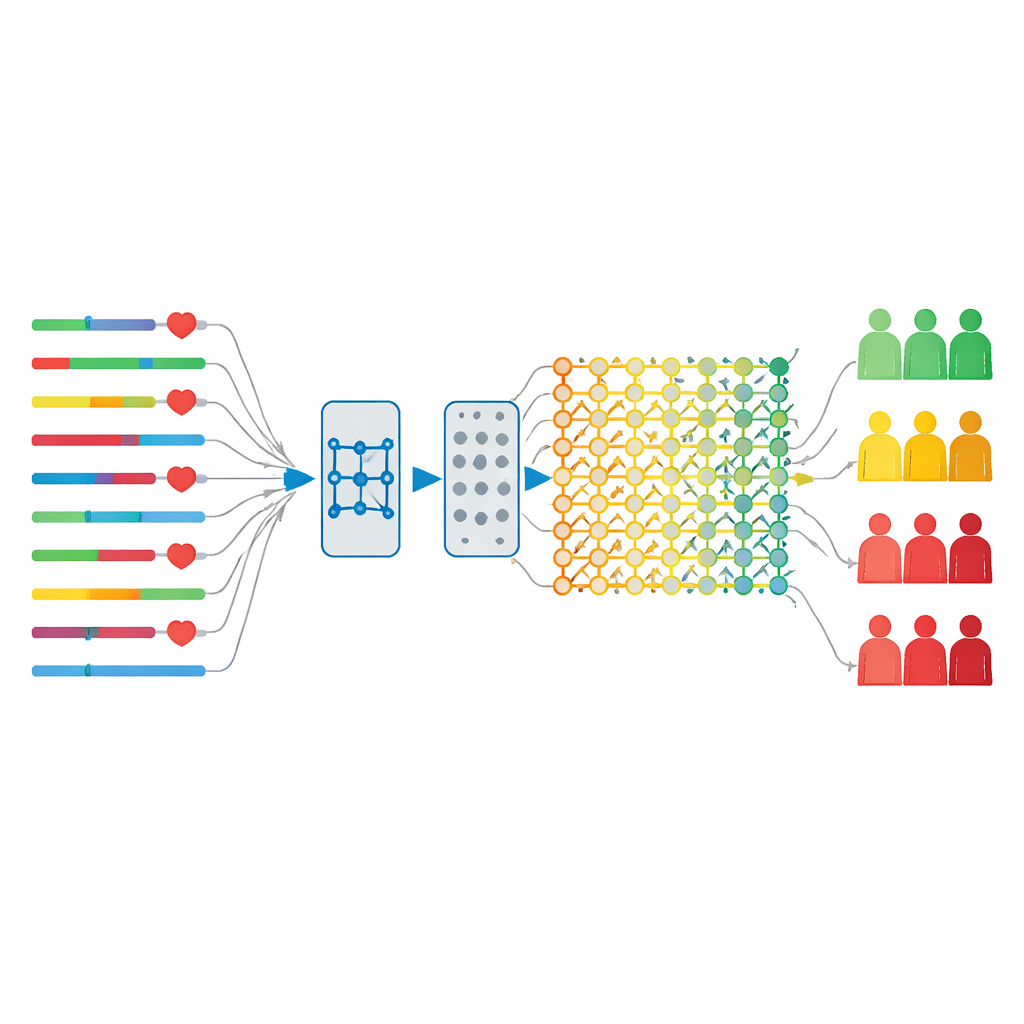
Ein hybrider KI‑Motor für Geschwindigkeit und Genauigkeit
Zur Analyse dieser zeitabhängigen Daten entwarfen die Forschenden ein hybrides Modell, das zwei KI‑Techniken kombiniert. Das erste, als Long Short‑Term Memory‑Netzwerk bekannt, eignet sich gut, um zeitliche Muster nachzuverfolgen – etwa wie sich Laborwerte vor und nach der Operation verändern –, kann aber allein eingesetzt langsam werden und zu Overfitting neigen. Das zweite, ein Broad Learning System, baut schnell Verknüpfungen zwischen Merkmalen auf, ohne die aufwändige Gewichtsanpassung tiefer Netze. In ihrem Aufbau durchlaufen die Lebenszyklusdaten der Patientinnen und Patienten zunächst den zeitbewussten Teil des Modells, dann einen Regularisierungsschritt zur Reduktion von Overfitting und schließlich die Broad‑Learning‑Schicht, die rasch die Endvorhersage berechnet. Diese Struktur bewahrt die Stärken des Deep Learning und mildert dessen Schwächen.
Was die Ergebnisse für die klinische Praxis bedeuten
Im Vergleich mit drei gängigen neuronalen‑Netz‑Ansätzen zeigte das hybride Modell die beste Leistung. Es klassifizierte Patientinnen und Patienten korrekt zu etwa 87 %, und wichtig: Es identifizierte mehr als 93 % derjenigen, die innerhalb von sechs Monaten tatsächlich verstarben – ein entscheidender Vorteil, wenn das Ziel ist, Hochrisikopersonen nicht zu übersehen. Konkret bedeutet das: Durch die Organisation von Krankenhausdaten in einer spezialisierten Datenbank für Herzinterventionen und deren Auswertung mit einem maßgeschneiderten KI‑Modell können Ärztinnen und Ärzte frühere und verlässlichere Warnungen erhalten, welche Patientinnen und Patienten nach dem Eingriff besondere Aufmerksamkeit benötigen. Auch wenn die Studie aus einem einzigen Krankenhaus stammt und in anderen Zentren noch validiert werden muss, weist sie in Richtung einer Zukunft, in der intelligenter Datengebrauch und spezialisierte Vorhersagewerkzeuge Herzinterventionen sicherer und die Erholung verlässlicher machen.
Zitation: Qi, P., Hu, C., Li, Y. et al. Study on establishment of cardiovascular interventional disease database and prediction of postoperative mortality risk. Sci Rep 16, 12493 (2026). https://doi.org/10.1038/s41598-026-39788-7
Schlüsselwörter: kardiovaskuläre Intervention, postoperatives Risiko, Sterblichkeitsvorhersage, medizinische Datenbanken, Künstliche Intelligenz im Gesundheitswesen