Clear Sky Science · fr
Détection de petites cibles d'objets flottants dans les chenaux fluviaux basée sur un YOLOv7 amélioré
Pourquoi repérer les petits déchets dans les rivières est important
Les rivières et canaux transportent souvent de petites pièces de détritus — bouteilles, feuilles, fragments de plastique — qui sont difficiles à voir mais peuvent causer de graves problèmes aux écosystèmes, à la sécurité face aux crues et aux infrastructures humaines. Les drones et caméras fixes promettent une surveillance continue, mais même des programmes avancés ont du mal à distinguer ces petits objets rapides à la surface d'une eau scintillante et en perpétuel mouvement. Cette étude présente une nouvelle façon d’apprendre aux ordinateurs à trouver ces petits éléments flottants dans des scènes fluviales de manière plus précise et plus rapide, ouvrant la voie à des cours d’eau plus propres et à des opérations plus sûres.
Le défi d’observer à travers une eau en mouvement
En regardant une rivière en vidéo, l’œil humain repère rapidement les débris flottants, même si le soleil miroite à la surface et que les vagues ondulent de façon imprévisible. Pour un ordinateur, c’est beaucoup plus difficile. Les formes des petites cibles changent lorsqu’elles tanguent sur l’eau, les reflets imitent des objets lumineux et les ombres peuvent dissimuler des éléments peu visibles. Les systèmes de détection classiques dessinent des boîtes autour de tout ce qui pourrait être un objet dans chaque image vidéo, mais ces boîtes bougent et scintillent d’une image à l’autre. Cette instabilité gaspille des ressources de calcul et rend facile la perte de vue d’objets de petite taille. Le résultat est un mélange de détections manquées, de fausses alertes et de traitements lents, en particulier lorsque des milliers d’images doivent être analysées en temps réel.
Une façon plus intelligente d’accorder ce qui est réellement présent
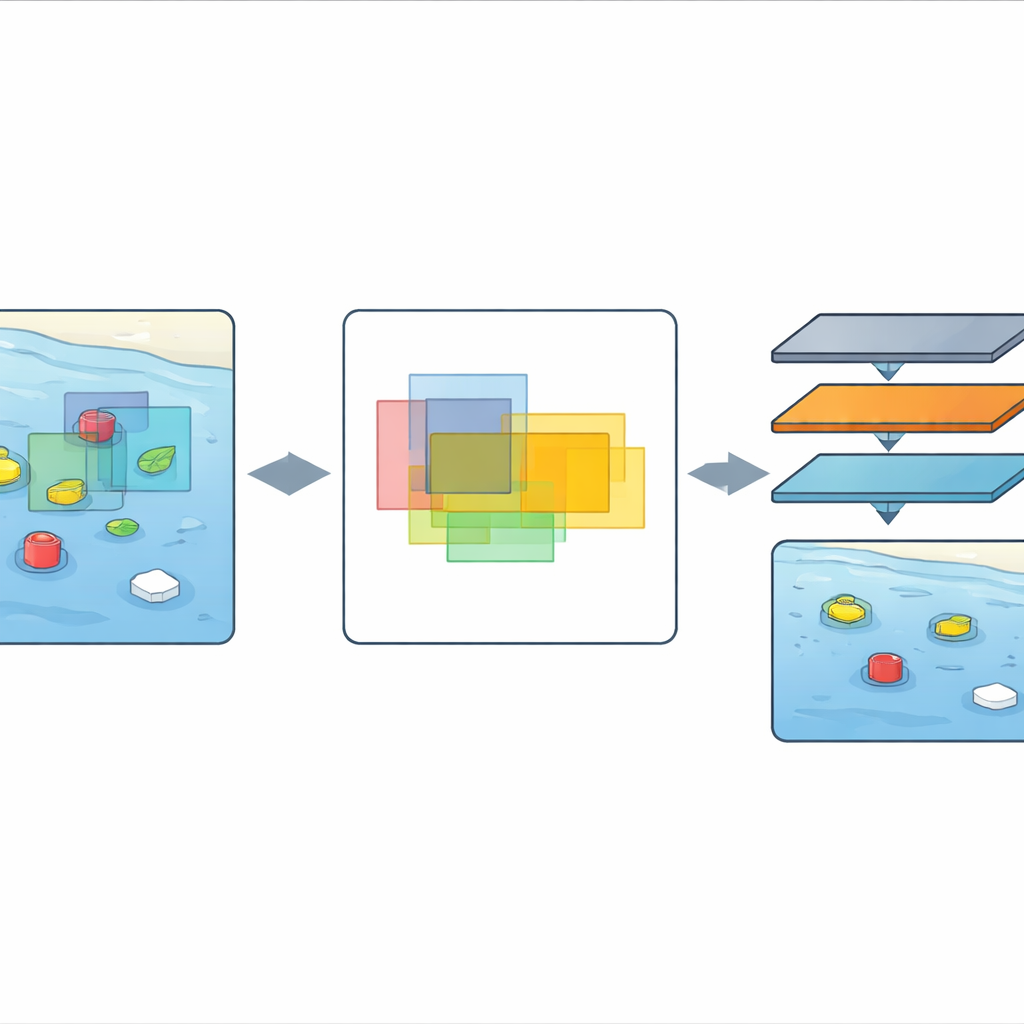
Les auteurs proposent un nouveau cadre appelé « Region-Overlap Detection » combiné à une version allégée d’un détecteur populaire connu sous le nom de YOLOv7. Plutôt que de traiter chaque image séparément, le système examine plusieurs images consécutives et pose une question simple : où les boîtes se superposent-elles dans le temps ? Les zones où les boîtes se chevauchent de manière consistante sont considérées comme plus fiables que celles qui n’apparaissent que brièvement ou qui sautillent. En se concentrant d’abord sur cette région de chevauchement stable, la méthode filtre de nombreuses hypothèses bruitées et instables concernant la position possible d’un objet. Seules les boîtes les plus fiables sont transmises dans la chaîne pour une analyse plus approfondie, donnant au système une vue plus nette et plus stable de la scène avant d’effectuer des calculs intensifs.
Faire plus avec moins d’étapes réseau
Les systèmes de vision modernes reposent souvent sur de profondes piles de couches de traitement qui apprennent à reconnaître formes, contours et textures. Bien que puissantes, ces couches sont coûteuses en exécution et peuvent diluer les signaux subtils émis par de petits objets. La nouvelle méthode conserve l’idée générale de YOLOv7 mais utilise délibérément moins de ces étapes de traitement, en les activant uniquement là où l’analyse basée sur le chevauchement suggère la présence d’un véritable objet. Les couches qui verraient majoritairement de l’eau de fond ou du bruit aléatoire sont ignorées. Cette stratégie de « convolution minimale » réduit le volume total de calcul tout en préservant les contours nets autour des petits éléments flottants. En pratique, le réseau concentre ses efforts là où cela compte le plus, plutôt que de traiter chaque pixel de la même manière.
Évaluer la méthode sur de vraies rivières
Pour mesurer l’efficacité de cette approche en conditions réelles, l’équipe l’a entraînée et testée sur des vidéos de drones prises au-dessus de rivières réelles, en utilisant un large jeu de données de milliers d’images annotées contenant près de quarante mille objets flottants de tailles variées. Ils ont également vérifié les performances sur des jeux de données publics additionnels et de longues séquences vidéo fluviales avec variations de lumière, de débit et d’angles de vue. Comparé à l’YOLOv7 d’origine et à plusieurs détecteurs récents, le nouveau système a retrouvé plus d’objets réels, en a manqué moins et a analysé les images plus rapidement. L’étude rapporte une moyenne de précision (mAP) supérieure à 73 % et un rappel supérieur à 70 % pour les petits objets flottants, ainsi qu’un gain notable en vitesse de traitement et une réduction du nombre de paramètres et d’opérations réseau nécessaires.
Ce que cela signifie pour des voies d’eau plus propres et plus sûres
En termes simples, l’article montre que stabiliser ce que l’ordinateur « croit voir » à travers les images, puis réduire les traitements inutiles, améliore fortement la détection des petits débris se déplaçant sur des surfaces d’eau agitées. Bien que la méthode doive encore être testée sur une gamme plus large de rivières et de conditions, elle surpasse déjà plusieurs modèles bien connus sur des scènes fluviales difficiles. Cela en fait un composant prometteur pour des systèmes de surveillance en temps réel montés sur drones, ponts ou stations riveraines. De tels systèmes pourraient aider les villes et les agences environnementales à suivre les déchets, gérer les risques d’inondation et réagir rapidement aux événements de pollution, transformant des flux vidéo bruts en informations fiables et exploitables.
Citation: Yang, W., Zhang, B., Guo, S. et al. Small target detection of floating objects in river channels based on improved YOLOv7. Sci Rep 16, 11423 (2026). https://doi.org/10.1038/s41598-026-40688-z
Mots-clés: détection de déchets fluviaux, surveillance de rivières par drone, détection de petits objets, vision par ordinateur pour milieux aquatiques, améliorations de YOLOv7