Clear Sky Science · es
SynthEHR-eviction: mejorando la detección de la SDoH de desahucio con datos EHR sintéticos aumentados por LLM
Por qué los problemas de vivienda deben constar en los historiales médicos
Ser expulsado de la propia vivienda puede devastar la salud, pero la mayoría de los sistemas médicos apenas detectan cuando ocurre. Este artículo describe una nueva manera de enseñar a la inteligencia artificial a identificar señales de desahucio y luchas sociales relacionadas dentro de las anotaciones de los médicos. Al convertir una pequeña cantidad de trabajo experto en un gran conjunto de entrenamiento realista, el enfoque podría ayudar a los sistemas de salud a detectar a las personas en riesgo antes y conectarlas con apoyo de vivienda y servicios sociales.
Cuando perder un hogar perjudica la salud
El desahucio es mucho más que un cambio de dirección. Está ligado a la falta de vivienda, el desempleo, la depresión e incluso tasas de mortalidad más altas, con impactos especialmente graves en grupos marginados y durante crisis como la pandemia de COVID-19. Sin embargo, en los registros electrónicos de salud actuales, la información sobre pérdida de vivienda o amenazas de desahucio suele aparecer solo en notas de texto libre, no en casillas o códigos estándar. Eso dificulta que hospitales, investigadores y responsables de políticas vean dónde ocurren los desahucios, quiénes son los más afectados y cuándo intervenir.
Construyendo historias de pacientes “sintéticas” realistas
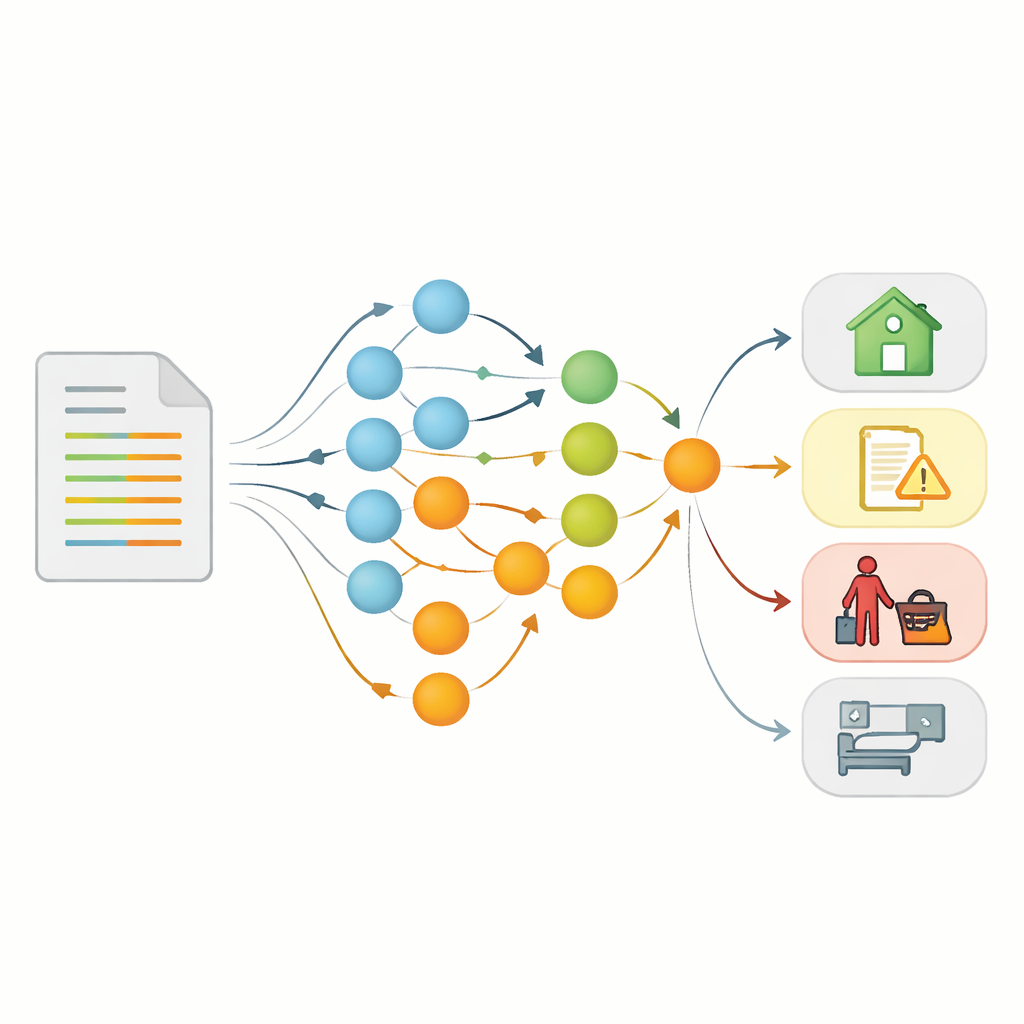
Dado que las notas médicas reales que mencionan claramente el desahucio son escasas y sensibles, los autores crearon una canalización llamada SynthEHR‑Eviction para generar ejemplos realistas pero totalmente sintéticos. Partieron de secciones de historial social de notas de alta hospitalaria reales y usaron grandes modelos de lenguaje —sistemas de IA entrenados con colecciones masivas de texto— para reescribirlas de modo que cada nota reflejara una situación habitacional o social específica. Los expertos definieron cuidadosamente 14 categorías, incluyendo etapas detalladas del desahucio como “pendiente”, “acuerdo mutuo para finalizar un contrato de alquiler” y “desahucio pasado vs. actual”, así como problemas relacionados como la falta de vivienda, la inseguridad alimentaria y dificultades para pagar facturas. Mediante un proceso iterativo con intervención humana, los clínicos revisaron muestras de salida, señalaron errores y proporcionaron retroalimentación estructurada al proceso de prompting hasta que cada “aumentador” de IA produjo notas de alta precisión y mínima ambigüedad. El resultado fue un gran conjunto de datos público que contiene 8.000 notas sintéticas de entrenamiento más de 600 notas de prueba cuidadosamente etiquetadas que mezclan casos sintéticos con ejemplos reales desidentificados extraídos de grandes bases de datos de investigación.

Enseñar a las máquinas a leer entre líneas
Sobre estas historias sintéticas, el equipo construyó un sistema de anotación automatizado que no solo asigna una categoría, sino que también produce una explicación paso a paso de su razonamiento. Usando un marco llamado DSPy, optimizaron los prompts para que la IA primero decida si una nota trata sobre desahucio o no, y luego la dirija ya sea a un clasificador detallado de desahucio o a un clasificador de otros riesgos sociales como transporte o inseguridad alimentaria. Este diseño refleja cómo un lector humano podría primero preguntarse “¿Se menciona el desahucio?” y solo después clasificar el caso en categorías más específicas. Para reducir el trabajo manual, los investigadores compararon la reescritura y el etiquetado humanos completos de 8.000 notas —más de 260 horas de trabajo— con su flujo de trabajo asistido por IA, que alcanzó una calidad de datos comparable con menos de seis horas de tiempo experto, una reducción del 80%.
Qué tan bien rinden los modelos
Armados con SynthEHR‑Eviction, los autores ajustaron una variedad de modelos de lenguaje de código abierto y los compararon con sistemas comerciales y modelos biomédicos anteriores. Para la tarea simple de decidir si se mencionaba el desahucio, muchos modelos funcionaron bien, pero los grandes modelos afinados y una variante afinada de GPT‑4 alcanzaron las puntuaciones más altas. La prueba más dura fue distinguir entre siete estados matizados de desahucio y un conjunto separado de riesgos sociales no asociados a desahucio en tres conjuntos de datos: notas sintéticas, notas hospitalarias reales e informes de casos académicos extensos. Aquí, modelos abiertos afinados como Qwen2.5 y LLaMA‑3 igualaron o superaron ligeramente el rendimiento de GPT‑4 optimizado, alcanzando puntuaciones macro‑F1 —un equilibrio general entre precisión y exhaustividad— alrededor de 0,89 para desahucio y por encima de 0,90 para otros riesgos sociales. Modelos más pequeños con solo tres mil millones de parámetros también rindieron bien una vez afinados, lo que sugiere que se pueden desplegar sistemas capaces y asequibles en entornos con potencia informática limitada.
Por qué las trazas de razonamiento y los datos reales siguen siendo importantes
El estudio revela que las explicaciones ayudan a algunos modelos más que a otros. Cuando los datos de entrenamiento incluían razonamientos breves y explícitos sobre por qué una nota señalaba cierto estado de desahucio, los modelos más pequeños mejoraron notablemente, mientras que los más grandes cambiaron poco, lo que sugiere que ya codificaban gran parte de esa lógica. Estas trazas de razonamiento también facilitan la revisión experta de las decisiones del modelo, aunque los autores advierten que las explicaciones no siempre son perfectamente fieles a cómo el modelo toma realmente la decisión. Otro hallazgo clave es que los modelos entrenados solo con notas sintéticas tropiezan ante la escritura desordenada del mundo real. Mezclar simplemente una proporción modesta de notas hospitalarias reales o informes de casos mejoró de forma marcada el rendimiento en esos dominios, subrayando que los datos sintéticos son poderosos pero no suficientes por sí solos.
De un riesgo oculto a una ayuda visible
En conjunto, el artículo muestra que los datos sintéticos cuidadosamente construidos, combinados con supervisión experta dirigida, pueden convertir menciones dispersas de desahucio y otras penurias en señales estructuradas que las máquinas pueden detectar a escala. En términos sencillos, el sistema aprende a leer entre líneas de las notas médicas y señalar cuando un paciente está enfrentando o ha afrontado la pérdida de vivienda u otras tensiones sociales relacionadas. Si se integra en los registros electrónicos de salud, tales herramientas podrían ayudar a clínicos y trabajadores sociales a identificar a las personas en riesgo antes y conectarlas con ayuda de vivienda, asesoramiento financiero o apoyo de transporte. Al hacer más visible el lado social invisible de la enfermedad, SynthEHR‑Eviction ofrece una vía hacia una atención sanitaria que ve y responde a las circunstancias completas de la vida de los pacientes.
Cita: Yao, Z., Zhao, Y., Mitra, A. et al. SynthEHR-eviction: enhancing eviction SDoH detection with LLM-augmented synthetic EHR data. npj Digit. Med. 9, 292 (2026). https://doi.org/10.1038/s41746-026-02473-0
Palabras clave: desahucio, determinantes sociales de la salud, registros electrónicos de salud, datos sintéticos, procesamiento de lenguaje natural clínico