Clear Sky Science · de
UTR-DynaPro: ein CNN–Transformer multimodales Sprachmodell zur Entschlüsselung regulatorischer Mechanismen der 5′UTR
Wie die Vorderseite der RNA Leben und Medizin formt
Die Anweisungen zum Aufbau von Proteinen in unseren Zellen stehen in Boten-RNA-Strängen, doch nicht jeder Teil dieses Strangs wird als Protein abgelesen. Ein Abschnitt ganz am Anfang, die 5′-untranslatierte Region, fungiert eher wie ein Regelknopf als wie ein Bauplan. Kleine Veränderungen dort können dramatisch beeinflussen, wie viel Protein hergestellt wird — mit Folgen von der Wirksamkeit eines Impfstoffs bis dazu, ob eine Gentherapie genug eines heilenden Proteins liefert. Diese Arbeit stellt ein neues KI-Modell vor, UTR-DynaPro, das diesen Regelknopf genauer lesen und interpretieren soll als frühere Methoden.
Die stille Schaltzone vor dem Code
Bevor der proteincodierende Teil einer mRNA beginnt, trägt die 5′-untranslatierte Region (5′UTR) zur Entscheidung bei, wie effizient ein Protein produziert wird. Ihre Sequenz und Struktur beeinflussen, ob die zellulären Proteinfabriken, die Ribosomen, ansetzen, entlangscannen und glatt mit der Arbeit beginnen können. Merkmale wie die Länge der Region, das Verhältnis der Basen A, U, G und C sowie das Vorhandensein kleiner upstream-Startsignale können Prozesse beschleunigen oder verlangsamen. Diese Effekte sind in der Praxis bedeutsam: Bei mRNA-Impfstoffen kann eine feinabgestimmte 5′UTR stärkere Immunantworten mit geringeren Dosen ermöglichen; bei genetischen Erkrankungen kann eine störende Veränderung dort die Proteinproduktion stark reduzieren, selbst wenn der Hauptgen-Code intakt ist.
Warum alte Vorhersagewerkzeuge an Grenzen stoßen
Forscher haben tiefes Lernen eingesetzt, um vorherzusagen, wie sich eine gegebene 5′UTR verhält, in der Hoffnung, Sequenzen zu entwerfen, die genau die richtige Menge Protein produzieren. Frühere Modelle konzentrieren sich jedoch oft entweder auf sehr kurze Muster oder auf breit angelegte, langreichweitige Beziehungen — selten beides zugleich. Manche haben Schwierigkeiten, sich anzupassen, wenn sich experimentelle Bedingungen zwischen Zelltypen oder Laborprotokollen ändern, und viele vernachlässigen wichtige Zusatzinformationen wie die Faltungsenergie der RNA oder die Länge des proteincodierenden Abschnitts. Infolgedessen stagniert ihre Genauigkeit, was unsere Fähigkeit einschränkt, 5′UTRs systematisch für Impfstoffe, Gentherapien und industrielle Proteinproduktion zu designen.
Ein zweigleisiger Leser für RNA-Signale
UTR-DynaPro schließt diese Lücken, indem es zwei komplementäre Lesarten der 5′UTR kombiniert. Ein Pfad, der auf konvolutionalen Netzwerken basiert, ist darauf ausgerichtet, kurze, lokale Muster zu erkennen — vergleichbar mit wiederkehrenden „Wörtern“ in der RNA, die als Ein-/Ausschalter wirken. Der andere Pfad, aufgebaut aus Transformer-Schichten, ist hervorragend darin, langreichweitige Interaktionen aufzuspüren, beispielsweise wie entfernte Abschnitte der Kette zusammenfalten oder mit dem anschließenden codierenden Bereich koordinieren. Ein dynamisches „Tor“ entscheidet dann positionsweise entlang der RNA, wie stark lokaler gegenüber globalem Informationsgehalt gewichtet wird. Darüber hinaus integriert das Modell zusätzliche Signale, darunter wie stark die RNA zur Faltung neigt, die Länge des proteincodierenden Segments und das Vorhandensein bestimmter kleiner upstream-Reading-Frames. Zusammen erlauben diese Bausteine UTR-DynaPro, ein reiches Bild davon zu zeichnen, wie eine 5′UTR wahrscheinlich die Proteinproduktion steuert.
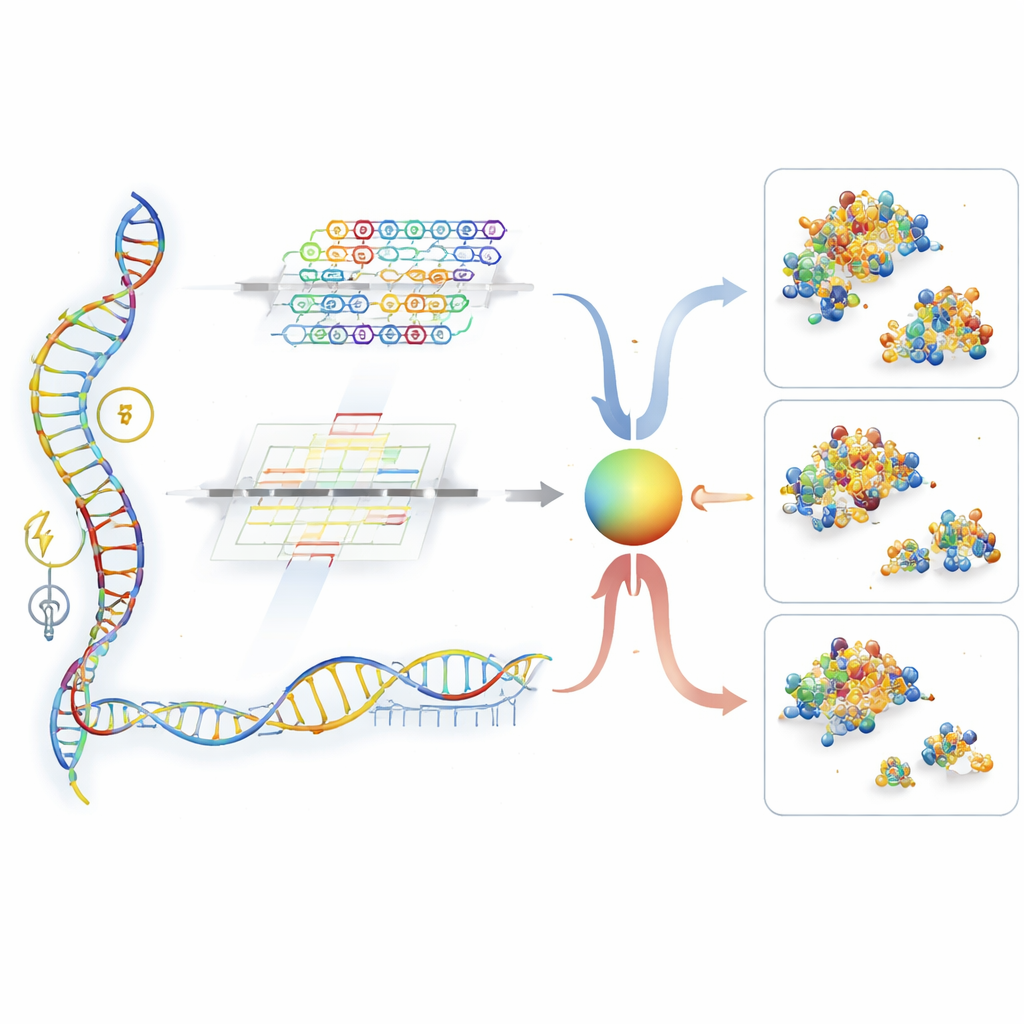
Das Modell auf die Probe gestellt
Die Autoren trainierten und evaluierten UTR-DynaPro an großen, vielfältigen Datensätzen: synthetische und natürliche 5′UTRs von Menschen und anderen Arten sowie Messungen aus mehreren menschlichen Zelltypen und Geweben. Sie konzentrierten sich auf drei verwandte Zielgrößen: mittlere Ribosomenbeladung (wie viele Ribosomen sich im Schnitt auf einer mRNA ansammeln), Translationseffizienz (wie viel Protein pro RNA-Molekül produziert wird) und das GesamtExpressionsniveau. In all diesen Aufgaben übertraf das neue Modell konstant mehrere führende Ansätze und reduzierte die Vorhersagefehler in manchen Fällen um nahezu zehn Prozent. Sorgfältige „Ablations“-Tests — das Entfernen oder Vereinfachen von Architekturteilen — zeigten, dass jede Hauptkomponente, vom Zwei-Pfad-Design über die Mixture-of-Experts-Submodule bis hin zu den Eingaben für experimentelle Bedingungen, die Leistung messbar verbesserte. Die Visualisierung des Fusions-Tors offenbarte zudem, dass das Modell seine Abhängigkeit von lokalen und globalen Hinweisen entlang der Sequenz und zwischen Zelltypen verschiebt, was der komplexen biologischen Logik in diesem Bereich entspricht.
Von besseren Vorhersagen zu besseren Designs
Für Nicht-Fachleute ist die zentrale Aussage, dass diese Arbeit eine leistungsfähigere und flexiblere Möglichkeit bietet, die subtilen Kontrollanweisungen am Anfang einer mRNA zu lesen. Indem sie genauer vorhersagt, wie eine Veränderung in der 5′UTR die Proteinmenge beeinflusst, kann UTR-DynaPro das Design synthetischer Sequenzen leiten, die Produktion für spezifische Bedürfnisse steigern oder feinjustieren — stärkere Impfstoffe, sicherere Gentherapien oder bessere industrielle Enzyme. Gleichzeitig hilft die interpretierbare Architektur Forschern, sowohl bekannte als auch zuvor verborgene Regulationsmuster zu entdecken. Praktisch bringt uns dieses Modell näher daran, die 5′UTR als programmierbaren Regelknopf für Genexpression zu betrachten, den man mit Zuversicht statt durch Versuch und Irrtum drehen kann.
Zitation: Shen, H., Liu, S., Guo, F. et al. UTR-DynaPro: a CNN–transformer multimodal language model for decoding 5′UTR regulatory mechanisms. Sci Rep 16, 10779 (2026). https://doi.org/10.1038/s41598-026-42175-x
Schlüsselwörter: 5′UTR-Regulation, mRNA-Translation, Deep Learning für Biologie, Genexpressionskontrolle, mRNA-Impfstoff-Design