Clear Sky Science · zh
一种用于巴哈里亚地层注水采油设计优化的混合仿真—机器学习代理模型
为什么在油田更聪明地使用水很重要
把油藏中最后的油滴挤出来通常意味着向岩石注入水,把油驱向生产井。这一过程称为注水采油,应用广泛但远非完美:在错误位置注入过多的水会让有价值的油留在地下,并产生大量废水。本研究展示了如何将传统的基于物理的数值模拟与现代机器学习相结合,帮助工程师在一个特别复杂的埃及油田中设计更聪明的注水方案,通过更少的计算试错运行回收更多石油。
一个棘手的地下谜题
埃及西部沙漠的巴哈里亚地层并不是一种整齐、均匀的岩石海绵。相反,它由古河流与三角洲沉积构成,砂岩与页岩层以不规则的模式交织在一起。这种拼接体造成了流体易于流动的通道,也存在使石油被困的死角。钻井获得的数据有限,很难详细描述这个地下迷宫。传统的油藏模拟器可以为此建模,但要做得彻底需要数千次耗时、计算密集的运行——对于现场日常决策来说太多了。
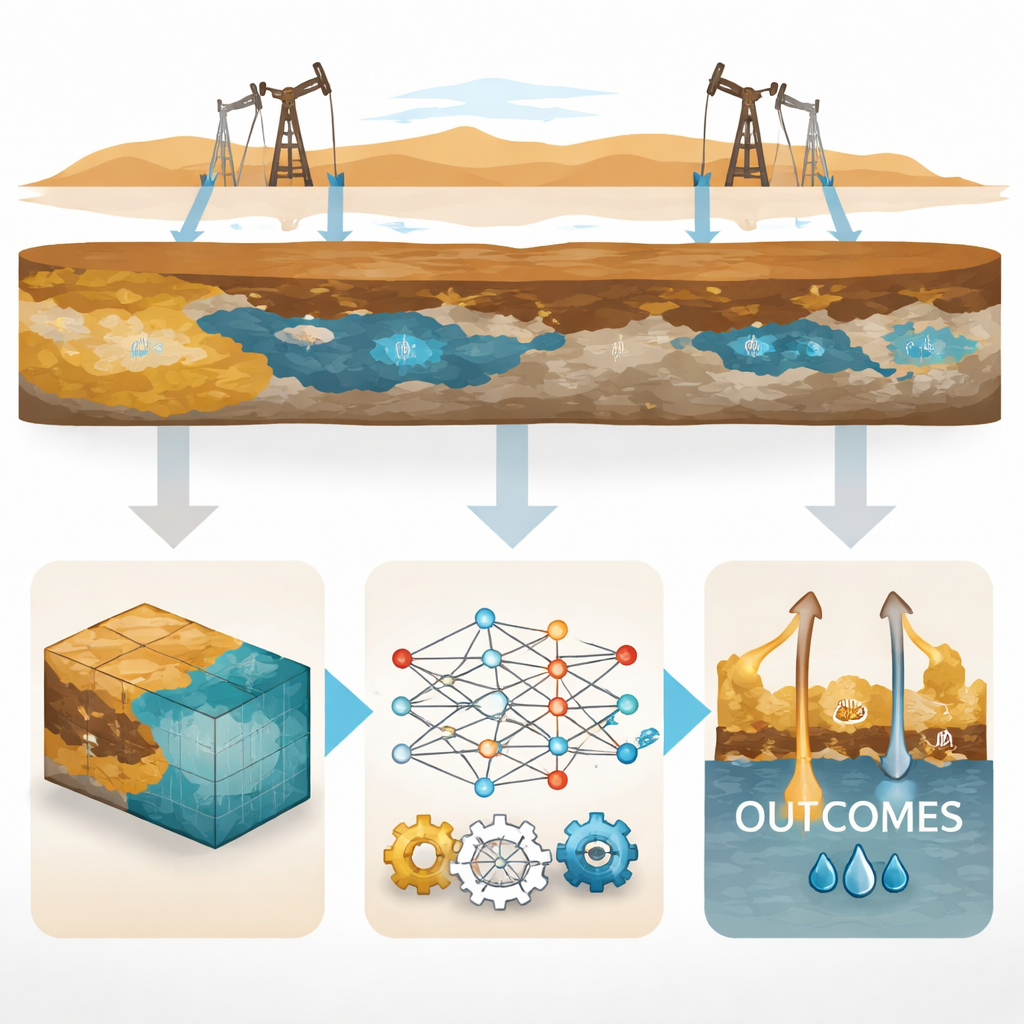
将物理模型与数据驱动学习融合
作者利用地质和岩石物性信息(如岩石质量、孔隙结构和流体性质)建立了详细的三维数值油藏模型。他们随后设计了一大组“假设情形”——总计1,536个——通过改变关键因素来生成这些情形,例如注水速率、岩石中水的可倾向流动性、注水后残留的油量以及油的轻重等。对每个情形,他们测试了三种常用的注采井布置:注入井位于生产井包围中的五点格局、交错的线驱格局以及主要在油田边缘注水的周边方案。模拟器报告每种情况下最终可以回收的油量。
教会一个快速代理去模仿模拟器
研究团队没有永远依赖缓慢的模拟器,而是训练了简单的机器学习模型——具体来说是线性回归——来学习可变输入与每种井网最终采收率之间的关系。这些模型充当“代理”:一旦训练完成,就能在不到一秒的时间内预测采收率。研究人员谨慎地将数据分为训练集和测试集,并在多个划分上检验性能。对三种井网,模型都高保真地复现了模拟器的结果,解释了超过93%的采收率变异,并保持很小的预测误差。实际上,繁重的基于物理的模拟器被提炼为轻量的方程,但仍以物理上合理的方式运行。
真正控制产油量的因素是什么
借助这些快速代理模型,作者探查了哪些因素最重要。通过依次轻微扰乱每个输入并观察预测性能如何恶化,他们发现注水后岩石中残留的油量——称为残余油饱和度——远远是主导因素,在所有井网中几乎贡献了近40%或更多的预测能力。油的质量也很重要:轻质油更易流动,能提高采收率,而那些允许水过于容易流动的岩层往往会导致早期水突破并降低扫替效率。有趣的是,注入速率的重要性强烈依赖于井网模式。在周边方案中,注水强度的影响远大于网格状的五点布置,这表明不同的井位安排对不同的控制变量有不同的响应。
从计算机洞见到现场决策
综合这些部分,研究表明不存在普遍适用的最佳注水模式。在所模拟的巴哈里亚油田中,周边布置带来了最高的最终采收率,其次是交错线驱,最后是五点格局。但这种排序仅在考虑到该油藏特定的岩石构造和流体性质后才会显现。该混合工作流程——用模拟产生数据,再用机器学习快速分析——为现场工程师提供了一种实用方法,能筛选众多注水选项、识别真正重要的参数,并在不运行成千上万次完整模拟的情况下调整注水策略。对普通读者而言,结论很简单:让计算机既遵循物理规律又从数据中学习,运营方就能在同样的岩层中回收更多油,同时更高效地使用水与计算资源。
引用: Gad, R., Salem, A.M., El Farouk, O.M. et al. A hybrid simulation-machine learning proxy model for waterflood design optimization in the Bahariya Formation. Sci Rep 16, 14023 (2026). https://doi.org/10.1038/s41598-026-49561-5
关键词: 注水采油, 机器学习, 采油率, 油藏数值模拟, 巴哈里亚地层